Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Konfirmatorische Faktorenanalyse
Unser Versuch, die zugrundeliegenden latenten Faktoren mithilfe der EFA mit sorgfältig ausgewählten Fragen aus dem Persönlichkeits-Item-Pool zu identifizieren, schien also recht erfolgreich zu sein. Der nächste Schritt in unserem Bestreben, ein nützliches Maß für die Persönlichkeit zu entwickeln, besteht darin, die latenten Faktoren, die wir in der ursprünglichen EFA identifiziert haben, mit einer anderen Stichprobe zu überprüfen. Wir wollen sehen, ob die Faktoren Bestand haben, ob wir ihre Existenz mit anderen Daten bestätigen können. Wie wir sehen werden, ist dies ist eine relativ strenge Überprüfung. Sie wird Konfirmatorische Faktorenanalyse (CFA) genannt, da wir, wenig überraschend, versuchen werden, eine vorher festgelegte latente Faktorenstruktur zu bestätigen.[1]
Bei der CFA führen wir keine Analyse durch, bei der wir sehen, wie die Daten im explorativen Sinne zusammenpassen, sondern wir beschreiben eine innerhalb der Daten erwartete Struktur, wie in Abb. 191, und sehen, wie gut die Daten zu dieser festgelegten Struktur passen. In diesem Sinne führen wir eine konfirmatorische Analyse durch, um zu sehen, wie gut ein vorab festgelegtes Modell durch die beobachteten Daten bestätigt wird.
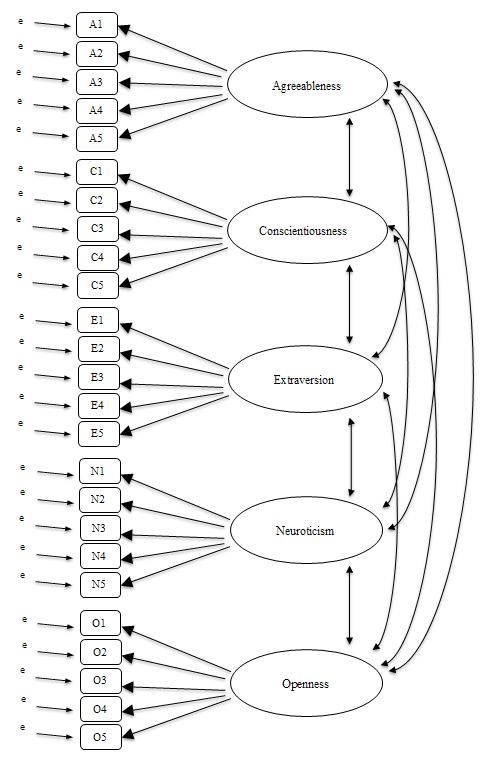
Abb. 191 Ursprüngliche Spezifizierung der latenten fünffaktoriellen Struktur für die Persönlichkeitsdaten zur Verwendung in einer CFA
Eine einfache konfirmatorische Faktorenanalyse (CFA) der Persönlichkeitselemente würde daher fünf latente Faktoren ergeben, wie in Abb. 191 dargestellt, die jeweils durch fünf beobachtete Variablen gemessen werden. Jede Variable ist ein Maß für einen zugrunde liegenden latenten Faktor. So wird zum Beispiel A1 durch den zugrunde liegenden latenten Faktor Verträglichkeit vorhergesagt. Und da A1 kein perfektes Maß für den Faktor Verträglichkeit ist, gibt es einen Fehlerterm, e, der damit verbunden ist. Mit anderen Worten: e stellt die Varianz in A1 dar, die nicht durch den Faktor Verträglichkeit abgedeckt wird. Dies wird manchmal als Messfehler bezeichnet.
Der nächste Schritt besteht darin, zu prüfen, ob die latenten Faktoren in unserem Modell korrelieren dürfen. Wie bereits erwähnt, sind in den Psychologie- und Verhaltenswissenschaften Konstrukte oft miteinander korreliert. Wir denken ebenfalls, dass einige unserer Persönlichkeitsfaktoren miteinander korreliert sein könnten. Daher werden wir in unserer Modellspezifikation zulassen, dass diese latenten Faktoren kovariieren. Dies wird durch die Doppelpfeile in Abb. 191 angezeigt.
Gleichzeitig sollten wir prüfen, ob es einen guten, systematischen Grund dafür gibt, dass einige der Fehlerterme miteinander korreliert sind. Ein Grund dafür könnte sein, dass es ein gemeinsames methodisches Merkmal für bestimmte Untergruppen der beobachteten Variablen gibt, so dass die beobachteten Variablen eher aus methodischen als aus inhaltlichen Gründen mit den latenten Faktoren korreliert sein könnten. Wir werden auf diese Möglichkeit in einem späteren Abschnitt zurückkommen, aber im Moment können wir keine eindeutigen Gründe erkennen, die es rechtfertigen würden, einige der Fehlerterme miteinander zu korrelieren.
