Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Faktorielle ANOVA 3: unbalancierte Designs
Die faktorielle ANOVA ist eine Analysemethode, über die man Bescheid wissen sollte. Sie gehört seit vielen Jahrzehnten zu den Standardinstrumenten für die Analyse experimenteller Daten. Sie werden feststellen, dass Sie kaum mehr als zwei oder drei Artikel in der Psychologie lesen können, ohne auf eine ANOVA zu stoßen. Es gibt jedoch einen großen Unterschied zwischen den ANOVAs, die Sie in den meisten wissenschaftlichen Artikeln finden, und den ANOVAs, die ich bisher beschrieben habe. Im wirklichen Leben haben wir selten das Glück, perfekt balancierte Designs zu haben. Aus verschiendenen Gründen ist es eher typisch, dass man in einigen Zellen mehr Beobachtungen hat als in anderen. Oder anders ausgedrückt, wir haben ein unbalanciertes Design.
Unbalancierte Designs erfordern viel mehr Sorgfalt als balancierte Designs, und die statistische Theorie, die ihnen zugrunde liegt, ist viel unübersichtlicher. Vielleicht liegt es an dieser Unübersichtlichkeit, vielleicht ist aber auch Zeitmangel der Grund dafür, dass in Lehrveranstaltungen zu Forschungsmethoden in der Psychologie die unangenehme Tendenz besteht, dieses Thema völlig zu ignorieren. Viele Statistik-Lehrbücher neigen ebenfalls dazu, dieses Thema zu übergehen. Das Ergebnis ist meiner Meinung nach, dass viele Forscher nicht wissen, dass es verschiedene „Arten“ von unbalancierten ANOVAs gibt, die zu ganz unterschiedlichen Ergebnissen führen können. Wenn ich die psychologische Literatur lese, bin ich erstaunt darüber, dass die meisten Leute, die über die Ergebnisse einer unbalancierten faktoriellen ANOVA berichten, oft nicht genug Details angeben, um die Analyse zu reproduzieren oder zu verstehen. Insgeheim habe ich den Verdacht, dass die meisten Leute nicht einmal wissen, dass ihr statistisches Softwarepaket eine ganze Reihe von wichtigen Entscheidungen bei der Datenanalyse für sie trifft. Wenn man darüber nachdenkt, ist das schon ein wenig erschreckend. Wenn Sie also vermeiden wollen, die Kontrolle über Ihre Datenanalyse an Ihre Software abzugeben, lesen Sie weiter.
Der Kaffee-Datensatz
Wie üblich wird es uns helfen, mit einigen Daten zu arbeiten. Der coffee-Datensatz enthält hypothetische Daten für eine unbalancierte 3 × 2 ANOVA. Nehmen wir an, wir wollen herausfinden, ob die Tendenz der Leute, viel zu reden (babble), wenn sie viel Kaffee trinken, nur eine Auswirkung des Kaffees selbst ist, oder ob es auch eine Auswirkung von milk und sugar gibt, welche die Leute dem Kaffee hinzufügen. Nehmen wir an, wir haben 18 Personen Kaffee zu trinken gegeben. Die Menge an Kaffee (d.h. an Koffein) wurde konstant gehalten, während wir variierten, ob Milch hinzugefügt wurde oder nicht. milk ist also ein binärer Faktor  mit zwei Stufen,
mit zwei Stufen, yes und no. Wir haben auch die Art des Zuckers variiert: Der Kaffee kann echten Zucker (real), Süßstoff (fake) bzw. keinen Zucker (none) enthalten. Die Variable sugar ist daher ein dreistufiger Faktor . Unsere Ergebnisvariable babble ist eine kontinuierliche Variable  , die sich vermutlich auf ein psychologisch sinnvolles Maß des Ausmaßes bezieht, in dem jemand „plappert“. Die Details sind für unseren Zweck nicht wirklich wichtig. Werfen Sie einen Blick auf die jamovi-Datentabelle, die in Abb. 169 gezeigt wird.
, die sich vermutlich auf ein psychologisch sinnvolles Maß des Ausmaßes bezieht, in dem jemand „plappert“. Die Details sind für unseren Zweck nicht wirklich wichtig. Werfen Sie einen Blick auf die jamovi-Datentabelle, die in Abb. 169 gezeigt wird.
