Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Modellauswahl
Ein ziemlich großes Problem, das bleibt, ist das Problem der „Modellauswahl“. Das heißt, wenn wir einen Datensatz haben, der mehrere Variablen enthält, welche sollten wir als Prädiktoren einbeziehen und welche nicht? Mit anderen Worten, wir haben ein Problem der Variablenauswahl. Im Allgemeinen ist die Modellauswahl ein komplexes Geschäft, aber es wird etwas einfacher, wenn wir uns auf das Problem auf die Auswahl einer Teilmenge der Variablen beschränken, die in das Modell aufgenommen werden sollten. Trotzdem werde ich nicht versuchen, auch dieses reduzierte Thema im Detail zu behandeln. Stattdessen werde ich über zwei allgemeine Prinzipien sprechen, über die Sie nachdenken müssen, und dann ein konkretes Werkzeug besprechen, das jamovi bereitstellt, um Ihnen bei der Auswahl einer Teilmenge von Variablen zu helfen, die in Ihr Modell aufgenommen werden sollen. Zunächst zu den beiden Prinzipien:
Es wäre ideal, tatsächliche, inhaltliche Gründe für Ihre Entscheidungen zu haben. In vielen Situationen haben Sie als Forscher gute Gründe, eine begrenzte Anzahl möglicher Regressionsmodelle auszuwählen, die von theoretischem Interesse sind. Diese Modelle haben eine sinnvolle Interpretation im Kontext Ihres Fachgebiets. Unterschätzen Sie niemals die Wichtigkeit davon. Statistik dient dem wissenschaftlichen Prozess, nicht umgekehrt.
In dem Maße, in dem Ihre Entscheidungen auf statistischen Schlussfolgerungen beruhen, gibt es einen Kompromiss zwischen Einfachheit und Anpassungsgüte. Wenn Sie dem Modell weitere Prädiktoren hinzufügen, wird es komplexer. Jeder Prädiktor fügt einen neuen freien Parameter hinzu (d. h. einen neuen Regressionskoeffizienten), und jeder neue Parameter erhöht die Kapazität des Modells, zufällige Variationen zu „absorbieren“. Die Anpassungsgüte (z. B. R²) steigt also an. Der Anstieg kann aber trivial oder zufällig sein, wenn Sie einfach immer mehr Prädiktoren hinzufügen. Wenn Sie möchten, dass Ihr Modell gut auf neue Beobachtungen verallgemeinern kann, müssen Sie vermeiden, zu viele Variablen einzugeben.
Dieses letztere Prinzip wird oft als Ockhams Rasiermesser (oder auch als „Prinzip der Parsimonie“) bezeichnet und oft mit dem folgenden prägnanten Spruch zusammengefasst: Multiplizieren Sie Entitäten nicht über die Notwendigkeit hinaus. In diesem Zusammenhang bedeutet dies, dass Sie nicht weitgehend irrelevante Prädiktoren zu Ihrem Modell hinzufügen sollten, nur um Ihr R² zu steigern. Ja, das Original ist prägnanter…
Was wir in jedem Fall brauchen, ist ein konkretes mathematisches Kriterium, das das qualitative Prinzip hinter Ockhams Rasiermesser im Rahmen der Auswahl eines Regressionsmodells umsetzt. Wie sich herausstellt, gibt es mehrere Möglichkeiten. Dasjenige, über das ich sprechen werde, ist das Akaike-Informationskriterium (AIC; Akaike, 1974), weil es einfach als Option in jamovi verfügbar ist.
