Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Explorative Faktorenanalyse
Die Explorative Faktorenanalyse (EFA) ist ein statistisches Verfahren zur Aufdeckung verborgener latenter Faktoren, die aus den beobachteten Daten abgeleitet werden. Mit dieser Technik wird berechnet, inwieweit ein Satz gemessener Variablen, z. B. V1, V2, V3, V4 und V5, einen möglichen zugrunde liegenden latenten Faktor repräsentiert. Dieser latente Faktor kann nicht durch eine einzige beobachtete Variable gemessen werden, sondern manifestiert sich in den Beziehungen, die er in einer Reihe von beobachteten Variablen verursacht.
In Abb. 174 wird jede beobachtete Variable V bis zu einem gewissen Grad durch den zugrunde liegenden latenten Faktor (F) „verursacht“, der durch die Koeffizienten b1 bis b5 (auch Faktorladungen genannt) repräsentiert wird. Jede beobachtete Variable hat auch einen zugehörigen Fehlerterm, e1 bis e5. Jeder Fehlerterm ist der Anteil der Varianz in der zugehörigen beobachteten Variable, Vi, der durch den zugrunde liegenden latenten Faktor nicht erklärt wird.
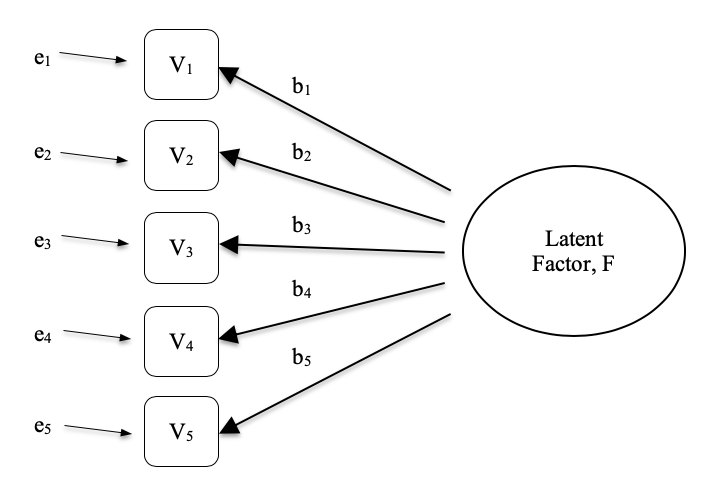
Abb. 174 Latenter Faktor, welcher der Beziehung zwischen beobachteten Variablen zugrunde liegt
In der Psychologie stehen latente Faktoren für psychologische Phänomene oder Konstrukte, die sich nur schwer direkt beobachten oder messen lassen. Zum Beispiel die Persönlichkeit, die Intelligenz oder der Denkstil. In dem Beispiel in Abb. 174 haben wir Personen fünf spezifische Fragen zu ihrem Verhalten oder ihren Einstellungen gestellt, und daraus können wir uns ein Bild über ein Persönlichkeitskonstrukt machen, das z. B. Extraversion heißt. Ein anderer Satz spezifischer Fragen kann uns ein Bild über die Introversion oder die Gewissenhaftigkeit einer Person vermitteln.
Ein weiteres Beispiel: Wir können die Angst vor Statistik vielleicht nicht direkt messen, aber wir können mit einer Reihe von Fragen in einem Fragebogen messen, ob die Angst vor Statistik hoch oder niedrig ist. Zum Beispiel: Q1: „Erledigung der Aufgabe für einen Statistikkurs“, Q2: „Versuch, die in einem Zeitschriftenartikel beschriebene Statistik zu verstehen“ und Q3: „Den Dozenten um Hilfe bitten, um etwas aus dem Kurs zu verstehen“, usw., jeweils mit einer Bewertung von geringer Angst bis zu großer Angst. Personen mit hoher Statistikangst werden aufgrund ihrer hohen bzw. geringen Statistikangst dazu neigen, jeweils ähnliche Antworten bei jeder dieser beobachteten Variablen zu geben.