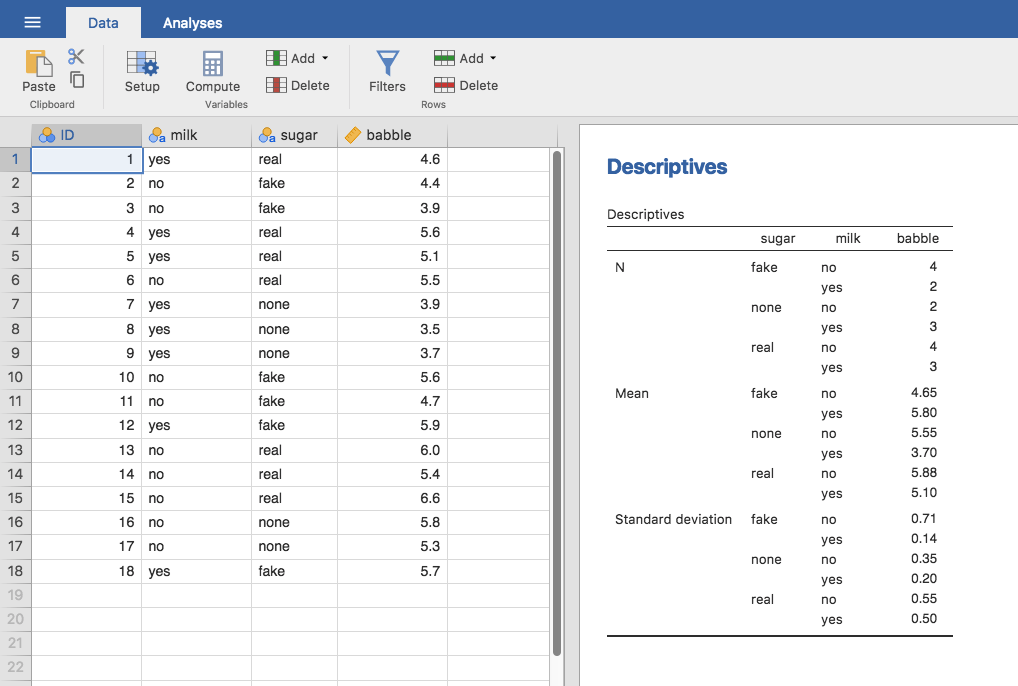
Abb. 169 Deskriptive Statistik für den coffee-Datensatz in jamovi, aggregiert nach den verschiedenen Ebenen der Faktoren sugar und milk
Betrachtet man die Tabelle der Mittelwerte in Abb. 169, so gewinnt man den Eindruck, dass es Unterschiede zwischen den Gruppen gibt. Dies gilt insbesondere, wenn wir diese Mittelwerte mit den Standardabweichungen für die Variable babble vergleichen. Über die Gruppen hinweg schwankt diese Standardabweichung zwischen 0,14 und 0,71, was im Vergleich zu den Unterschieden in den Gruppenmittelwerten recht gering ist.[1] Während dies auf den ersten Blick wie eine gewöhnliche faktorielle ANOVA aussehen mag, ergibt sich ein Problem, wenn wir uns ansehen, wie viele Beobachtungen wir in jeder Gruppe haben, reflektiert in den unterschiedlichen Ns für die verschiedenen Gruppen in Abb. 169. Dies verstößt gegen eine unserer ursprünglichen Annahmen, nämlich dass die Anzahl der Personen in jeder Gruppe gleich ist. Wir haben bisher nicht wirklich diskutiert, wie wir mit einer solchen Situation umgehen sollen.
Die „Standard-ANOVA“ existiert für unbalancierte Designs nicht
Unbalancierte Versuchsdesigns führen uns zu der etwas beunruhigenden Entdeckung, dass etwas, das wir als Standard-ANOVA bezeichnen könnten, nicht wirklich gibt. Stattdessen gibt es drei grundlegend verschiedene Möglichkeiten,[2] eine ANOVA in einem unbalancierten Design durchzuführen. Bei einem balancierten Versuchsdesign führen alle drei Möglichkeiten zu identischen Ergebnissen, wobei die Summen der Quadrate, F-Werte usw. genau den Formeln entsprechen, die ich zu zeitiger in diesem Kapitel angegeben habe. Bei einem unbalancierten Design liefern sie jedoch nicht die gleichen Ergebnisse. Außerdem sind sie nicht alle gleichermaßen für alle Situation geeignet. Einige Methoden werden für Ihre Situation besser geeignet sein als andere. Aus diesem Grund ist es wichtig zu verstehen, was die verschiedenen Arten von ANOVAs sind und wie sie sich voneinander unterscheiden.
