Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Post-hoc-Tests
Es ist nun Zeit, sich einem anderen Thema zu widmen. Anstatt geplanter Vergleiche, die mit Hilfe von Kontrasten getestet werden, haben Sie einfach Ihre ANOVA durchgeführt und haben einige signifikante Effekte erhalten haben. Da es sich bei den F-Tests um „Omnibus“-Tests handelt, die eigentlich nur die Nullhypothese testen, dass es keine Unterschiede zwischen den Gruppen gibt, sagt die Feststellung eines signifikanten Effekts nichts darüber aus, welche der Gruppen sich von welchen anderen unterscheiden. Wir haben dieses Problem bereits in Kapitel Vergleich mehrerer Mittelwerte (einfaktorielle ANOVA) erörtert. In jenem Kapitel bestand unsere Lösung darin, t-Tests für alle möglichen Gruppenpaare durchzuführen und dabei Korrekturen für multiple Paarvergleiche (z. B. Bonferroni, Holm) vorzunehmen, um die Fehlerrate vom Typ I bei diesen Vergleichen zu kontrollieren. Die Methoden, die wir damals verwendet haben, haben den Vorteil, dass sie relativ einfach sind und sie lassen sich in vielen verschiedenen Situationen verwenden, in denen man mehrere Hypothesen testet. Sie sind aber nicht unbedingt die beste Wahl, wenn man an effizienten Post-hoc-Tests im Rahmen einer ANOVA interessiert ist. In der Statistikliteratur gibt es eine ganze Reihe verschiedener Methoden zum Durchführen von multiplen Paarvergleichen (Hsu, 1996), und es würde den Rahmen eines einführenden Textes wie diesem sprengen, sie alle im Detail zu besprechen.
Allerdings gibt es ein Instrument, auf das ich Ihre Aufmerksamkeit lenken möchte, nämlich Tukey’s „Honestly Significant Difference“ oder kurz Tukey’s HSD. Ich werde Ihnen die Formeln ersparen und erkläre stattdessen nur die grundlegende Idee. Diese ist, alle relevanten paarweisen Vergleiche zwischen Gruppen zu untersuchen, und es ist nur dann wirklich sinnvoll, Tukey’s HSD zu verwenden, wenn Sie an paarweisen Unterschieden interessiert sind.[1] Wenn wir zum Beispiel früher eine faktorielle ANOVA mit dem clinicaltrial-Datensatz durchgeführt haben und einen Haupteffekt für drug und einen Haupteffekt von therapy angegeben haben, wären wir an den folgenden vier Vergleichen interessiert:
Der Unterschied in der Stimmungsverbesserung bei Personen, die
Anxifreeerhielten, im Vergleich zu Personen, die dasPlaceboerhielten.Der Unterschied in der Stimmungsverbesserung bei Personen, die
Joyzepamerhielten, im Vergleich zu Personen, die dasPlaceboerhielten.Der Unterschied in der Stimmungsverbesserung bei Personen, die
Anxifreeerhalten haben, gegenüber Personen, dieJoyzepamerhalten haben.Der Unterschied in der Stimmungsverbesserung bei Personen, die mit
CBTbehandelt wurden, und Personen, dieno.therapyerhielten.
Für jeden dieser Vergleiche interessieren wir uns für den wahren Unterschied zwischen den Gruppenmitteln (in der Gesamtpopulation). Tukey’s HSD konstruiert simultane Konfidenzintervalle für alle vier dieser Vergleiche. Was wir mit 95 % „gleichzeitigem“ Konfidenzintervall meinen, ist, dass, wenn wir diese Studie viele Male wiederholen würden, die Konfidenzintervalle in 95 % der Studienergebnisse den wahren Wert (der Gesamtpopulation) enthalten würden. Außerdem können wir diese Konfidenzintervalle verwenden, um einen bereinigten p-Wert für einen bestimmten Vergleich zu berechnen.