Ohne korrelierte Fehlerterme entspricht das Modell, das wir testen, um zu sehen, wie gut es mit unseren beobachteten Daten übereinstimmt, genau dem in Abb. 191 angegeben. Es wird erwartet, dass nur die Parameter, die im Modell enthalten sind, in den Daten gefunden werden, daher werden bei CFA alle anderen möglichen Parameter (Koeffizienten) auf Null gesetzt. Wenn also diese anderen Parameter nicht Null sind (z. B. kann es in den beobachteten Daten eine beträchtliche Ladung von A1 auf den latenten Faktor Extraversion geben, aber nicht in unserem Modell), dann würden wir eine schlechte Übereinstimmung zwischen unserem Modell und den beobachteten Daten feststellen.
Schauen wir uns nun an, wie wir diese CFA-Analyse in jamovi definieren.
CFA in jamovi
Öffnen Sie den Datensatz bfi_sample2 und überprüfen Sie, ob die 25 Variablen als ordinal  (oder kontinuierlich
(oder kontinuierlich  ; für diese Analyse macht das keinen Unterschied) kodiert sind. Um eine CFA in jamovi durchzuführen:
; für diese Analyse macht das keinen Unterschied) kodiert sind. Um eine CFA in jamovi durchzuführen:
Wählen Sie
Factor→Confirmatory Factor Analysis(aus der RegisterkarteAnalyses), um das Optionsfeld zu öffnen, in dem Sie die Einstellungen für die CFA (Abb. 192) festlegen können.Wählen Sie die 5 Variablen
Aaus und übertragen Sie sie in das FeldFactorsund geben Sie ihnen die Bezeichnung „Agreeableness“ (oder „Verträglichkeit“, wenn Sie den deutschen Begriff bevorzugen).Erstellen Sie einen neuen Faktor in dem Feld
Factorsund beschriften Sie ihn mit „Conscientiousness“ (oder „Gewissenhaftigkeit“). Wählen Sie die 5 VariablenCund übertragen Sie sie in das FeldFactorsunter dem Label „Conscientiousness“.Erstellen Sie einen weiteren neuen Faktor in dem Feld
Factorsund beschriften Sie ihn mit „Extraversion“. Wählen Sie die 5 VariablenEund übertragen Sie sie in das FeldFactorsunter der Bezeichnung „Extraversion“.Erstellen Sie einen weiteren neuen Faktor in dem Feld