Die erste Art der ANOVA beruht auf der Typ-1-Quadratsumme. Sie können sicher erraten, wie die anderen beiden genannt werden. Der „Quadratsumme“-Teil des Namens wurde vom Softwarepaket SAS eingeführt und ist zur Standardnomenklatur geworden, aber in gewisser Weise ist er etwas irreführend. Ich denke, die Logik für die Bezeichnung als verschiedene Arten von Quadratsummen ist, dass der Hauptunterschied, wenn man sich die ANOVA-Tabellen ansieht, die Zahlen für die SS-Werte sind, die sie erzeugen. Die Freiheitsgrade ändern sich nicht, die MS-Werte sind immer noch definiert als SS geteilt durch df usw. Was die Terminologie jedoch inkorrekt macht, ist, dass sie den Grund verbirgt warum sich die SS-Werte voneinander unterscheiden. Hierfür ist es viel hilfreicher, sich die drei verschiedenen Arten der ANOVA als drei verschiedene Hypothesenteststrategien vorzustellen. Diese verschiedenen Strategien führen zwar zu unterschiedlichen SS-Werten, aber die Strategie ist hier das Entscheidende, nicht die SS-Werte selbst. Erinnern Sie sich an den Abschnitt Die ANOVA als lineares Modell, wo beschrieben wurde, dass ein bestimmter F-Test am besten als Vergleich zwischen zwei linearen Modellen zu verstehen ist. Wenn man sich also eine ANOVA-Tabelle ansieht, ist es hilfreich, sich daran zu erinnern, dass jeder dieser F-Tests einem Paar von Modellen entspricht, die verglichen werden. Das führt natürlich zu der Frage, welches Modellpaar verglichen wird. Dies ist der grundlegende Unterschied zwischen den ANOVA- (bzw. Quadratsumme-)Typen 1, 2 und 3: Jeder dieser Typen entspricht einer anderen Art der Auswahl von Modellpaaren für die Tests.
Typ-1-Quadratsumme
Die Methode vom Typ 1 wird manchmal auch als „sequentielle“ Quadratsumme bezeichnet, da sie einen Prozess beinhaltet, durch welchen dem Modell ein Term nach dem anderen hinzugefügt wird. Betrachten wir zum Beispiel die coffee-Daten. Nehmen wir an, wir wollen die vollständige 3 × 2 faktorielle ANOVA durchführen, einschließlich der Interaktionsterme. Das vollständige Modell enthält die Ergebnisvariable babble, die Prädiktorvariablen sugar und milk sowie den Interaktionsterm sugar * milk. Dies kann als babble ~ sugar + milk + sugar * milk geschrieben werden. Bei der Typ-1-Strategie wird dieses Modell sequentiell aufgebaut, wobei mit dem einfachsten möglichen Modell begonnen und nach und nach weitere Terme hinzugefügt werden.