Im Kontext eines linearen Regressionsmodells (und ohne Berücksichtigung von Termen, die in keiner Weise vom Modell abhängen!) ist der AIC für ein Modell mit K Prädiktorvariablen plus einem Schnittpunkt
Je kleiner der AIC-Wert, desto besser ist die Modellgüte. Wenn wir die Details auf niedriger Ebene ignorieren, ist es ziemlich offensichtlich, was das AIC tut. Auf der linken Seite haben wir einen Term, der zunimmt, wenn die Modellvorhersagen schlechter werden; rechts haben wir einen Term, der mit zunehmender Modellkomplexität zunimmt. Das beste Modell ist dasjenige, das gut zu den Daten passt (niedrige Residuen, linke Seite) und so wenig Prädiktoren wie möglich verwendet (niedriges K, rechte Seite). Kurz gesagt, das AIC ist eine einfache Implementierung von Ockhams Rasiermesser.
AIC kann der Model Fit Measures-Ausgabetabelle hinzugefügt werden, indem die AIC-Checkbox aktiviert wird. Eine ziemlich umständliche Methode zur Bewertung verschiedener Modelle besteht darin, zu sehen, ob der AIC-Wert niedriger ist, wenn Sie einen oder mehrere der Prädiktoren im Regressionsmodell entfernen. Dies ist derzeit der einzige Weg, der in jamovi implementiert ist, aber es gibt Alternativen in anderen Programmen wie R. Diese alternativen Methoden können den Prozess des selektiven Entfernens (oder Hinzufügens) von Prädiktorvariablen automatisieren, um das beste AIC zu finden. Obwohl diese Methoden nicht in jamovi implementiert sind, werde ich sie unten kurz erwähnen.
Rückwärtseliminierung
Bei der Rückwärtseliminierung (backward elimination) beginnen Sie mit dem Regressionsmodell inklusive aller möglichen Prädiktoren. Dann versuchen wir bei jedem „Schritt“ alle möglichen Möglichkeiten, eine der Variablen zu entfernen, und die beste davon (d.h., die mit dem niedrigsten AIC-Wert) wird akzeptiert. Dies wird unser neues Regressionsmodell, und wir probieren dann erneut alle möglichen Löschungen aus dem neuen Modell aus und wählen die Option mit dem niedrigsten AIC. Dieser Prozess wird fortgesetzt, bis wir ein Modell erhalten, das einen niedrigeren AIC-Wert hat als jedes andere mögliche Modell, das Sie durch Löschen eines seiner Prädiktoren erzeugen können.
Vorwärtsauswahl
Alternativ können Sie die Vorwärtsauswahl (forward selection) ausprobieren. Dieses Mal beginnen wir mit dem kleinstmöglichen Modell als Ausgangspunkt und berücksichtigen die möglichen Erweiterungen des Modells. Es gibt jedoch eine Komplikation: Sie müssen angeben, was das umfangreichste Modell ist, das Sie akzeptieren würden.
Obwohl Rückwärtseliminierung und Vorwärtsauswahl zum gleichen Schluss führen können, tun sie es nicht immer.
Ein Vorbehalt
Automatisierte Variablenauswahlmethoden sind verführerisch, besonders wenn sie als (ziemlich) einfache Funktionen in mächtigen Statistikprogrammen verfügbar sind. Sie verleihen Ihrer Modellauswahl ein Element der Objektivität, und das ist für viele Nutzer attraktiv. Leider werden sie oft als Entschuldigung für Gedankenlosigkeit benutzt. Sie müssen nicht mehr sorgfältig darüber nachdenken, welche Prädiktoren dem Modell hinzugefügt werden sollen und was die theoretische Grundlage für ihre Einbeziehung sein könnte. Alles wird durch die Magie von AIC gelöst. Und wenn wir anfangen, mit Phrasen wie Ockhams Rasiermesser herumzuwerfen, dann klingt es, als wäre alles in ein nettes, ordentliches kleines Paket verpackt, über das niemand anderer Meinung sein kann.