Factorsund beschriften Sie ihn mit „Neuroticism“ (oder „Neurotizismus“). Wählen Sie die 5 VariablenNaus und übertragen Sie sie in das FeldFactorsunter der Bezeichnung „Neuroticism“.Erstellen Sie einen weiteren neuen Faktor in dem Feld
Factorsund beschriften Sie ihn mit „Openness“ (oder „Offenheit (für Erfahrung)“). Wählen Sie die 5 VariablenOund übertragen Sie sie in das FeldFactorsunter der Bezeichnung „Openness“.Überprüfen Sie andere geeignete Optionen, die Standardeinstellungen sind für diesen ersten Durchlauf in Ordnung. Eventuell möchten Sie die Option
Path diagramunterPlotssetzen, um zu sehen, dass jamovi ein Diagramm erstellt, das dem in Abb. 191 ähnelt.
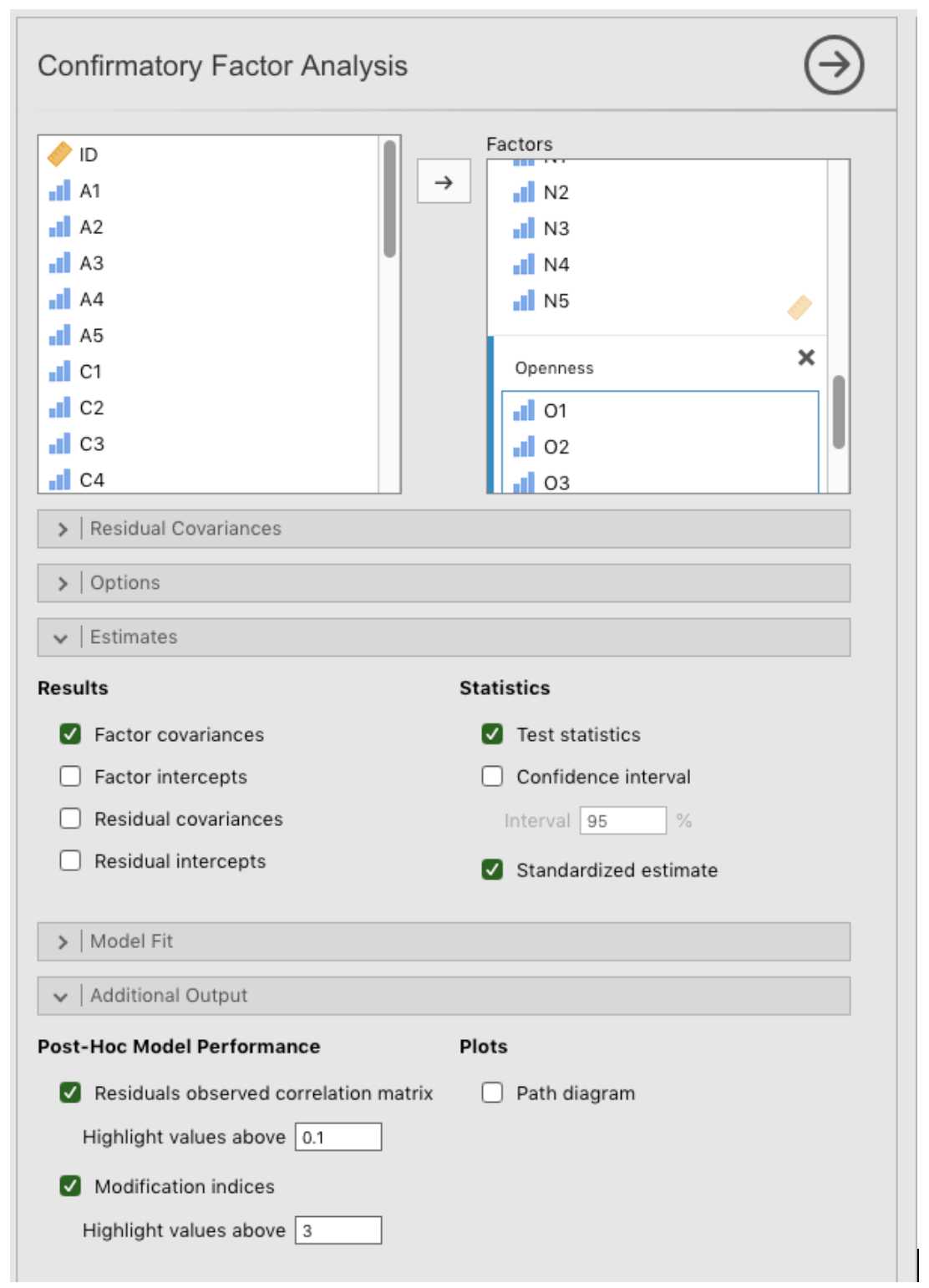
Abb. 192 Optionsfeld mit den Einstellungen zum Durchführen einer konfirmatorischen Faktorenanalyse (CFA) in jamovi
Sobald wir die Analyse definiert haben, können wir uns der jamovi-Ergebnisausgabe zuwenden. Das Erste, was wir uns ansehen sollten, ist der Model fit (Abb. 193), da dies uns sagt, wie gut unser Modell zu den beobachteten Daten passt. Beachten Sie, dass in unserem Modell nur die vorgegebenen Kovarianzen geschätzt werden, einschließlich der standardmäßigen Faktor-Korrelationen. Alles andere wird auf Null gesetzt.
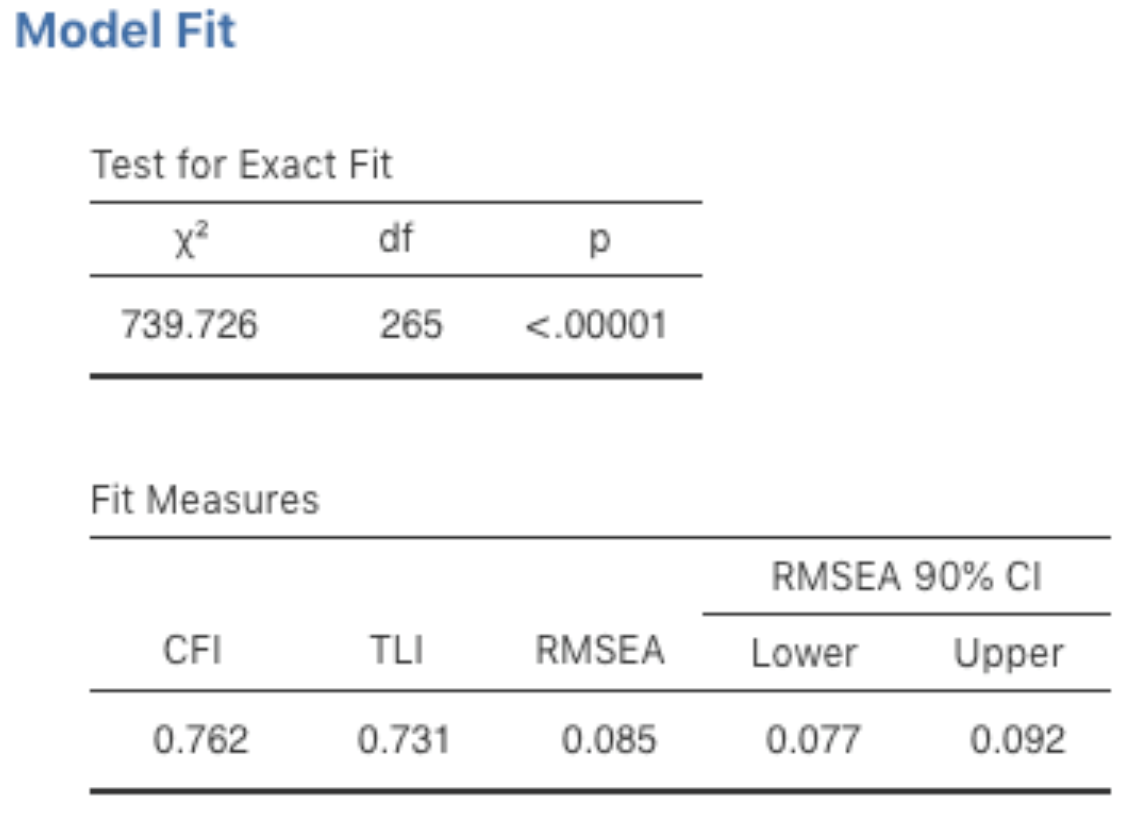
Abb. 193 Tabelle mit den Model Fit-Ergebnissen für das definierte CFA-Modell in jamovi
Es gibt mehrere Möglichkeiten, die Modellgüte zu bewerten. Die erste ist eine χ²-Statistik: Wenn sie klein ist, dann passt das Modell gut zu den Daten. Die hierbei verwendete χ²-Statistik ist jedoch ziemlich anfällig gegenüber dem Stichprobenumfang: Bei einer großen Stichprobe ergibt sich selbst bei einer ausreichend guten Anpassung zwischen dem Modell und den Daten fast immer ein großer und signifikanter (p < 0,05) χ²-Wert.
