Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Faktorielle ANOVA 2: balancierte Designs mit Wechselwirkungen

Abb. 148 Unterschiedliche, mögliche Wechselwirkungen bei einer 2 × 2 ANOVA
Die vier in Abb. 147 gezeigten Muster von Daten sind alle recht realistisch. Es gibt sehr viele Datensätze, die genau diese Muster aufweisen. Sie sind jedoch nicht die ganze Geschichte, und das ANOVA-Modell, über das wir bis jetzt gesprochen haben, reicht nicht aus, um eine Tabelle mit Gruppenmittelwerten vollständig zu erklären. Warum nicht? Nun, bisher können wir über die Idee sprechen, dass Medikamente die Stimmung beeinflussen können, und dass eine Therapie die Stimmung beeinflussen kann, aber wir können nicht über die Möglichkeit einer Interaktion zwischen den beiden sprechen. Von einer Wechselwirkung zwischen A und B spricht man immer dann, wenn die Wirkung von Faktor A unterschiedlich ist, je nachdem, von welchem Niveau des Faktors B wir sprechen. Mehrere Beispiele für einen Interaktionseffekt im Zusammenhang mit einer 2 × 2 ANOVA sind in Abb. 148 dargestellt. Um ein konkreteres Beispiel zu geben, nehmen wir an, dass die Wirkung von Anxifree und Joyzepam von unterschiedlichen physiologischen Mechanismen gesteuert wird. Eine Folge davon ist, dass Joyzepam mehr oder weniger die gleiche Wirkung auf die Stimmung hat, unabhängig davon, ob man sich in einer Therapie befindet, während Anxifree viel effektiver ist, wenn es in Verbindung mit CBT verabreicht wird. Die ANOVA, die wir im vorherigen Abschnitt durchgeführt haben, erfasst diese Idee nicht. Um eine Vorstellung davon zu bekommen, ob tatsächlich eine Wechselwirkung vorliegt, ist es hilfreich, die verschiedenen Gruppenmittelwerte darzustellen. In jamovi wird dies über das ANOVA-Optionsfeld Estimated Marginal Means definiert - verschieben Sie einfach drug und therapy in das Feld Marginal Means unter Term 1. Dies sollte ungefähr so aussehen wie Abb. 149. Unsere Hauptsorge bezieht sich auf die Tatsache, dass die beiden Zeilen nicht parallel sind. Die Auswirkung von CBT (Unterschied zwischen durchgezogener und gestrichelter Linie), wenn joyzepam als drug verwendet wurde (rechte Seite), scheint fast Null zu sein, sogar kleiner als die Auswirkung von CBT, wenn placebo als drug verwendet wird (linke Seite). Wenn jedoch anxifree als drug verabreicht wird, ist die Wirkung von CBT größer als die von no.therapy (Mitte). Ist dieser Effekt real oder handelt es sich nur um eine zufällige Variation, die auf Zufall zurückzuführen ist? Unsere ursprüngliche ANOVA kann diese Frage nicht beantworten, denn wir berücksichtigen nicht, dass es möglicherweise Wechselwirkungen gibt! In diesem Abschnitt werden wir dieses Problem beheben.
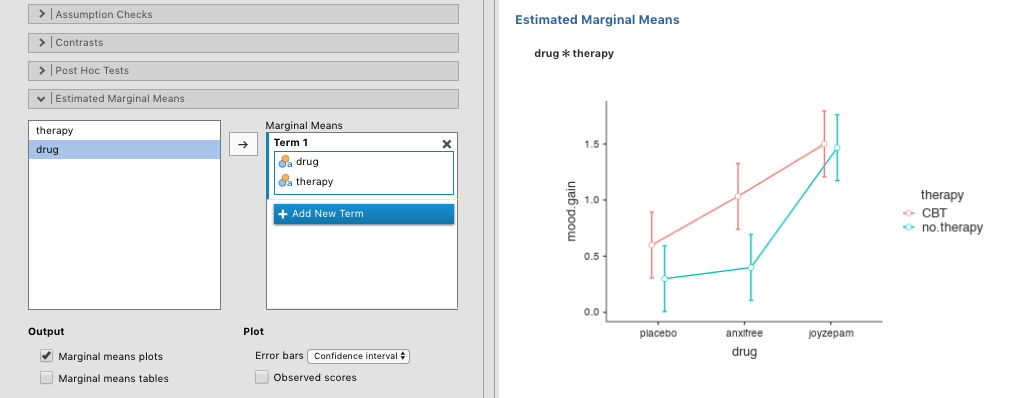
Abb. 149 jamovi-Bildschirmfoto, das zeigt, wie ein Interaktionsdiagramm innerhalb der ANOVA (unter Verwendung von Estimated Marginal Means) für den clinicaltrial-Datensatz erzeugt wird
Was genau ist ein Interaktionseffekt?