Das einfachste mögliche Modell für die Daten wäre eines, bei dem angenommen wird, dass weder Milch noch Zucker irgendeinen Einfluss auf die Redemenge haben. Der einzige Term, der in einem solchen Modell enthalten wäre, ist das Interzept, geschrieben als babble ~ 1. Dies ist unsere erste Nullhypothese. Das nächst einfachste Modell für die Daten wäre eines, in dem nur einer der beiden Haupteffekte enthalten ist. Bei den coffee-Daten gibt es hier zwei verschiedene Möglichkeiten, denn wir könnten wählen, ob wir zuerst Milch oder zuerst Zucker hinzufügen. Die Reihenfolge spielt tatsächlich eine Rolle, wie wir später sehen werden, aber für den Moment treffen wir einfach eine willkürliche Wahl und wählen Zucker. Das zweite Modell in unserer Reihe von Modellen ist also babble ~ sugar, und es bildet die Alternativhypothese für unseren ersten Test. Wir haben jetzt unseren ersten Hypothesentest:
Nullmodell: |
|
Alternativmodell: |
|
Dieser Vergleich bildet unseren Hypothesentest für den Haupteffekt von sugar. Der nächste Schritt in unserer Modellbildung besteht darin, den anderen Haupteffekt-Term hinzuzufügen, so dass das nächste Modell in unserer Sequenz babble ~ sugar + milk ist. Der zweite Hypothesentest wird dann durch den Vergleich des folgenden Modellpaares gebildet:
Nullmodell: |
|
Alternativmodell: |
|
Dieser Vergleich bildet unseren Hypothesentest für den Haupteffekt von milk. In gewissem Sinne ist dieser Ansatz sehr elegant: Die Alternativhypothese des ersten Tests bildet die Nullhypothese für den zweiten Test. In diesem Sinne ist die Methode vom Typ 1 streng sequentiell. Jeder Test baut direkt auf den Ergebnissen des vorherigen Tests auf. In einem anderen Sinne ist sie jedoch sehr unelegant, denn es besteht eine starke Asymmetrie zwischen den beiden Tests. Der Test auf den Haupteffekt von sugar (der erste Test) ignoriert milk vollständig, während der Test auf den Haupteffekt von milk (der zweite Test) sugar berücksichtigt. In jedem Fall ist das vierte Modell in unserer Sequenz dann das vollständige Modell, babble ~ sugar + milk + sugar * milk, und der entsprechende Hypothesentest lautet:
Nullmodell: |
|
Alternativmodell: |
|
Die Typ-3-Quadratsumme ist die Standardhypothesentestmethode, die von der ANOVA in jamovi verwendet wird. Um eine Typ-1-Quadratsumme-Analyse durchzuführen, müssen wir Type 1 im Auswahlfeld Sum of squares in den jamovi ANOVA → Model-Optionen auswählen. So erhalten wir die ANOVA-Tabelle, die in Abb. 170 gezeigt wird.

Abb. 170 ANOVA-Ergebnistabelle unter Verwendung von Typ-1-Quadratsumme in jamovi (mit dem coffee-Datensatz und einem gesättigten Modell mit den Faktoren sugar, milk, und deren Interaktion; der Faktor sugar wurde zuerst hinzugefügt).
Das große Problem bei der Verwendung von Quadratsummen des Typs 1 ist die Tatsache, dass das Ergebnis von der Reihenfolge abhängt, in der Sie die Faktoren zum Modell hinzufügen. In vielen Situationen hat der Forscher keinen Grund, eine Reihenfolge gegenüber einer anderen zu bevorzugen. Dies ist vermutlich bei unserem Milch- und Zuckerproblem der Fall. Sollen wir zuerst milk oder zuerst sugar hinzufügen? Als Frage der Datenanalyse erscheint sie genauso willkürlich wie als Frage des Kaffeekochens. Es mag tatsächlich Leute geben, die eine festgefügte Meinung über die „korrekte“ Reihenfolge haben, aber es ist schwer, sich eine prinzipielle Antwort auf diese Frage vorzustellen. Aber sehen Sie sich an, was passiert, wenn wir die Reihenfolge ändern, wie in Abb. 171.

Abb. 171 ANOVA-Ergebnistabelle unter Verwendung von Typ-1-Quadratsumme in jamovi (mit dem coffee-Datensatz und einem gesättigten Modell mit den Faktoren sugar, milk, und deren Interaktion; der Faktor milk wurde zuerst hinzugefügt).
Die p-Werte für beide Haupteffekt-Terme haben sich verändert, und zwar ziemlich dramatisch. Unter anderem ist der Effekt von milk signifikant geworden (obwohl man, wie bereits erwähnt, keine eindeutigen Schlüsse daraus ziehen sollte). Welche dieser beiden ANOVAs sollte man berichten? Das ist nicht sofort klar.
Wenn man sich die Hypothesentests ansieht, die zur Bestimmung des „ersten“ Haupteffekts und des „zweiten“ Haupteffekts verwendet werden, wird deutlich, dass sie sich qualitativ voneinander unterscheiden. In unserem ersten Beispiel haben wir gesehen, dass der Test für den Haupteffekt von sugar den Faktor milk vollständig ignoriert, während der Test für den Haupteffekt von milk den Faktor sugar berücksichtigt. Die Teststrategie vom Typ 1 behandelt also den ersten Haupteffekt so, als hätte er eine Art theoretischen Vorrang vor dem zweiten. Meiner Erfahrung nach gibt es sehr selten, wenn überhaupt, eine theoretische Vorrangstellung, die eine asymmetrische Behandlung zweier Haupteffekte rechtfertigen würde.