Wir brauchen also andere Methoden zur Bewertung der Modellgüte. jamovi bietet standardmäßig mehrere an. Dies sind der Comparative Fit Index (CFI), der Tucker-Lewis-Index (TLI) und der Root Mean Square Error of Approximation (RMSEA) zusammen mit dem 90%-Konfidenzintervall für den RMSEA. Einige nützliche Faustregeln besagen, dass eine zufriedenstellende Modellgüte bei CFI > 0,9, TLI > 0,9 und RMSEA von etwa 0,05 bis 0,08 gegeben ist. Eine gute Anpassung erfordert CFI > 0,95, TLI > 0,95 und RMSEA und oberer CI für RMSEA < 0,05.
Wenn wir also Abb. 193 betrachten, können wir sehen, dass der χ²-Wert groß und hochsignifikant ist. Unsere Stichprobengröße ist nicht allzu groß, so dass dies möglicherweise auf eine schlechte Anpassung hindeutet. Der CFI-Wert liegt bei 0,762 und der TLI-Wert bei 0,731, was auf eine schlechte Übereinstimmung zwischen dem Modell und den Daten hindeutet. Der RMSEA-Wert beträgt 0,085 mit einem 90%-Konfidenzintervall von 0,077 bis 0,092, was ebenfalls nicht auf eine gute Anpassung hindeutet.
Ziemlich enttäuschend, aber vielleicht nicht allzu überraschend, wenn man bedenkt, dass in der früheren EFA, die wir mit einem ähnlichen Datensatz durchgeführt haben (Abschnitt Explorative Faktorenanalyse), nur etwa die Hälfte der Varianz in den Daten durch das Fünf-Faktoren-Modell aufgeklärt werden konnte.
Betrachten wir nun die Faktorladungen und die Faktor-Kovarianz-Schätzungen, die in Abb. 194 und Abb. 195 dargestellt sind. Die Z-Statistik und der p-Wert für jeden dieser Parameter weisen darauf hin, dass sie einen angemessenen Beitrag zum Modell leisten (d. h. sie sind nicht Null). Es scheint daher keinen Grund zu geben, einen der angegebenen Variablen-Faktor-Pfade oder Faktor-Faktor-Korrelationen aus dem Modell zu entfernen. Oft sind die standardisierten Schätzungen einfacher zu interpretieren, und diese können unter der Option Estimates angewählt werden. Diese Tabellen können sinnvollerweise in einen Bericht oder einen wissenschaftlichen Artikel aufgenommen werden.