Der Schlüsselbegriff, den wir in diesem Abschnitt einführen werden, ist der eines Interaktionseffekts. In dem ANOVA-Modell, das wir bisher betrachtet haben, sind nur zwei Faktoren an unserem Modell beteiligt (d. h. drug und therapy). Wenn wir jedoch eine Interaktion hinzufügen, fügen wir dem Modell eine weitere Komponente hinzu: die Kombination von drug und therapy. Intuitiv ist die Idee hinter einem Interaktionseffekt recht einfach. Es bedeutet einfach, dass die Wirkung von Faktor A unterschiedlich ist, je nachdem, über welche Stufe von Faktor B wir sprechen. Aber was bedeutet das in Bezug auf unsere Daten? Das Diagramm in Abb. 148 zeigt mehrere verschiedene Muster, die sich zwar stark voneinander unterscheiden, aber alle als Interaktionseffekt gelten würden. Es ist also nicht ganz einfach, diese qualitative Idee in etwas Mathematisches zu übersetzen, mit dem ein Statistiker arbeiten kann.
Folglich ist die Art und Weise, wie die Idee eines Interaktionseffekts in Form von Null- und Alternativhypothesen formalisiert wird, etwas schwierig. Ich vermute, dass viele Leser dieses Buches daran wahrscheinlich nicht sonderlich interessiert sein werden. Trotzdem werde ich versuchen, zumindest die Grundidee zu vermitteln.
Zu Beginn müssen wir unsere Haupteffekte etwas genauer beschreiben. Betrachten wir den Haupteffekt des Faktors A (drug in unserem Beispiel). Ursprünglich formulierten wir dies im Sinne der Nullhypothese, dass die beiden Randmittel µr. alle gleich sind. Wenn diese alle gleich sind, dann müssen sie natürlich auch gleich dem Gesamtmittelwert µ.. sein. Wir können also den Effekt des Faktors A auf der Ebene r als gleich der Differenz zwischen dem Randmittel µr. und dem Gesamtmittelwert µ.. definieren. Bezeichnen wir diesen Effekt mit αr, dann stellen wir fest, dass
Nun müssen sich per Definition alle αr-Werte zu Null summieren, und zwar aus demselben Grund, aus dem der Durchschnitt der Randmittel µr. der Gesamtmittelwert µ.. sein muss. In ähnlicher Weise können wir den Effekt von Faktor B auf Ebene i als die Differenz zwischen dem Randmittel der Spalte µ.c und dem Gesamtmittelwert µ.. definieren
und auch hier müssen diese βc-Werte in der Summe Null ergeben. Der Grund dafür, dass Statistiker manchmal gerne über die Haupteffekte in Form dieser αr- und βc-Werte sprechen, ist, dass sie damit genau sagen können, was es bedeutet, dass es keinen Interaktionseffekt gibt. Wenn es überhaupt keine Interaktion gibt, dann beschreiben diese αr- und βc-Werte perfekt die Gruppenmittelwerte µrc. Konkret bedeutet dies, dass
Das heißt, es gibt nichts Besonderes an den Gruppenmitteln, das man nicht perfekt vorhersagen könnte, wenn man alle Randmittel kennen würde. Und das ist genau unsere Nullhypothese. Die Alternativhypothese ist, dass
für mindestens eine Gruppe rc in unserer Tabelle. Statistiker schreiben dies jedoch oft etwas anders. Normalerweise definieren sie die spezifische Interaktion, die mit der Gruppe rc verbunden ist, als eine Zahl, die umständlich als αβrc bezeichnet wird, und dann sagen sie, dass die alternative Hypothese lautet, dass
wobei αβrc für mindestens eine Gruppe ungleich Null ist. Diese Notation ist zwar etwas hässlich anzusehen, aber sie ist praktisch, wie wir im nächsten Abschnitt sehen werden, wenn wir besprechen, wie man die Quadratsumme berechnet.