Die Konsequenz aus all dem ist, dass Hypothesentests vom Typ 1 nur sehr selten von großem Interesse sind, so dass wir zu den Tests von Typ 2 und Typ 3 übergehen sollten.
Typ-3-Quadratsumme
Nachdem wir gerade über Hypothesentests vom Typ 1 gesprochen haben, könnte man meinen, dass es naheliegend wäre, als Nächstes über Tests vom Typ 2 zu sprechen. Ich halte es jedoch für natürlicher, zunächst über Tests vom Typ 3 zu sprechen (die einfacher sind und in der ANOVA in jamovi standardmäßig verwendet werden), bevor man sich mit den Hypothesentests vom Typ 2 befasst (die schwieriger sind). Die Grundidee hinter den Typ-3-Tests ist extrem einfach. Unabhängig davon, welchen Term Sie zu bewerten versuchen, führen Sie den F-Test durch, bei dem die Alternativhypothese dem vollständigen ANOVA-Modell entspricht, wie vom Benutzer angegeben, und das Nullmodell nur den Term, den Sie gerade testen, löscht. In dem Beispiel aus dem coffee-Datensatz, in dem unser vollständiges Modell babble ~ sugar + milk + sugar * milk war, würde der Test auf einen Haupteffekt von sugar einem Vergleich zwischen den beiden folgenden Modellen entsprechen:
Nullmodell: |
|
Alternativmodell: |
|
In ähnlicher Weise wird der Haupteffekt von milk getestet, indem das vollständige Modell mit einem Nullmodell verglichen wird, bei dem der Term milk entfernt wurde:
Nullmodell: |
|
Alternativmodell: |
|
Schließlich wird der Interaktionsterm sugar * milk auf genau die gleiche Weise ausgewertet. Auch hier testen wir das vollständige Modell gegen ein Nullmodell, bei dem der Interaktionsterm sugar * milk entfernt wurde:
Nullmodell: |
|
Alternativmodell: |
|
Die Grundidee lässt sich auf ANOVAs höherer Ordnung (d.h., mit mehr als zwei Faktoren) verallgemeinern. Nehmen wir zum Beispiel an, wir wollten eine ANOVA mit drei Faktoren durchführen, A, B und C, und wir wollten alle möglichen Haupteffekte und alle möglichen Interaktionen berücksichtigen, einschließlich der Drei-Wege-Interaktion A * B * C. Die nachstehende Tabelle zeigt Ihnen, wie die Typ-3-Tests für diese Situation aussehen würden:
Der geprüfte Term ist |
Das Nullmodell ist |
Das Alternativmodell ist |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
So hässlich diese Tabelle auch aussieht, sie ist ziemlich einfach. In allen Fällen entspricht die alternative Hypothese dem vollständigen Modell, das drei Haupteffektterme (z. B. A), drei Zweifach-Interaktionen (z. B. A * B) und eine Dreifach-Interaktion (d. h. A * B * C) enthält. Das Nullmodell enthält immer 6 dieser 7 Terme, und der fehlende Term ist derjenige, dessen Signifikanz wir zu testen versuchen.
Auf den ersten Blick scheinen die Hypothesentests vom Typ 3 eine gute Idee zu sein. Erstens haben wir die Asymmetrie beseitigt, die uns beim Durchführen von Tests vom Typ 1 Probleme bereitet hat. Und da wir nun alle Terme gleich behandeln, hängen die Ergebnisse der Hypothesentests nicht von der Reihenfolge ab, in der wir sie angeben. Das ist definitiv eine gute Sache. Allerdings gibt es ein großes Problem bei der Interpretation der Testergebnisse, insbesondere in Bezug auf die Haupteffekt-Terme. Betrachten wir die coffee-Daten. Nehmen wir an, es stellt sich heraus, dass der Haupteffekt von milk nach den Typ-3-Tests nicht signifikant ist. Dies sagt uns, dass babble ~ sugar + sugar * milk ein besseres Modell für die Daten ist als das vollständige Modell. Aber was bedeutet das überhaupt? Wenn der Interaktionsterm sugar * milk ebenfalls nicht signifikant wäre, wären wir versucht zu schlussfolgern, dass die Daten uns sagen, dass das Einzige, was zählt, sugar ist. Aber nehmen wir an, wir haben einen signifikanten Interaktionsterm, aber einen nicht-signifikanten Haupteffekt von milk. Sollen wir in diesem Fall annehmen, dass es tatsächlich einen „Zuckereffekt“ und eine „Wechselwirkung zwischen Milch und Zucker“, aber keinen „Milcheffekt“ gibt? Das scheint verrückt. Die richtige Antwort lautet einfach, dass es sinnlos ist[3], vom Haupteffekt zu sprechen, wenn die Wechselwirkung signifikant ist. Dies scheint auch der Rat der meisten Statistiker zu sein, und ich denke, es ist der richtige Rat. Aber wenn es wirklich bedeutungslos ist, von nicht-signifikanten Haupteffekten bei Vorhandensein einer signifikanten Wechselwirkung zu sprechen, dann ist es überhaupt nicht offensichtlich, warum Tests vom Typ 3 zulassen sollten, dass sich die Nullhypothese auf ein Modell stützt, das die Wechselwirkung einschließt, aber einen der Haupteffekte, aus denen sie besteht, auslässt. Wenn man die Nullhypothesen auf diese Art und Weise charakterisiert, machen sie wirklich keinen großen Sinn.