Das stimmt leider nicht. Erstens gibt es sehr wenig Einigkeit darüber, was als geeignetes Kriterium für die Modellauswahl gilt. Als mir als Student die Rückwärtselimination beigebracht wurde, haben wir dazu F-Tests verwendet, da dies die Standardmethode war, die von der Software verwendet wurde. Ich habe die Verwendung von AIC beschrieben, und da dies ein einführender Text ist, ist dies die einzige Methode, die ich beschrieben habe. Aber die AIC ist kaum das letzte Wort. Es handelt sich um eine Annäherung, die aus bestimmten Annahmen abgeleitet wird, und sie funktioniert garantiert nur für große Stichproben und wenn diese Annahmen erfüllt sind. Wenn Sie diese Annahmen ändern, erhalten Sie ein anderes Kriterium, z. B. das BIC (auch in jamovi verfügbar). Gehen Sie wieder anders vor und Sie erhalten das NML-Kriterium. Entscheiden Sie, dass Sie ein Bayesianer sind, und Sie erhalten eine Modellauswahl basierend auf den Posterior Odds Ratios. Darüber hinaus gibt es eine Reihe von weiteren regressionsspezifischen Tools, die ich nicht erwähnt habe, usw. Alle diese verschiedenen Methoden haben Stärken und Schwächen, und einige sind einfacher zu berechnen als andere (AIC ist wahrscheinlich die einfachste von allen, was für seine Popularität verantwortlich sein könnte). Fast alle von ihnen produzieren ähnliche Ergebnisse, wenn die Antwort „offensichtlich“ ist, aber es gibt eine starke Tendenz, uneinheitliche Ergebnisse zu erhalten, wenn das Problem der Modellauswahl schwierig wird.
Was bedeutet das in der Praxis? Sie können leicht mehrere Jahre damit verbringen, sich die Theorie der Modellauswahl anzueignen und alle Einzelheiten zu lernen, damit Sie endlich entscheiden könnten, was Sie persönlich für das Richtige halten. Als jemand, der das tatsächlich getan hat, würde ich es nicht empfehlen. Sie werden wahrscheinlich noch verwirrter aus diesem Prozess herauskommen als sie es jetzt sind. Eine bessere Strategie ist es, ein wenig gesunden Menschenverstand zu zeigen. Wenn Sie auf die Ergebnisse eines automatisierten Rückwärtseliminierungs- oder Vorwärtsauswahl-Verfahrens sehen und das sinnvolle Modell liegt nahe am kleinsten AIC liegt, aber wird knapp von einem Modell geschlagen, das keinen Sinn ergibt, dann vertrauen Sie Ihrem Instinkt. Die statistische Modellauswahl ist ein unpräzises Werkzeug, und wie ich eingangs sagte, kommt es auf Interpretierbarkeit an.