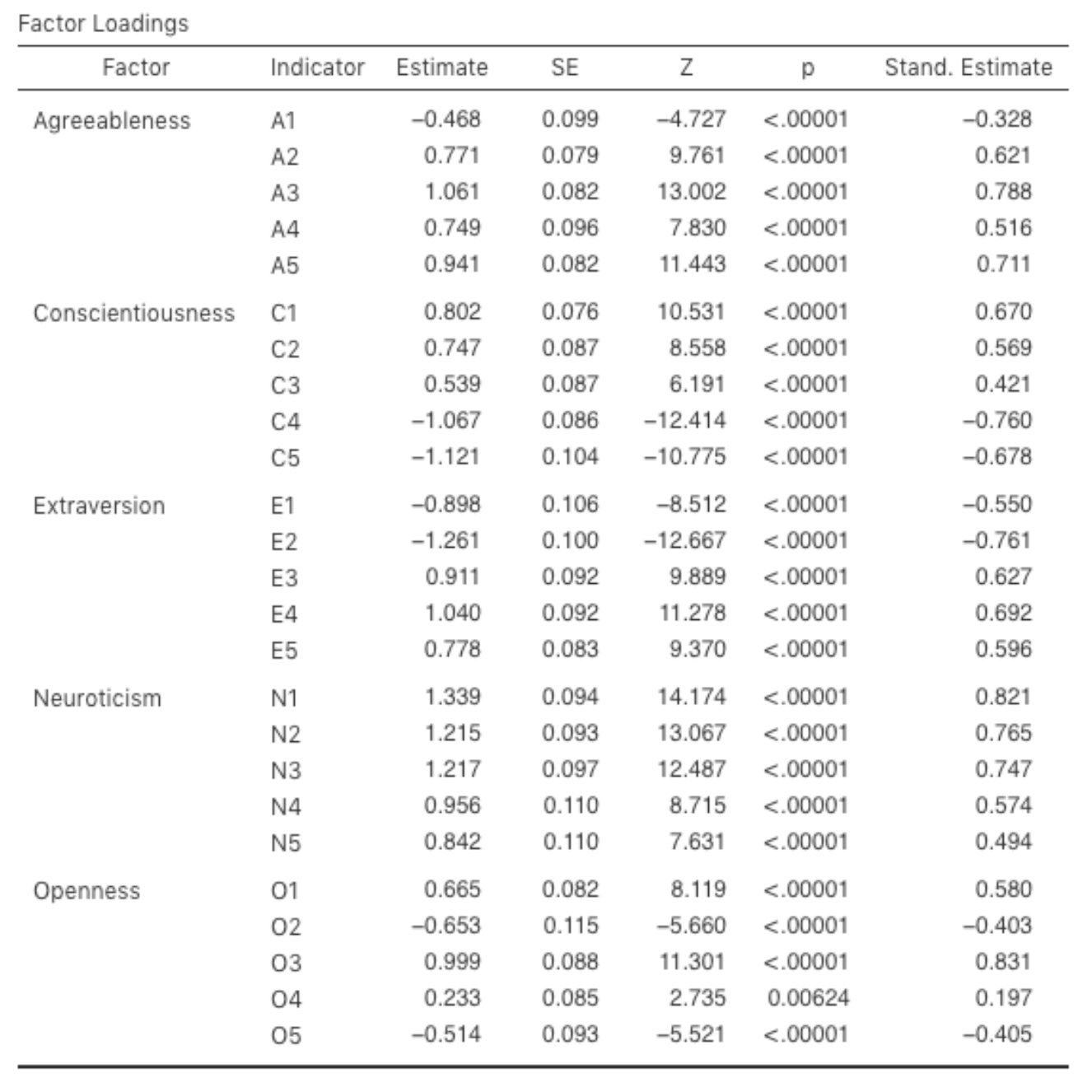
Abb. 194 Tabelle mit Factor Loadings für das definierte CFA-Modell in jamovi
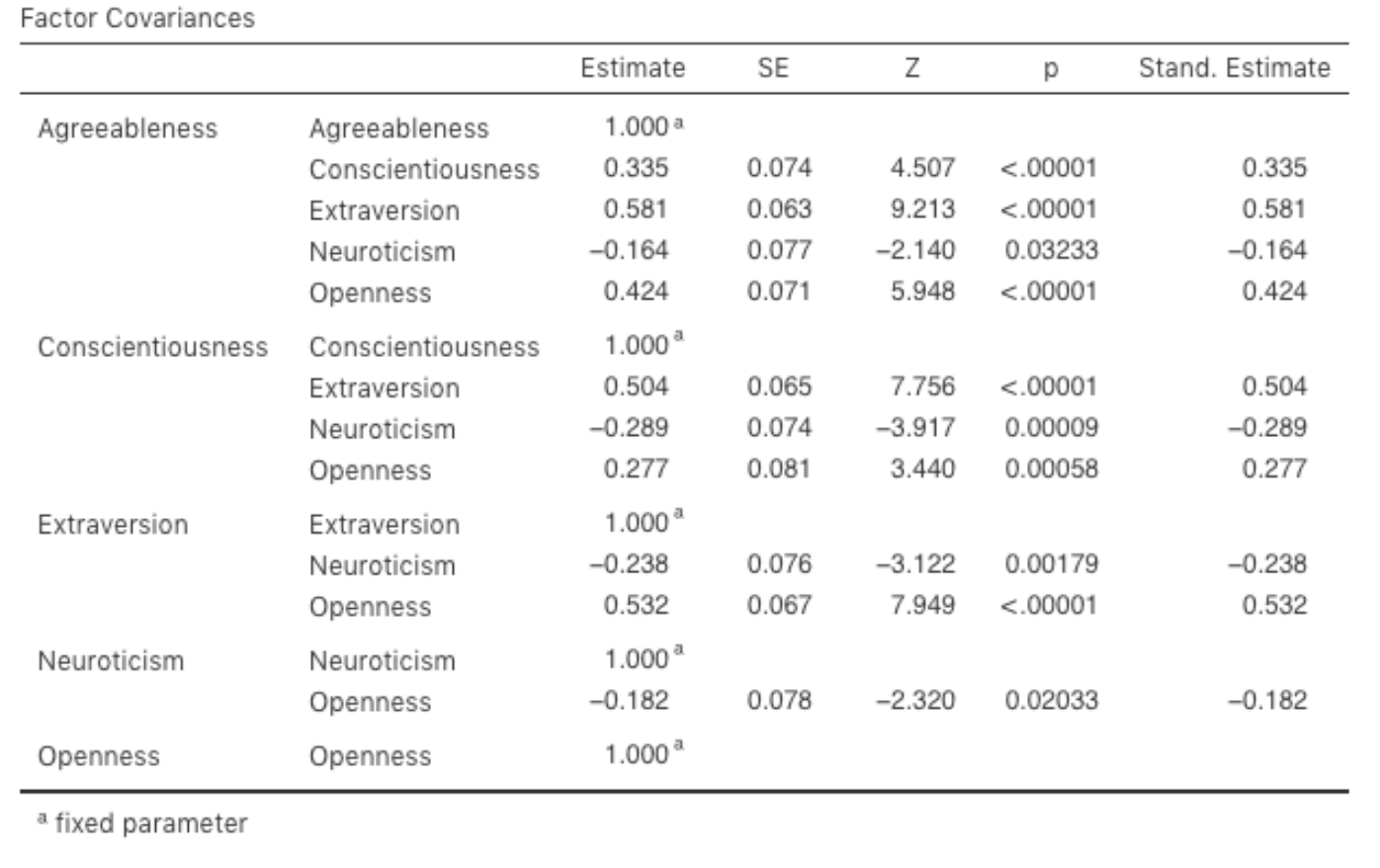
Abb. 195 Tabelle mit den Factor Covariances für das definierte CFA-Modell in jamovi
Wie könnten wir das Modell verbessern? Eine Möglichkeit besteht darin, ein paar Schritte zurückzugehen und erneut über die von uns verwendeten Items / Maße nachzudenken und zu überlegen, wie sie verbessert oder geändert werden könnten. Eine andere Möglichkeit besteht darin, einige post-hoc Anpassungen am Modell vorzunehmen, um die Passung zu verbessern. Eine Möglichkeit, dies zu tun, ist die Verwendung von Modification indices, die als Additional Output Option in jamovi angegeben werden (siehe Abb. 196).
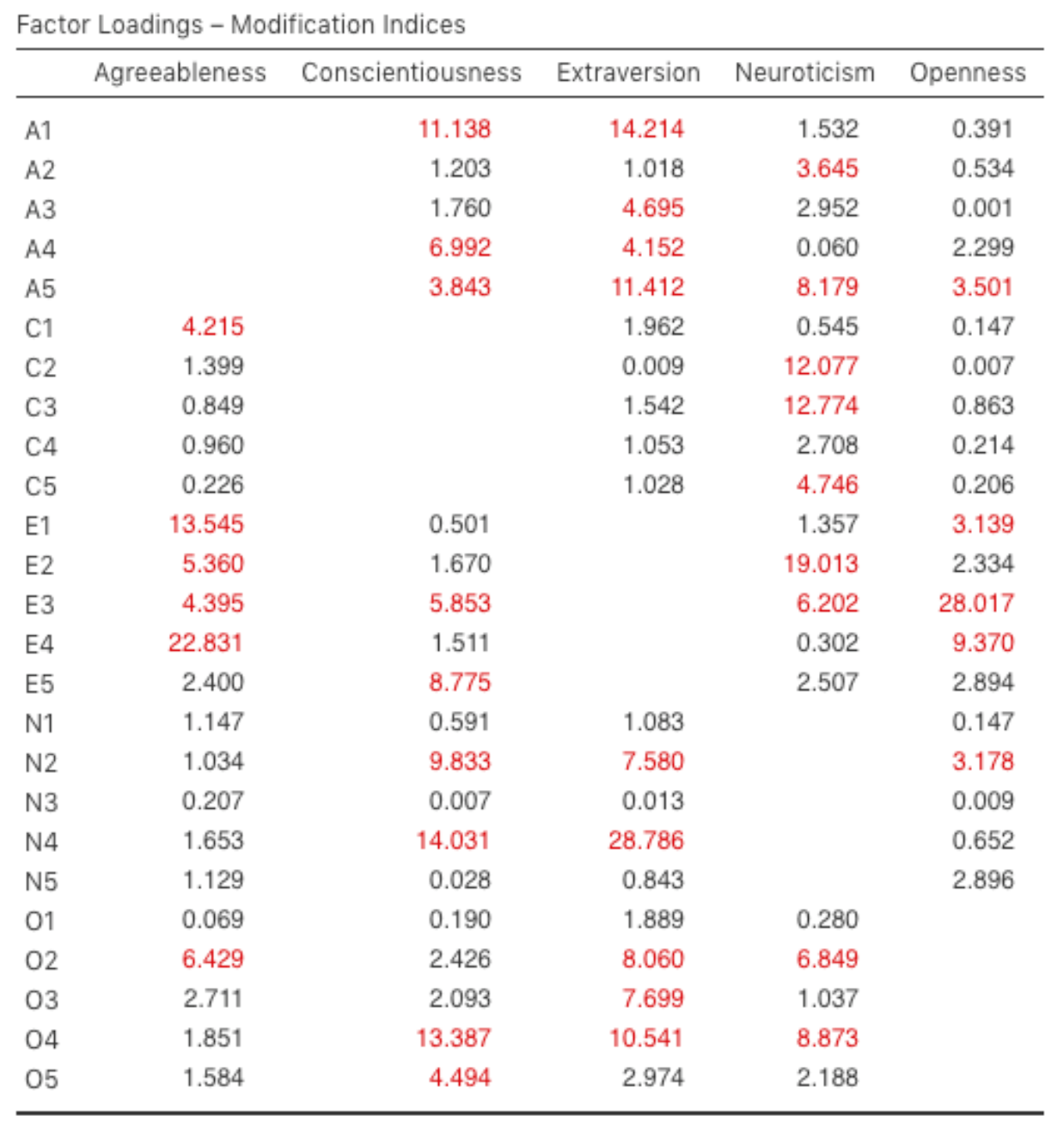
Abb. 196 Tabelle mit den Factor Loadings Modification Indices für das definierte CFA-Modell in jamovi