Später werden wir sehen, dass Hypothesentests vom Typ 3 in einigen Kontexten verwendet werden können, aber sehen wir uns zunächst die ANOVA-Ergebnistabelle mit einer Quadratsumme vom Typ 3 in Abb. 172 an.

Abb. 172 ANOVA-Ergebnistabelle unter Verwendung von Typ-3-Quadratsumme in jamovi (mit dem coffee-Datensatz sowie einem gesättigten Modell mit den Faktoren sugar, milk und deren Interaktion).
Aber seien Sie sich bewusst, dass eine der perversen Eigenschaften der Typ-3-Teststrategie darin besteht, dass die Ergebnisse typischerweise von den Kontrasten abhängen, die Sie zur Kodierung Ihrer Faktoren verwenden (siehe Abschnitt Verschiedene Möglichkeiten, Kontraste zu definieren, falls Sie vergessen haben, was die verschiedenen Arten von Kontrasten sind).[4]
Wenn also die p-Werte, die typischerweise bei Analysen mit Typ-3-Quadratsummen herauskommen, empfindlich auf die Wahl der Kontraste reagieren, bedeutet das, dass Typ-3-Tests im Wesentlichen willkürlich sind und man ihnen nicht trauen kann? Bis zu einem gewissen Grad stimmt das, und wenn wir uns der Diskussion von Typ-2-Tests zuwenden, werden wir sehen, dass Typ-2-Analysen diese Willkür vermeiden, aber ich denke, das ist eine zu starke Schlussfolgerung. Erstens ist es wichtig zu erkennen, dass die Wahl einiger Kontraste immer zu den gleichen Antworten führt (und dieses Vorgehen ist in jamovi implementiert). Besonders wichtig ist die Tatsache, dass die Analyse vom Typ 3 immer die gleichen Antworten liefert, wenn alle Spalten unserer Kontrastmatrix die Summe Null ergeben.
Typ-2-Quadratsumme
Bisher haben wir die Tests vom Typ 1 und 3 behandelt, und beide sind ziemlich einfach. Typ-1-Tests werden durchgeführt, indem man schrittweise einen Term nach dem anderen hinzufügt, während man bei Typ-3-Tests das gesamte Modell nimmt und schaut, was passiert, wenn man die einzelnen Terme entfernt. Beide weisen jedoch einige Einschränkungen auf. Typ-1-Tests hängen von der Reihenfolge ab, in der Sie die Terme eingeben, und Typ-3-Tests hängen davon ab, wie Sie Ihre Kontraste kodieren. Tests vom Typ 2 sind etwas schwieriger zu beschreiben, aber sie vermeiden diese beiden Probleme und sind daher leichter zu interpretieren.