Vergleich zweier Regressionsmodelle
Eine Alternative zur Verwendung automatisierter Modellselektionsverfahren ist, dass der Forscher zwei oder mehr Regressionsmodelle explizit auswählt, um sie direkt miteinander zu vergleichen. Sie können dies auf verschiedene Arten tun, je nachdem, welche Forschungsfrage Sie beantworten möchten. Angenommen, wir wollen wissen, ob die Menge an Schlaf, die mein Sohn bekommen hat, in irgendeiner Beziehung zu meiner schlechten Laune steht, und zwar über das hinaus, was wir auf Grund der Menge an Schlaf erwarten könnten, die ich selbst bekommen habe. Außerdem möchten wir sicherstellen, dass der Tag, an dem wir die Messung durchgeführt haben, keinen Einfluss auf die Beziehung hat. Das heißt, wir interessieren uns für die Beziehung zwischen baby.sleep und dani.grump, und aus dieser Perspektive sind dani.sleep und day störende Variablen oder Kovariaten, für die wir kontrollieren möchten. In dieser Situation möchten wir wissen, ob dani.grump ~ dani.sleep + day + baby.sleep (das ich Modell 2 oder M2 nenne) ein besseres Regressionsmodell ist für diese Daten als dani.grump ~ dani.sleep + day (das ich Model 1 oder M1 nenne). Es gibt zwei verschiedene Möglichkeiten, diese beiden Modelle zu vergleichen, eine basierend auf einem Modellauswahlkriterium wie AIC und die andere basierend auf einem expliziten Hypothesentest. Ich zeige Ihnen zuerst den AIC-basierten Ansatz, weil er einfacher ist und sich natürlich aus der Diskussion im letzten Abschnitt ergibt. Das Erste, was ich tun muss, ist, die beiden Regressionen tatsächlich auszuführen, den AIC für jeden zu notieren und dann das Modell mit dem kleineren AIC-Wert auszuwählen, da dieses Modell als die bessere Beschreibung dieser Daten beurteilt wird. Tun Sie dies jedoch noch nicht: jamovi bietet eine einfache Möglichkeit, die AIC-Werte für verschiedene Modelle in einer Tabelle zu erhalten.[1]
Eine etwas andere Herangehensweise für das Problem bietet der Modellvergleich mittels Hypothesentests. Angenommen, Sie haben zwei Regressionsmodelle, von denen eines (Modell 1) eine Teilmenge der Prädiktoren des anderen (Modell 2) enthält. Das heißt, Modell 2 enthält alle in Modell 1 enthaltenen Prädiktoren plus einen oder mehrere zusätzliche Prädiktoren. In diesem Fall sagen wir, dass Modell 1 in Modell 2 verschachtelt ist oder dass Modell 1 möglicherweise ein Untermodell von Modell 2 ist. Unabhängig von der Terminologie bedeutet dies, dass wir an Modell 1 denken können als Nullhypothese und Modell 2 als Alternativhypothese. Und tatsächlich können wir dafür auf ziemlich einfache Weise einen F-Test konstruieren.
