Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Prüfen nicht-normalverteilter Daten mit dem Wilcoxon-Test
Nehmen wir an, Ihre Daten erweisen sich als eher nicht normalverteilt, aber Sie wollen trotzdem so etwas wie einen t-Test durchführen? Diese Situation kommt im wirklichen Leben häufig vor. Bei den AFL-Gewinnspannen-Daten (afl.margins im Datensatz aflsmall_margins) hat der Shapiro-Wilk-Test zum Beispiel deutlich gezeigt, dass die Annahme der Normalverteilung verletzt ist. Dies ist die Situation, in der Sie den Wilcoxon-Test verwenden sollten.
Wie den t-Test gibt es auch den Wilcoxon-Test in zwei Formen, einem Ein-Stichproben- und einem Zwei-Stichproben-Test. Sie werden in mehr oder weniger genau denselben Situationen wie die entsprechenden t-Tests verwendet. Im Gegensatz zum t-Test setzt der Wilcoxon-Test keine Normalverteilung voraus, was sehr angenehm ist. Es werden darüber hinaus auch keine Annahmen über die Art der Verteilung gemacht. Im statistischen Fachjargon sind sie daher nichtparametrische Tests. Der Verzicht auf die Annahme der Normalverteilung ist zwar schön, hat aber auch einen Nachteil: Der Wilcoxon-Test ist in der Regel weniger aussagekräftig als der t-Test (d.h. er hat eine höhere Typ-II-Fehlerrate). Ich werde die Wilcoxon-Tests nicht so detailliert besprechen wie die t-Tests, aber ich werde Ihnen einen kurzen Überblick geben.
Mann-Whitney-U-Test mit zwei Stichproben
Ich beginne mit der Beschreibung des Mann-Whitney-U-Tests mit zwei Stichproben, da er einfacher ist als die Version mit einer Stichprobe. Nehmen wir an, wir betrachten die Ergebnisse von 10 Personen bei einem Test. Da meine Vorstellungskraft mich jetzt völlig im Stich gelassen hat, nehmen wir an, es handele sich um einen „Test der Unglaublichkeit“ und es gäbe zwei Gruppen von Personen, „A“ und „B“. Ich bin neugierig, welche Gruppe am unglaublichsten ist. Die Daten sind im awesome-Datensatz enthalten, und es gibt neben der üblichen ID-Variable zwei weitere Variablen: scores  und
und group  .
.
Solange es keine verbundenen Ränge gibt (d. h. Personen mit genau demselben Wert), ist der Test, den wir durchführen wollen, erstaunlich einfach. Alles, was wir tun müssen, ist eine Tabelle zu erstellen, die jede Beobachtung in Gruppe A mit jeder Beobachtung in Gruppe B vergleicht:
Gruppe B |
||||||
14.5 |
10.4 |
12.4 |
11.7 |
13.0 |
||
Gruppe A |
6.4 |
|||||
10.7 |
✓ |
|||||
11.9 |
✓ |
✓ |
||||
7.3 |
||||||
10.0 |
||||||
Dann zählen wir die Anzahl der Häkchen zusammen. Das ist unsere Teststatistik, W.[1] Die tatsächliche Stichprobenverteilung für W ist etwas kompliziert, und ich werde die Details auslassen. Für unsere Zwecke reicht es aus, festzustellen, dass die Interpretation von W qualitativ die gleiche ist wie die Interpretation von t oder z. Das heißt, wenn wir einen zweiseitigen Test wollen, dann lehnen wir die Nullhypothese ab, wenn W sehr groß oder sehr klein ist, aber wenn wir eine gerichtete (d.h. einseitige) Hypothese haben, dann verwenden wir nur das eine oder das andere.
Wenn wir in jamovi einen Independent Samples T-Test mit scores als abhängige Variable und group als Gruppierungsvariable durchführen und dann unter den Optionen für Tests die Option für Mann-Whitney U ankreuzen, erhalten wir als Ergebnis, dass U = 3 (d.h. die gleiche Anzahl von Häkchen wie oben) und einen p-Wert = 0,05556.