Die Funktion TukeyHSD in jamovi ist ziemlich einfach zu benutzen. Sie geben einfach den Term des ANOVA-Modells an, für den Sie die Post-hoc-Tests durchführen möchten. Wenn wir zum Beispiel Post-Hoc-Tests für die Haupteffekte, aber nicht für die Interaktion durchführen wollen, öffnen wir die Option Post Hoc Tests in den ANOVA-Analyseoptionen, verschieben die Variablen drug und therapy in das Feld auf der rechten Seite und aktivieren dann die Tukey-Checkbox aus der Liste der möglichen Post-Hoc-Korrekturen. Dieses Vorgehen wird zusammen mit der entsprechenden Ergebnistabelle in Abb. 167 gezeigt.
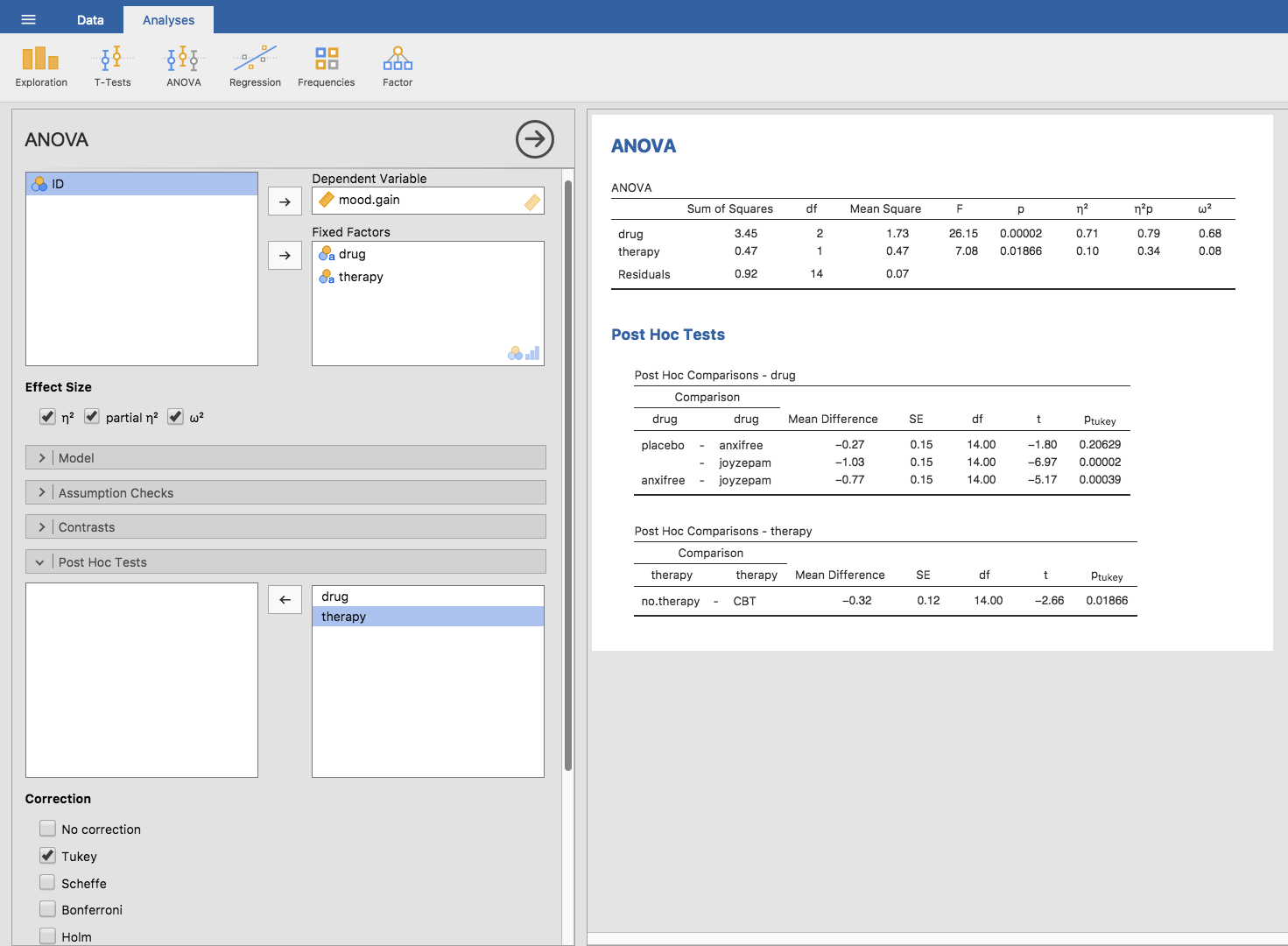
Abb. 167 Options-Panel zum Definieren von Post-hoc-Tests innerhalb der faktoriellen ANOVA in jamovi (die aktuellen Einstellungen erstellen eine Tukey HSD-Statistik): Modell mit den Faktoren drug und therapy, aber ohne einen Interaktionsterm für die beiden Faktoren (unter Verwendung des clinicaltrial Datensatzes)
Die Ausgabe in der Ergebnistabelle Post Hoc Tests ist (hoffentlich) recht übersichtlich. Der erste Vergleich ist zum Beispiel der Unterschied zwischen Anxifree und Placebo, und der erste Teil der Ausgabe zeigt an, dass der beobachtete Unterschied der Gruppenmittelwerte 0,27 beträgt. Die nächste Zahl ist der Standardfehler für den Unterschied. Dann gibt es eine Spalte mit den Freiheitsgraden, eine Spalte mit dem t-Wert und schließlich eine Spalte mit dem p-Wert. Für den ersten Vergleich beträgt der bereinigte p-Wert 0,21. Im Gegensatz dazu sehen wir in der nächsten Zeile, dass der beobachtete Unterschied zwischen Joyzepam und dem Placebo 1,03 beträgt, und dieses Ergebnis signifikant ist (p < 0,001).