Tests vom Typ 2 ähneln weitgehend den Tests vom Typ 3. Man beginnt mit einem „vollständigen“ Modell und testet einen bestimmten Term, indem man ihn aus diesem Modell entfernt. Typ-2-Tests beruhen jedoch auf dem Marginalitätsprinzip, das besagt, dass Sie einen Term niedrigerer Ordnung nicht aus Ihrem Modell streichen sollten, wenn es davon abhängige Terme höherer Ordnung gibt. Wenn Ihr Modell also zum Beispiel die Zweifach-Interaktion A * B (einen Term 2. Ordnung) enthält, dann sollte es gleichzeitig auch die Haupteffekte A und B (Terme 1. Ordnung) enthalten. Ähnlich verhält es sich, wenn das Modell einen Dreifach-Interaktionsterm A * B * C enthält, dann muss das Modell auch die Haupteffekte A, B und C sowie die Interaktionen A * B, A * C und B * C enthalten. Tests vom Typ 3 verletzen das Marginalitätsprinzip. Betrachten wir zum Beispiel den Test des Haupteffekts von A im Rahmen einer dreifaktoriellen ANOVA, die alle möglichen Interaktionsterme einschließt. Gemäß den Tests vom Typ 3 lauten unsere Null- und Alternativmodelle:
Nullmodell: |
|
Alternativmodell: |
|
Beachten Sie, dass die Nullhypothese A auslässt, aber A * B, A * C und A * B * C als Teil des Modells einschließt. Nach den Tests vom Typ 2 ist dies keine gute Wahl der Nullhypothese. Wenn wir stattdessen die Nullhypothese testen wollen, dass A für unser outcome nicht relevant ist, sollten wir die Nullhypothese angeben, die das komplizierteste Modell ist, das sich nicht auf A in irgendeiner Form stützt, auch nicht als Interaktion. Die Alternativhypothese entspricht diesem Nullmodell plus einem Haupteffektterm von A. Dies ist viel näher an dem, was die meisten Leute intuitiv als „Haupteffekt von A“ ansehen würden, und es ergibt sich das Folgende als unser Typ-2-Test des Haupteffekts von A:[5]
Nullmodell: |
|
Alternativmodell: |
|
Um Ihnen ein Gefühl dafür zu vermitteln, wie sich die Typ-2-Tests auswirken, finden Sie hier die vollständige Tabelle aller Tests, die bei einer dreifaktoriellen ANOVA verwendet würden:
Der geprüfte Term ist |
Das Nullmodell ist |
Das Alternativmodell ist |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Im Zusammenhang mit der zweifaktoriellen ANOVA, die wir für die coffee-Daten verwendet haben, sind die Hypothesentests noch einfacher. Der Haupteffekt von sugar entspricht einem F-Test zum Vergleich dieser beiden Modelle:
Nullmodell: |
|
Alternativmodell: |
|
Der Test für den Haupteffekt von milk lautet
Nullmodell: |
|
Alternativmodell: |
|
Schließlich lautet der Test für die Interaktion sugar * milk:
Nullmodell: |
|
Alternativmodell: |
|
Das Durchführen des Typ-2-Tests ist wiederum unkompliziert. Wählen Sie einfach Type 2 im Auswahlfeld Sum of squares in den Optionen ANOVA → Model in jamovi, und Sie erhalten die in Abb. 173 gezeigte ANOVA-Tabelle.

Abb. 173 ANOVA-Ergebnistabelle unter Verwendung von Typ-2-Quadratsumme in jamovi (mit dem coffee-Datensatz sowie einem gesättigten Modell mit den Faktoren sugar, milk und deren Interaktion).
Tests vom Typ 2 haben einige klare Vorteile gegenüber Tests vom Typ 1 und Typ 3. Sie hängen nicht von der Reihenfolge ab, in der Sie die Faktoren spezifizieren (im Gegensatz zu Typ 1), und sie hängen nicht von den Kontrasten ab, die Sie zur Spezifikation Ihrer Faktoren verwenden (im Gegensatz zu Typ 3). Und obwohl die Meinungen über diesen letzten Punkt auseinandergehen können und es definitiv davon abhängt, was Sie mit Ihren Daten zu tun versuchen, denke ich, dass die Hypothesentests, die sie spezifizieren, mit größerer Wahrscheinlichkeit etwas entsprechen, was Sie tatsächlich interessiert. Folglich finde ich, dass die Ergebnisse eines Typ-2-Tests in der Regel leichter zu interpretieren sind als die Ergebnisse eines Typ-1- oder Typ-3-Tests. Aus diesem Grund lautet mein vorsichtiger Ratschlag: Wenn Ihnen keine offensichtlichen Modellvergleiche einfallen, die sich direkt auf Ihre Forschungsfragen beziehen, Sie aber dennoch eine ANOVA in einem unbalancierten Design durchführen möchten, sind Tests vom Typ 2 wahrscheinlich die bessere Wahl als Tests vom Typ 1 oder Typ 3.[6]
Effektstärken (und nicht-additive Quadratsummen)
jamovi liefert die Effektstärken η² und partielles η², wenn Sie diese Optionen auswählen, wie in Abb. 173 gezeigt. Wenn Sie jedoch ein unbalanciertes Design haben, ist die Berechnung etwas komplexer.