Wilcoxon-Test für eine Stichprobe
Was ist mit dem Wilcoxon-Test für eine Stichprobe (der gleichwertig mit dem Wilcoxon-Test für gepaarte Stichproben ist)? Angenommen, ich möchte herausfinden, ob die Teilnahme an einem Statistikkurs einen Einfluss auf die Zufriedenheit der Studenten hat. Der Datensatz happiness enthält die Zufriedenheit jedes Schülers vor (before,  ) und nach dem Besuch des Kurses (
) und nach dem Besuch des Kurses (after, ). Der change Wert ist die Differenz zwischen den beiden Werten. Genau wie wir beim t-Test für gepaarte Stichproben gesehen haben, gibt es keinen grundlegenden Unterschied zwischen einem Test für gepaarte Stichproben unter Verwendung von before und after und einem Test bei einer Stichprobe unter Verwendung der Werte in der Variable change. Wie zuvor ist die einfachste Art, den Test zu betrachten, die Erstellung einer Tabelle. Diesmal nimmt man die Änderungswerte, die positive Differenzen darstellen, und stellt sie in einer Tabelle der gesamten Stichprobe gegenüber. Das Ergebnis ist eine Tabelle, die wie folgt aussieht:
alle Unterschiede |
|||||||||||
-24 |
-14 |
-10 |
7 |
-6 |
-38 |
2 |
-35 |
-30 |
5 |
||
positive Unterschiede |
7 2 5 |
✓ |
✓ |
✓ ✓ ✓ |
✓ ✓ |
||||||
Wenn wir diesmal die Häkchen zusammenzählen, erhalten wir eine Teststatistik von W = 7. Wenn unser Test zweiseitig ist, dann lehnen wir die Nullhypothese ab, wenn W sehr groß oder sehr klein ist. Was das Durchführen in jamovi betrifft, so ist es so ziemlich genau so, wie man es erwarten würde. Für die Version mit einer Stichprobe wählen Sie die Option Wilcoxon rank unter Tests innerhalb des One Sample *t*-Test an. Dadurch erhalten Sie Wilcoxon W = 7, p-Wert = 0,03711. Wie dies zeigt, haben wir einen signifikanten Effekt. Offensichtlich hat der Besuch eines Statistikkurses einen Einfluss auf das Glücksgefühl der Teilnehmer. Wenn wir zu einer Version des Tests mit gepaarten Stichproben wechseln, erhalten wir natürlich die gleiche Antwort wie in Abb. 105 gezeigt.
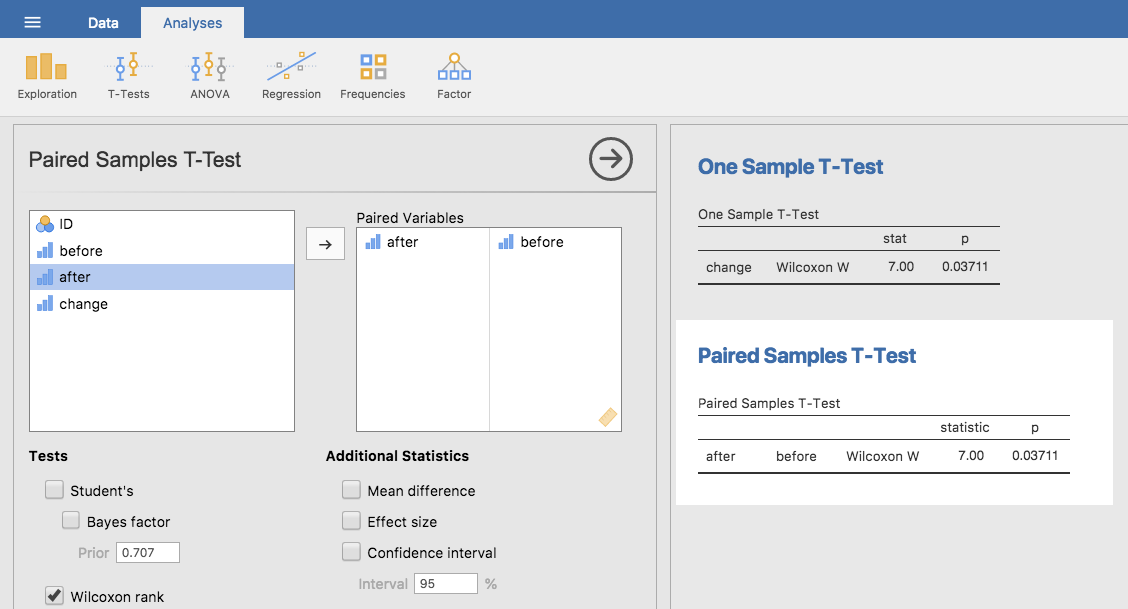
Abb. 105 jamovi-Resultatausgabe mit den Ergebnissen für die nichtparametrischen Wilcoxon-Tests mit einer Stichprobe und für gepaarte Stichproben