Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Einfaktorielle ANOVA mit Messwiederholung
Der einfaktorielle ANOVA mit Messwiederholung ist eine statistische Analyse zum Testen auf signifikante Unterschiede zwischen drei oder mehr Gruppen, bei der die gleichen Teilnehmer in jeder Gruppe verwendet werden (oder jeder Teilnehmer eng mit einem Teilnehmer in einer anderen experimentellen Gruppen übereinstimmt). Aus diesem Grund sollte es in jeder Versuchsgruppe immer gleich viele Punkte (Datenpunkte) geben. Diese Art von Design und Analyse wird auch als „abhängige ANOVA“ - related ANOVA - oder Innersubjekt-ANOVA - within-subjects ANOVA - bezeichnet.
Die Logik hinter einer ANOVA mit Messwiederholung ähnelt der einer unabhängigen ANOVA (manchmal als „unabhängigen ANOVA“ - independent ANOVA - oder „Zwischensubjekt-ANOVA“ - “between-subjects” ANOVA - bezeichnet). Sie werden sich erinnern, dass wir zuvor gezeigt haben, dass in einer Zwischensubjekt-ANOVA die Gesamtvariabilität in die Variabilität zwischen Gruppen (SSb) und die Variabilität innerhalb von Gruppen (SSw) aufgeteilt wird. Nachdem jede dieser Quadratsummen durch die jeweiligen Freiheitsgrade dividiert wurde, um MSb und MSw zu erhalten (siehe Tab. 16), wird der F-Bruch berechnet als:
Bei einer ANOVA mit Messwiederholung wird der F-Bruch auf ähnliche Weise berechnet. Während bei einer unabhängigen ANOVA die Variabilität innerhalb der Gruppe (SSw) die Grundlage für die MSw im Nenner bildet, wird bei einer ANOVA mit Messwiederholung die SSw in zwei Teile geteilt. Da wir in jeder Gruppe die gleichen Probanden verwenden, können wir die Variabilität aufgrund von individuellen Unterschieden zwischen den Probanden (als SSsubjects bezeichnet) von der Variabilität innerhalb der Gruppen separieren. Wir werden uns nicht zu sehr in technische Detail, wie dies gemacht wird, vertiefen. Im Prinzip wird jedes Individuum zu einer Faktorstufe. Die Variabilität auf diesem Innersubjekt-Faktor wird genauso berechnet wie jeder Zwischensubjektfaktor. Und dann können wir SSsubjects von SSw subtrahieren, was zu einer verringerten Quadratsumme SSerror beiträgt:
Diese Änderung des SSerror-Terms führt oft zu einem aussagekräftigeren statistischen Test. Dies hängt aber davon ab, ob die Reduktion der Quadratsumme SSerror durch die Erhöhung der Freiheitsgrade kompensiert wird: die Freiheitsgrade erhöhen sich von (n - k)[1] auf (n - 1)(k - 1); dabei ist aber zu berücksichtigen, dass unabhängige ANOVA-Designs typischerweise höhere Probandenzahlen haben.
Durchführen einer ANOVA mit Messwiederholung in jamovi
Zuerst brauchen wir einige Daten: Geschwind (1972) hat vorgeschlagen, dass die Art von Sprachdefiziten bei Schlaganfall-Patienten davon abhängt, welche spezifische Region des Gehirns geschädigt wurde (umgekehrt kann die Art von Defiziten verwendet werden kann, um zu diagnostizieren, welche Hirnregion von einer Läsion betroffen ist). Ein Forscher beschäftigt sich mit dem Identifizieren von spezifischen Kommunikationsschwierigkeiten von sechs Patienten, die an Broca-Aphasie leiden (ein Sprachdefizit, das häufig nach einem Schlaganfall auftritt).
Teilnehmer |
Sprachproduktion |
Semantik |
Syntax |
|---|---|---|---|
1 |
8 |
7 |
6 |
2 |
7 |
8 |
6 |
3 |
9 |
5 |
3 |
4 |
5 |
4 |
5 |
5 |
6 |
6 |
2 |
6 |
8 |
7 |
4 |
Die Patienten hatten drei Aufgaben. Im ersten Aufgabenbereich (Sprachproduktion) mussten die Patienten einzelne Wörter wiederholen, die vom Forscher laut vorgelesen wurden. Im zweiten Aufgabenbereich (Semantik), wurde das Wortverständnis getestet, und die Patienten mussten eine Reihe von Bildern der korrekten Bezeichnung zuordnen. Der dritte Aufgabenbereich (Syntax) sollte das Wissen über die korrekte Wortstellung testen, und die Patienten wurden gebeten, syntaktisch inkorrekte Sätze neu zu ordnen. Jeder Patient erhielt jeweils 10 Teilaufgaben aus allen drei Aufgabenbereichen. In welcher Reihenfolge die Patienten die Aufgaben aus den verschiedenen Bereichen durchführten, wurde zwischen den Teilnehmern balanciert. Die Anzahl der von jedem Patienten erfolgreich abgeschlossenen Teilaufgaben wird in Tab. 17 angezeigt. Geben Sie diese Daten entweder manuell in jamovi ein (oder nehmen Sie eine Abkürzung und laden Sie den Datensatz broca).