Berechnung der Quadratsummen für Interaktionen
Wie berechnet man die Quadratsumme für die Interaktionsterme, SSA:B? Zunächst einmal ist es hilfreich zu wissen, dass im vorherigen Abschnitt der Interaktionseffekt als das Ausmaß definiert wurde, in dem sich die tatsächlichen Gruppenmittelwerte von dem unterscheiden, was man erwarten würde, wenn man nur die Randmittel betrachtet. Natürlich beziehen sich all diese Formeln auf Populationsparameter und nicht auf Stichprobenstatistiken, so dass wir nicht wissen, wie hoch sie tatsächlich sind. Wir können sie jedoch schätzen, indem wir die Stichprobenmittelwerte anstelle der Populationsmittelwerte verwenden. Für Faktor A lässt sich der Haupteffekt auf der Ebene r also gut als Differenz zwischen dem Randmittel der Stichprobe Ȳrc und dem Gesamtmittelwert der Stichprobe Ȳ..schätzen. Das heißt, wir würden dies als unsere Schätzung des Effekts verwenden
Analog dazu kann unsere Schätzung des Haupteffekts von Faktor B auf der Ebene c wie folgt definiert werden
Wenn Sie nun zu den Formeln zurückgehen, die ich zur Beschreibung der SS-Werte für die beiden Haupteffekte verwendet habe, werden Sie feststellen, dass diese Effektterme genau die Größen sind, die wir quadriert und summiert haben! Aber wie verhält es sich mit den Interaktionstermen? Die Antwort darauf finden wir, indem wir zunächst die Formel für die Gruppenmittelwerte µrc unter der Alternativhypothese so umstellen, dass wir Folgendes erhalten
Wenn wir also wieder einmal unsere Stichprobenstatistiken anstelle der Populationsmittelwerte einsetzen, erhalten wir als Schätzung des Interaktionseffekts für die Gruppe rc folgendes Ergebnis
Jetzt müssen wir nur noch alle diese Schätzungen über alle R Stufen von Faktor A und alle C Stufen von Faktor B summieren, und wir erhalten die folgende Formel für die Quadratsumme, die mit der Interaktion verbunden sind
wobei wir mit N multiplizieren, weil es N Beobachtungen in jeder der Gruppen gibt, und wir wollen, dass unsere SS-Werte die Variation zwischen Beobachtungen widerspiegeln, die durch die Interaktion erklärt wird, nicht die Variation zwischen den Gruppen.
Da wir nun eine Formel zur Berechnung von SSA:B haben, ist es wichtig zu erkennen, dass der Interaktionsterm (selbstverständlich) Teil des Modells ist, so dass die Gesamtquadratsumme, die mit dem Modell verbunden ist, SSM, nun gleich der Summe der drei relevanten SS-Werte ist, SSA + SSB + SSA:B. Die Quadratsumme der Residuen SSR ist immer noch definiert als die verbleibende Variation, nämlich SST - SSM, aber jetzt, da wir den Interaktionsterm haben, wird dies zu
Infolgedessen wird die Quadratsumme der Residuen SSR kleiner sein als in unserer ursprünglichen ANOVA, die keine Wechselwirkungen enthielt.