Wie sieht es aus, wenn Ihr Modell Interaktionsterme enthält? Die Standardoption in jamovi berücksichtigt zum Beispiel die Möglichkeit, dass es eine Wechselwirkung zwischen drug und therapy gibt. Wenn dies der Fall ist, erhöht sich die Anzahl der Paarvergleiche, die wir berücksichtigen müssen. Wie zuvor müssen wir die drei Vergleiche berücksichtigen, die für den Haupteffekt von drug relevant sind, und den einen Vergleich, der für den Haupteffekt von therapy relevant ist. Wenn wir jedoch die Möglichkeit einer signifikanten Interaktion in Betracht ziehen wollen (und versuchen, die Gruppenunterschiede zu finden, die dieser signifikanten Interaktion zugrunde liegen), müssen wir Vergleiche wie die folgenden einbeziehen:
Der Unterschied in
mood.gainbei Personen, dieanxifreeerhalten haben und mitCBTbehandelt wurden, und Personen, die dasplaceboerhalten haben und mitCBTbehandelt wurdenDer Unterschied in
mood.gainfür Personen, dieanxifreeundno.therapyerhalten haben, und Personen, dieplaceboundno.therapyerhalten haben.usw.
Es gibt einige Paarvergleiche, die Sie berücksichtigen müssen. Wenn wir also die Tukey-Post-hoc-Analyse für dieses ANOVA-Modell durchführen, sehen wir, dass jamovi eine Menge Paarvergleiche (insgesamt 19) durchgeführt hat, wie in Abb. 168 gezeigt. Sie können sehen, dass die Ausgabe zwar grundsätzlich ziemlich ähnlich aussieht wie vorher, aber viel mehr Vergleiche enthält.

Abb. 168 Ergebnistabelle für einen Tukey-HSD-Post-hoc-Test im Rahmen einer faktoriellen ANOVA (unter Verwendung des clinicaltrial Datensatzes) in jamovi: Modell mit den Faktoren drug und therapy, aber ohne den Interaktionsterm dieser beiden Faktoren