Um eine einfaktorielle ANOVA mit Messwiederholung in jamovi durchzuführen, klicken Sie ANOVA → Repeated Measures ANOVA, was das in Abb. 138 gezeigte Dialogfeld öffnet. Danach:
Geben Sie einen Namen für den Messwiederholungsfaktor unter
Repeated Measures Factors``ein (d.h., ersetzen Sie das ursprüngliche ``RM-Faktor ...mit diesem Namen). Dies sollte ein Name sein, der alle Bedingungen beschreibt, die von den Teilnehmern wiederholt wurden. Um beispielsweise die von allen Teilnehmern erledigten Sprachproduktions-, Semantik- und Syntaxaufgaben zu beschreiben, wäre eine geeignete Bezeichnung „Aufgabe“ oder „Aufgabenbereich“ (Task). Dieser neue Faktor-Name stellt die unabhängige Variable in der Analyse dar.Fügen Sie im Variablenfeld
Repeated Measures Factorseine dritte Ebene hinzu, da es drei Ebenen für die verschiedenen Aufgaben gibt und ändern Sie die Bezeichnungen der Ebenen entsprechend: Sprachproduktion (Speech), Semantik (Conceptual) und Syntax (Syntax).Verschieben Sie dann jede Variable in die ihr zugeordnete Ebene innnerhalb des Textfelds
Repeated Measures Cells.Aktivieren Sie schließlich unter den
Assumption Checks-Optionen dieSphericity checks-Checkbox.
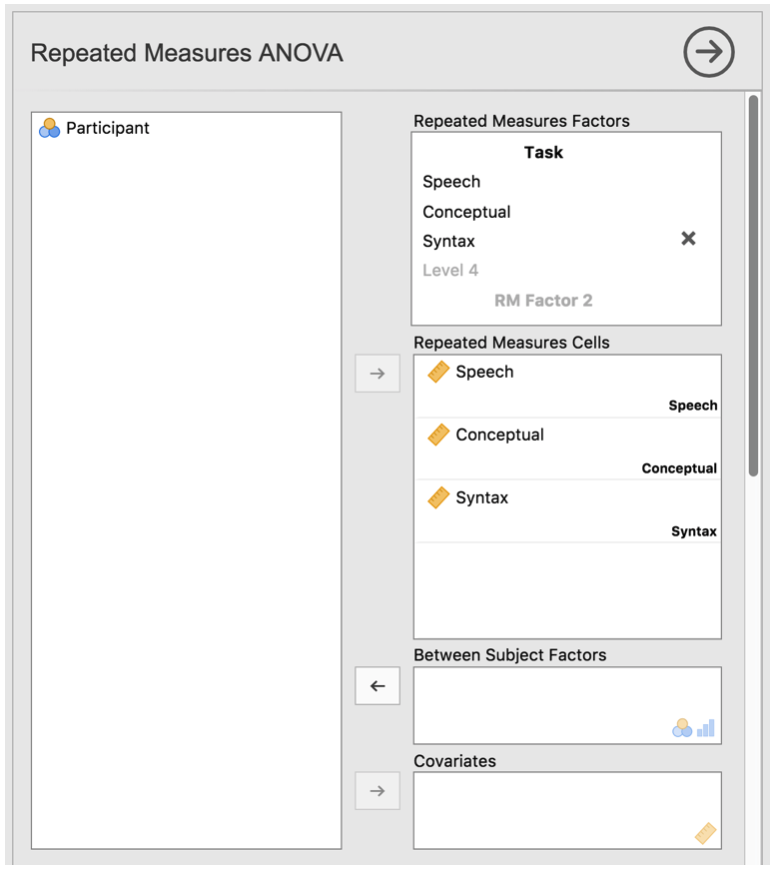
Abb. 138 Options-Dialogfeld für die ANOVA mit Messwiederholung in jamovi
Die jamovi-Ausgabe für eine einfaktorielle Repeated Measures ANOVA wird in Abb. 139 bis Abb. 142 gezeigt. Die erste Ausgabe, die wir uns ansehen sollten, ist Mauchly’s Test of Sphericity, der die Hypothese testet, dass die Unterschiede der Varianzen zwischen den Bedingungen gleich sind (was bedeutet, dass die Streuung der Differenzwerte zwischen den Studienbedingungen homogen, d.h. ungefähr gleich, ist). Laut Abb. 139 ist das Signifikanzniveau für Mauchly’s Test p = 0,720. Wenn Mauchly’s Test nicht signifikant ist (d. h. p > 0,05, wie es in dieser Analyse der Fall ist), dann können wir schlussfolgern, dass die Varianzen der Differenzen zwischen den Versuchsbedingungen nicht signifikant unterschiedlich sind (d. h. sie sind ungefähr gleich und es kann Sphärizität angenommen werden).