Was wir suchen, ist der höchste Wert des Modifikationsindex (MI). Wir würden dann beurteilen, ob es sinnvoll ist, diesen zusätzlichen Term in das Modell aufzunehmen, indem wir eine post-hoc Rationalisierung vornehmen. In Abb. 196 sehen wir zum Beispiel, dass der größte MI für die Faktorladungen, die nicht bereits im Modell enthalten sind, ein Wert von 28,786 für die Ladung von N4 („Fühle mich oft blau“) auf den latenten Faktor Extraversion ist. Dies deutet darauf hin, dass sich der χ²-Wert um etwa den gleichen Betrag verringert, wenn wir diesen Pfad in das Modell aufnehmen.
Aber in unserem Modell macht die Hinzufügung dieses Pfades theoretisch und methodisch keinen Sinn, so dass es keine gute Idee ist (es sei denn, Sie können ein überzeugendes Argument dafür vorbringen, dass „oft traurig sein“ sowohl Neurotizismus als auch Extraversion misst). Aber lassen Sie uns der Argumentation halber so tun, als ob es sinnvoll wäre, und diesen Pfad in das Modell aufnehmen. Gehen Sie zurück zum CFA-Analysefenster (siehe Abb. 192) und fügen Sie N4 in den Faktor Extraversion ein. Die Ergebnisse der CFA ändern sich nun (nicht gezeigt); der χ²-Wert ist auf etwa 709 gesunken (ein Rückgang um etwa 30, was in etwa der Größe des MI entspricht) und die anderen Anpassungsindizes haben sich ebenfalls verbessert, wenn auch nur ein wenig. Aber das ist nicht genug: Es ist immer noch kein gut passendes Modell.
Wenn Sie unter Verwendung der MI-Werte neue Parameter zu einem Modell hinzufügen, sollten Sie die MI-Tabellen nach jeder neuen Hinzufügung erneut überprüfen, da die MI-Werte jedes Mal aktualisiert werden.
Es gibt auch eine Tabelle mit den Residual Covariances Modification Indices, die von jamovi berechnet wurden (Abb. 197). Mit anderen Worten, eine Tabelle, die zeigt, welche korrelierten Fehler, wenn sie dem Modell hinzugefügt werden, die Anpassung des Modells am meisten verbessern würden. Es ist eine gute Idee, beide MI-Tabellen gleichzeitig zu betrachten, den größten MI herauszufinden, zu überlegen, ob die Hinzufügung des vorgeschlagenen Parameters vernünftig zu rechtfertigen ist, und wenn ja, ihn dem Modell hinzuzufügen. Und dann können Sie erneut nach dem größten MI in den neu berechneten Ergebnissen suchen.