Freiheitsgrade für die Interaktion
Die Berechnung der Freiheitsgrade für die Interaktion ist wiederum etwas komplizierter als die entsprechende Berechnung für die Haupteffekte. Betrachten wir zunächst einmal das ANOVA-Modell als Ganzes. Sobald wir Interaktionseffekte in das Modell aufnehmen, lassen wir zu, dass jede einzelne Gruppe einen eindeutigen Mittelwert hat, µrc. Für eine R × C faktorielle ANOVA bedeutet dies, dass es R × C Größen gibt, die im Modell von Interesse sind, und dass es nur eine einzige Einschränkung gibt: Alle Gruppenmittelwerte müssen sich zum Gesamtmittelwert ausgleichen. Das Modell als Ganzes muss also (R × C) - 1 Freiheitsgrade haben. Der Haupteffekt von Faktor A hat jedoch R - 1 Freiheitsgrade, und der Haupteffekt von Faktor B hat C - 1 Freiheitsgrade. Dies bedeutet, dass die mit der Interaktion verbundenen Freiheitsgrade
was einfach das Produkt der Freiheitsgrade ist, die mit dem Zeilenfaktor und dem Spaltenfaktor verbunden sind.
Was ist mit den restlichen Freiheitsgraden? Da wir einen Interaktionsterm hinzugefügt haben, der einige Freiheitsgrade absorbiert, bleiben weniger Restfreiheitsgrade übrig. Wenn das Modell mit Interaktion eine Gesamtzahl von (R × C) - 1 hat und es N Beobachtungen in Ihrem Datensatz gibt, die durch einen Gesamtmittelwert beschränkt (constrained) werden, sind Ihre verbleibenden Freiheitsgrade jetzt N -(R × C) - 1 + 1 oder einfach N - (R × C).
Durchführen der ANOVA in jamovi
Das Hinzufügen von Interaktionstermen zum ANOVA-Modell in jamovi ist ganz einfach. Es ist sogar die Standardoption beim Erstellen einer ANOVA. Das heißt, wenn Sie eine ANOVA mit zwei Faktoren angeben, z. B. drug und therapy, dann wird der Interaktionsterm - drug × therapy (angezeigt als drug * therapy) - automatisch zum Modell hinzugefügt.[1] Wenn wir die ANOVA mit dem eingeschlossenen Interaktionsterm durchführen, erhalten wir die in Abb. 150 gezeigten Ergebnisse.

Abb. 150 Ergebnisse für das vollständige faktorielle Modell, einschließlich des Interaktionsterms für drug × therapy
Wie sich herausstellt, haben wir zwar jeweils signifikante Haupteffekte für drug: F(2,12) = 31.7, p < 0.001, und therapy: F(1,12) = 8.6, p = 0.013), aber es gibt keine signifikante Interaktion zwischen den beiden: F(2,12) = 2,5, p = 0,125).
Interpretation der Ergebnisse
Bei der Interpretation der Ergebnisse der faktoriellen ANOVA sind einige sehr wichtige Dinge zu beachten. Erstens gibt es das gleiche Problem wie bei der einfaktoriellen ANOVA: Wenn Sie einen signifikanten Haupteffekt von (sagen wir) drug erhalten, sagt das nichts darüber aus, wie sich die Werte von drug voneinander unterscheiden. Um das herauszufinden, müssen Sie zusätzliche Analysen durchführen. Über einige Analysen, die Sie durchführen können, sprechen wir in den Abschnitten Verschiedene Möglichkeiten, Kontraste zu definieren und Post-hoc-Tests. Das Gleiche gilt für Interaktionseffekte. Das Wissen, dass es eine signifikante Interaktion gibt, sagt nichts darüber aus, welche Art von Interaktion existiert. Auch hier müssen Sie zusätzliche Analysen durchführen.