Wir können beide Modelle an die Daten anpassen und erhalten eine Quadratsumme der Residuen für beide Modelle. Ich bezeichne diese als SSres(1) bzw. SSres(2). Die Hochstellung hier zeigt nur an, um welches Modell es sich handelt. Dann ist unsere F-Statistik
Dabei ist N die Anzahl der Beobachtungen, p die Anzahl der Prädiktoren im vollständigen Modell (ohne Schnittpunkt) und k der Unterschied in der Anzahl der Parameter zwischen den beiden Modellen.[2] The Freiheitsgrade sind hier k und N - p - 1. Beachten Sie, dass es oft bequemer ist, sich die Differenz zwischen diesen beiden SS-Werten als eigenständige Quadratsumme vorzustellen. Das ist
Dies ist hilfreich, weil wir SSΔ als Maß dafür ausdrücken können, inwieweit die beiden Modelle unterschiedliche Vorhersagen über die Ergebnisvariable machen. Insbesondere,
wobei ŷi(1) der vorhergesagte Wert für yi gemäß Modell M1 und ŷ ist i(2) ist der vorhergesagte Wert für yi gemäß Modell M2.
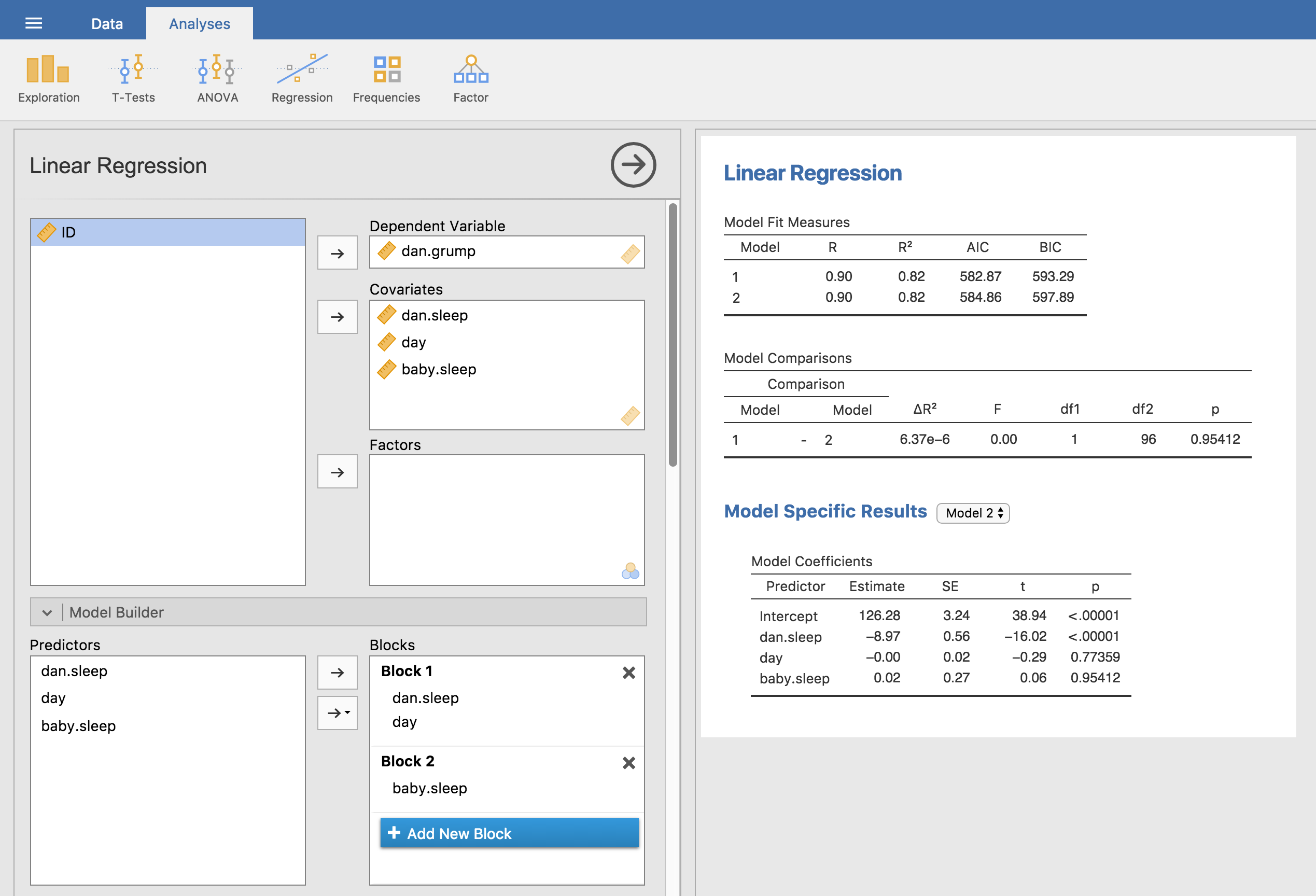
Abb. 129 Modellvergleich in jamovi mittels der Model Builder-Option
Die Formel beschreibt also den Hypothesentest, mit dem wir zwei Regressionsmodelle miteinander vergleichen. Wie machen wir das in jamovi? Die Antwort ist, die Model Builder-Option zu verwenden und die Modell-1-Prädiktoren dani.sleep und day in Block 1 anzugeben und dann den zusätzlichen Prädiktor von Modell 2 (baby.sleep) in Block 2, wie in Abb. 129. Die Tabelle Model Comparisons zeigt, dass der Vergleich zwischen Modell 1 und Modell 2 F(1,96) = 0,00, p = 0,954 ergibt. Da wir p > 0,05 haben, behalten wir die Nullhypothese (M1) bei. Dieser Regressionsansatz, bei dem wir aus allen unseren bisherigen Prädiktoren ein Nullmodell erstellen, dann die interessierenden Variablen zu einem alternativen Modell hinzufügen und danach die beiden Modelle mittels eines Hypothesentests vergleichen, wird oft als hierarchische Regression bezeichnet.
Wir können die Optionen unter Model Comparison verwenden, um eine Tabelle anzuzeigen, die den AIC und BIC für jedes Modell anzeigt. Das macht es einfach, zu vergleichen und zu identifizieren, welches Modell den niedrigsten Wert hat, wie in Abb. 129 gezeigt.