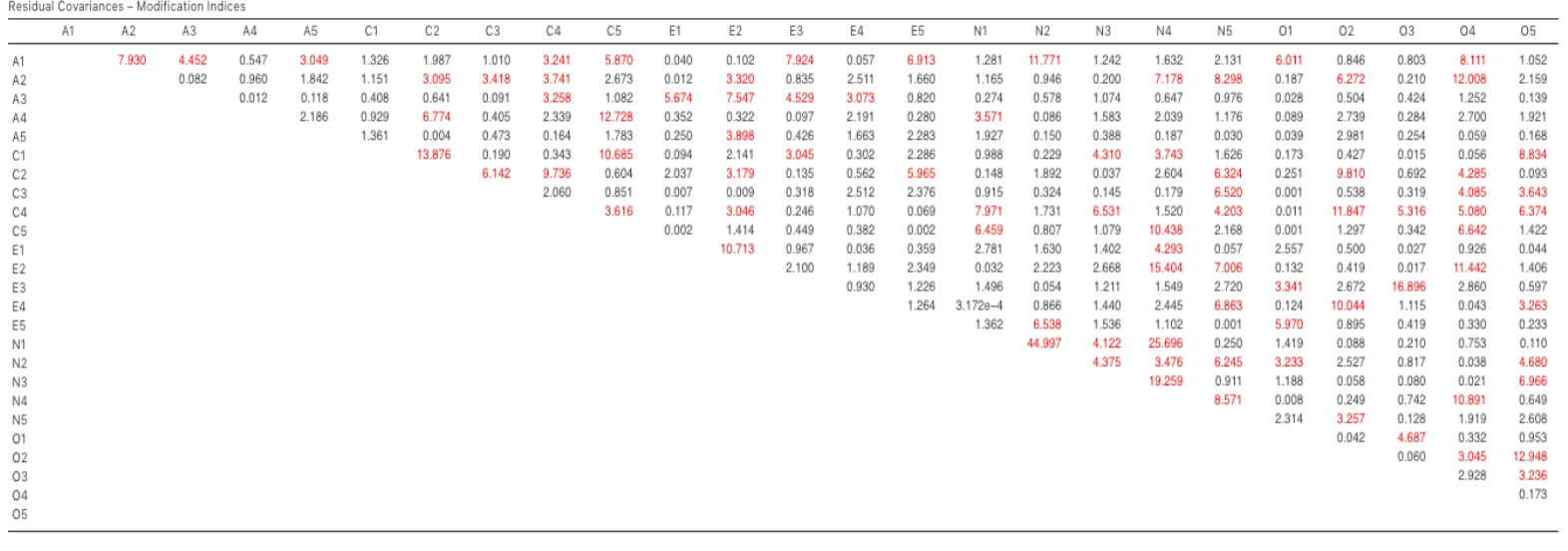
Abb. 197 Tabelle mit den Residual Covariances Modification Indices für das definierte CFA-Modell in jamovi
Sie können auf diese Weise so lange weitermachen, wie Sie wollen, und dem Modell auf der Grundlage des größten MI Parameter hinzufügen. Am Ende werden Sie eine zufriedenstellende Anpassung erreichen. Aber es besteht auch die Möglichkeit, dass Sie dabei ein Monster erschaffen haben! Ein Modell, das hässlich und deformiert ist und keinerlei theoretischen Sinn oder Reinheit aufweist. Mit anderen Worten: Überlegen Sie genau, welche Anpassungen am Modell Sie rechtfertigen können und welche wenig Sinn ergeben!
Bislang haben wir die in der EFA ermittelte Faktorenstruktur mit einer zweiten Stichprobe und der CFA überprüft. Leider konnten wir nicht feststellen, dass die Faktorenstruktur aus der EFA durch die CFA bestätigt wurde, so dass wir bei der Entwicklung dieser Persönlichkeitsskala zurück ans Reißbrett gehen müssten.
Während es manchmal gute Gründe dafür gibt, dass Residuen kovariieren (oder korrelieren) dürfen, gab es keine solche vertretbaren Gründe die CFA für das von uns definierte Modell mit Hilfe von Modifikationsindizes durch das Einbeziehen zusätzlichen Faktorladungen oder Residualkovarianzen zu „optimieren“. Lassen Sie uns trotzdem besprechen, wie man die Ergebnisse einer CFA (bei einem besser angepassten Modell) berichten würde.
Berichten einer CFA
Es gibt keine formale Standardmethode für die Erstellung eines CFA, und die Beispiele variieren je nach Disziplin und Forscher. Dennoch gibt es einige Standardinformationen, die Sie in Ihren Bericht aufnehmen sollten:
Eine theoretische und empirische Begründung für das hypothetische Modell.
Eine vollständige Beschreibung, wie das Modell spezifiziert wurde (z. B. die Indikatorvariablen für jeden latenten Faktor, Kovarianzen zwischen latenten Variablen und alle Korrelationen zwischen Fehlertermen). Ein Pfaddiagramm, wie das in Abb. 193, sollte ebenfalls enthalten sein.
Eine Beschreibung der Stichprobe (z. B. demografische Informationen, Stichprobengröße, Verfahren zur Stichprobenziehung).
Eine Beschreibung der Art der verwendeten Daten (z. B. nominal
 , kontinuierlich ) sowie Deskriptivstatistik für diese Variablen.
, kontinuierlich ) sowie Deskriptivstatistik für diese Variablen.Welche Voraussetzungen geprüft und welche Schätzmethode verwendet wurde.
Eine Beschreibung von fehlenden Werten und wie diese behandelt wurden.
Die für die Anpassung des Modells verwendete Statistiksoftware (inkl. der Versionsnummer).
Maße und Kriterien zur Beurteilung der Modellgüte.
Alle Änderungen, die am ursprünglichen Modell aufgrund von Modellanpassungs- oder Änderungsindizes vorgenommen wurden.
Alle Parameterschätzungen (d.h. Faktorladungen, Fehlervarianzen, latente (Ko-)Varianzen) sowie ihre Standardfehler, am besten in einer Tabelle.