Abb. 139 Ausgabe der einfaktoriellen ANOVA mit Messwiederholung: Mauchly’s Test auf Sphärizität
Wenn andererseits Mauchly’s Test signifikant gewesen wäre (p < 0,05), dann würden wir schlussfolgern, dass es signifikante Unterschiede zwischen der Varianz der Differenzwerte gibt und die Anforderung der Sphärizität nicht erfüllt ist. In diesem Fall sollten wir eine Korrektur auf den F-Wert anwenden, den wir in der einfaktoriellen ANOVA erhalten haben:
Wenn der
Greenhouse-Geisser-Wert in der TabelleTests of Sphericitygrößer als 0,75 ist, sollten Sie die Huynh-Feldt-Korrektur verwenden.Aber wenn der
Greenhouse-Geisser-Wert kleiner als 0,75 ist, dann sollten Sie die Greenhouse-Geisser-Korrektur verwenden.
Diese beiden korrigierten F-Werte können durch Setzen der Checkboxen für Sphericity Corrections unter den Optionen Assumption Checks angegeben werden, und die korrigierten F-Werte werden dann in der Ergebnistabelle angezeigt, wie in Abb. 140.
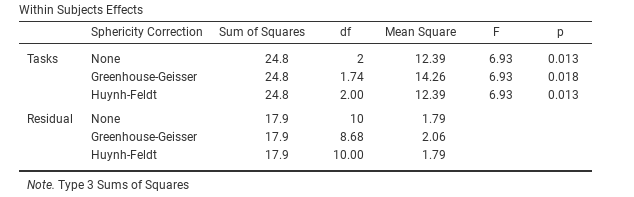
Abb. 140 Ausgabe der einfaktoriellen ANOVA mit Messwiederholung: Tests von Effekten innerhalb der Probanden
In unserer Analyse haben wir gesehen, dass die Signifikanz von Mauchly’s Tests auf Sphärizität p = 0,720 war (d. h. p > 0,05). Das bedeutet, dass wir davon ausgehen können, dass die Anforderung an die Sphärizität erfüllt ist, sodass keine Korrektur des F-Werts erforderlich ist. Daher können wir die Ausgabewerte in der Zeile ohne Sphärizitätskorrektur (Zeilenname und Checkbox None in den Optionen) für den Messwiederholungsfaktor Task verwenden: F = 6,93, df1 = 2, df2 = 10, p = 0,013. Wir können daraus schließen, dass die Zahl der erfolgreich abgeschlossenen Tests je nach Sprachaufgabe signifikant variierte, d.h. je nachdem, ob die Aufgabe produktions-, verständnis- oder syntaxbasiert war (F(2,10) = 6,93, p = 0,013).
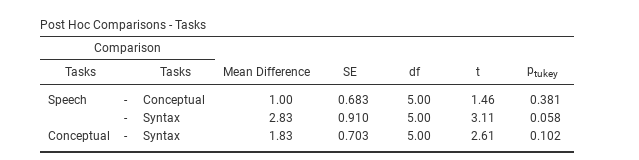
Abb. 141 Post-hoc-Tests bei der ANOVA mit Messwiederholung in jamovi
Auch bei der ANOVA mit Messwiederholung in jamovi lassen sich Post-Hoc-Tests definieren. Das geschieht auf eine ähnliche Weise, wie bei der unabhängigen ANOVA. Die Ergebnisse werden in Abb. 141 angezeigt. Diese weisen darauf hin, dass es einen signifikanten Unterschied zwischen Sprachproduktion (Speech) und Syntax (Syntax) gibt, aber nicht zwischen übrigen Ebenen.
Zur Interpretation der Ergebnisse können deskriptive Statistiken (geschätzte Randmittel) herangezogen werden, die in der jamovi-Ausgabe wie in Abb. 142 dargestellt sind. Der Vergleich der durchschnittlichen Anzahl der von den Teilnehmern erfolgreich abgeschlossenen Versuche zeigt, dass Aphasiker mit Broca-Syndrom bei den Aufgaben zur Sprachproduktion (Mittelwert = 7,17) und zum Sprachverständnis (Mittelwert = 6,17) recht gut abschneiden. Bei der Syntax-Aufgabe (Mittelwert = 4,33) waren ihre Leistungen jedoch deutlich schlechter. Ein Post-hoc-Test deutet an, dass ein signifikanter Unterschied zwischen den Leistungen bei Speech und Syntax besteht.
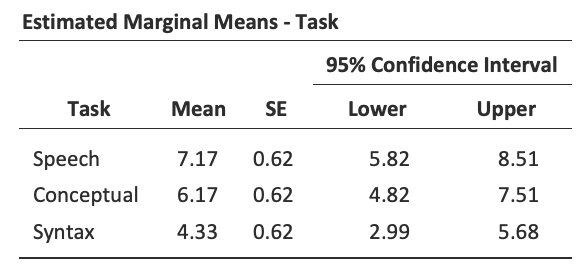
Abb. 142 Ausgabe der einfaktoriellen ANOVA mit Messwiederholung: Deskriptive Statistik