Zweitens gibt es ein sehr merkwürdiges Interpretationsproblem, das auftritt, wenn man einen signifikanten Interaktionseffekt, aber keinen entsprechenden Haupteffekt erhält. Dies kommt manchmal vor. Bei der in Abb. 148 gezeigten Kreuzungsinteraktion (links oben) würde man beispielsweise genau das finden. In diesem Fall wäre keiner der beiden Haupteffekte signifikant, aber der Interaktionseffekt wäre es. Diese Situation ist schwierig zu interpretieren, und die Leute sind oft etwas verwirrt. Der allgemeine Rat, den Statistiker in dieser Situation gerne geben, lautet, dass man den Haupteffekten keine große Aufmerksamkeit schenken sollte, wenn eine Interaktion vorhanden ist. Der Grund dafür ist, dass die Tests der Haupteffekte zwar aus mathematischer Sicht vollkommen gültig sind, die Haupteffekte aber bei Vorhandensein eines signifikanten Interaktionseffekts nur selten interessante Hypothesen testen. Erinnern Sie sich an den Abschnitt Welche Hypothesen testen wir?, dass die Nullhypothese für einen Haupteffekt lautet, dass die Randmittel einander gleich sind und dass ein Randmittel durch Mittelwertbildung über mehrere verschiedene Gruppen gebildet wird. Wenn Sie aber einen signifikanten Interaktionseffekt haben, dann wissen Sie, dass die Gruppen, aus denen sich das Randmittel zusammensetzt, nicht homogen sind. Daher sollten Sie sich überhaupt nicht um diese Randmittel kümmern.
Das meine ich folgendermaßen. Bleiben wir bei einem klinischen Beispiel. Nehmen wir an, wir hätten ein 2 × 2 Design, in dem wir zwei verschiedene Behandlungen für Phobien (z.B. systematische Desensibilisierung vs. flooding) und zwei verschiedene angstlösende Medikamente (z.B. Anxifree vs. Joyzepam) vergleichen. Nehmen wir nun an, wir hätten herausgefunden, dass Anxifree keine Wirkung hat, wenn Desensibilisierung die Behandlung ist, und Joyzepam keine Wirkung hat, wenn flooding die Behandlung ist. Aber beide waren bei der jeweils anderen Behandlung ziemlich wirksam. Dies ist eine klassische Crossover-Interaktion, und was wir bei der ANOVA herausfinden würden, ist, dass es keinen Haupteffekt von drug gibt, aber eine signifikante Interaktion. Was bedeutet es nun, zu sagen, dass es keinen Haupteffekt gibt? Es bedeutet, dass der durchschnittliche Effekt von Anxifree und Joyzepam derselbe ist, wenn wir den Durchschnitt über die beiden verschiedenen psychologischen Behandlungen bilden. Aber warum sollte sich jemand dafür interessieren? Bei der Behandlung von Phobien ist es nie der Fall, dass eine Person mit einem „Durchschnitt“ aus Desensibilisierung und flooding behandelt werden kann. Das macht nicht viel Sinn. Man bekommt entweder das eine oder das andere. Bei der einen Behandlung ist das eine Mittel wirksam, bei der anderen Behandlung das andere Mittel. Die Wechselwirkung ist das Wichtigste und die Hauptwirkung ist daher irrelevant.
Diese Art von Szenario gibt es häufig. Der Haupteffekt ist ein Test der Randmittel, und wenn eine Wechselwirkung vorhanden ist, sind wir oft nicht sonderlich an Randmitteln interessiert, weil sie eine Mittelwertbildung über Dinge implizieren, von denen uns die Wechselwirkung sagt, dass sie nicht gemittelt werden sollten! Natürlich ist es nicht immer so, dass ein Haupteffekt bedeutungslos ist, wenn eine Wechselwirkung vorhanden ist. Oft gibt es einen großen Haupteffekt und eine sehr kleine Interaktion. In diesem Fall kann man immer noch Dinge sagen wie „Medikament A ist im Allgemeinen wirksamer als Medikament B“ (weil es einen großen Effekt des Medikaments gab), aber man müsste es ein wenig modifizieren, indem man hinzufügt, dass „der Unterschied in der Wirksamkeit für verschiedene psychologische Behandlungen unterschiedlich war“. In jedem Fall sollten Sie bei jeder signifikanten Interaktion innehalten und darüber nachdenken, was der Haupteffekt in diesem Zusammenhang eigentlich bedeutet. Gehen Sie nicht automatisch davon aus, dass der Haupteffekt interessant oder relevant ist.