Wenn Sie sich an unsere frühen Diskussionen über die ANOVA erinnern, ist eine der wichtigsten Ideen hinter der Berechnung der Quadratsummen, dass wir die totale Quadratsumme erhalten sollten wenn wir alle SS-Terme, die mit den Effekten im Modell verbunden sind, sowie die SS der Residuen addieren. Darüber hinaus besteht die Idee hinter η² darin, dass ein η²-Wert als der Anteil der Varianz interpretiert werden kann, der durch einen bestimmten Term erklärt wird, weil man einen der SS-Terme durch den totalen SS-Wert teilt. Bei unbalancierten Versuchsdesigns ist dies jedoch nicht so einfach, da ein Teil der Varianz „verloren“ geht.
Das erscheint zunächst etwas seltsam, aber hier ist der Grund dafür. Bei unbalancierten Versuchsplänen korrelieren die Faktoren miteinander, und es wird schwierig, den Unterschied zwischen dem Effekt von Faktor A und dem Effekt von Faktor B zu erkennen. Nehmen wir im Extremfall an, wir hätten einen 2 × 2-Versuchsplan durchgeführt, bei dem die Anzahl der Teilnehmer in jeder Gruppe wie folgt gewesen wäre:
Zucker |
kein Zucker |
|
|---|---|---|
Milch |
100 |
0 |
keine Milch |
0 |
100 |
Hier haben wir ein spektakulär unausgewogenes Design: 100 Personen haben Milch und Zucker, 100 Personen haben keine Milch und keinen Zucker, und das ist alles. Es gibt 0 Personen mit Milch und ohne Zucker, und 0 Personen mit Zucker, aber ohne Milch. Nehmen wir nun an, dass sich bei der Datenerhebung ein großer (und statistisch signifikanter) Unterschied zwischen der „Milch und Zucker“-Gruppe und der „keine-Milch-und-kein-Zucker“-Gruppe herausstellt. Ist dies ein Haupteffekt von Zucker? Ein Haupteffekt der Milch? Oder eine Wechselwirkung? Das ist unmöglich zu sagen, denn das Vorhandensein von Zucker steht in perfektem Zusammenhang mit dem Vorhandensein von Milch. Nehmen wir nun an, das Design wäre etwas balancierter gewesen:
Zucker |
kein Zucker |
|
|---|---|---|
Milch |
100 |
5 |
keine Milch |
5 |
100 |
Diesmal ist es technisch möglich, zwischen dem Effekt der Milch und dem Effekt des Zuckers zu unterscheiden, weil wir einige Personen haben, die das eine, aber nicht das andere haben. Es wird jedoch immer noch ziemlich schwierig sein, dies zu tun, weil die Assoziation zwischen Zucker und Milch immer noch extrem stark ist und es so wenige Beobachtungen in zwei der vier Gruppen gibt. Auch hier ist es sehr wahrscheinlich, dass wir wissen, dass die Prädiktorvariablen (milk und sugar) mit dem Ergebnis (Redemenge) zusammenhängen, aber wir wissen nicht, ob die Natur dieser Beziehung ein Haupteffekt des einen oder des anderen Prädiktors bzw. der Interaktion ist.
Diese Unsicherheit ist der Grund für die fehlende Varianz. Die „fehlende“ Varianz entspricht der Variation in der Ergebnisvariablen, die eindeutig auf die Prädiktoren zurückzuführen ist, aber wir wissen nicht, welcher der Effekte im Modell dafür verantwortlich ist. Bei der Berechnung der Quadratsumme vom Typ 1 geht keine Varianz verloren. Die sequentielle Natur der Quadratsumme vom Typ 1 bedeutet, dass die ANOVA diese Varianz automatisch denjenigen Effekten zuordnet, die zuerst eingegeben werden. Die Tests vom Typ 2 und Typ 3 sind jedoch konservativer. Varianz, die nicht eindeutig einem bestimmten Effekt zugeordnet werden kann, wird keinem dieser Effekte zugeordnet und geht verloren.