Bei der explorativen Faktorenanalyse (EFA) untersuchen wir im Wesentlichen die Korrelationen zwischen den beobachteten Variablen. Weisen die beobachteten Variable eine deutliche Kovariation auf, so lassen sich interessante zugrundeliegende (latente) Faktoren aufdecken. Wir können Statistiksoftware verwenden, um diese latenten Faktoren zu schätzen und zu ermitteln, welche unserer Variablen eine hohe Ladung[1] (z. B. Ladung > 0,5) auf diesen Faktoren aufweisen, was darauf hindeutet, dass sie ein nützliches Maß oder einen guten Indikator für den latenten Faktor darstellen. Teil dieses Prozesses ist ein Schritt, der Rotation genannt wird. Um ehrlich zu sein, ist das eine ziemlich seltsame Idee, aber zum Glück müssen wir uns nicht darum kümmern, sie zu verstehen; wir müssen nur wissen, dass sie hilfreich ist, um das Muster der Ladungen auf verschiedenen Faktoren klarer zu machen. Die Rotation hilft also dabei, besser erkennen zu können, welche Variablen mit den einzelnen Faktoren substanziell verknüpft sind. Wir müssen auch entscheiden, wie viele Faktoren angesichts unserer Daten sinnvoll sind, und in diesem Zusammenhang ist etwas hilfreich, das Eigenwerte genannt wird. Auf Eigenwerte werden wir zurückkommen, nachdem wir einige der wichtigsten Annahmen der EFA behandelt haben.
Überprüfen der Voraussetzungen
Es gibt eine Reihe von Voraussetzungen, die im Rahmen einer Faktorenanalyse überprüft werden müssen. Die erste Annahme ist die Sphärizität, bei der im Wesentlichen geprüft wird, ob die Variablen in Ihrem Datensatz so weit miteinander korreliert sind, dass sie potenziell mit einem kleineren Satz von Faktoren zusammengefasst werden können. Mit dem Bartlett-Test auf Sphärizität wird geprüft, ob die beobachtete Korrelationsmatrix signifikant von einer Null-Korrelationsmatrix abweicht. Wenn also der Bartlett-Test signifikant ist (p < 0,05), bedeutet dies, dass die beobachtete Korrelationsmatrix signifikant von einer Nullmatrix abweicht und daher für die EFA geeignet ist.
Die zweite Annahme ist Stichprobenangemessenheit und wird mit dem Kaiser-Meyer-Olkin (KMO)-Maß der Stichprobenangemessenheit (MSA) überprüft. Der KMO-Index ist ein Maß für den Anteil der Varianz unter den beobachteten Variablen, bei dem es sich um gemeinsame Varianz handelt. Mit Hilfe von partiellen Korrelationen wird geprüft, ob es Faktoren gibt, die Ladungen auf nur zwei Items aufweisen. Dieser Fall ist gegeben, wenn die Korrelation zweier Variablen deutlich größer ist, als die partielle Korrelation dieser zwei Variablen, bei der für den Einfluss aller andren Variablen kontrolliert wird. Es ist selten, wenn überhaupt, erwünscht, dass die EFA eine Vielzahl von Faktoren ergibt, die jeweils nur auf zwei Items laden. Ist der KMO-Index hoch (≈ 1), lassen sich Faktoren gut mittels einer EFA extrahieren, während die Daten bei einem niedrigen KMO-Wert (≈ 0) nicht für eine EFA geeignet ist. KMO-Werte unter 0,5 bedeuten, dass die Daten nicht für eine EFA geeignet sind, und ein KMO-Wert von 0,6 sollte vorliegen, bevor die EFA als geeignet angesehen wird. Werte zwischen 0,6 und 0,7 gelten als angemessen, Werte zwischen 0,7 und 0,9 als gut und Werte zwischen 0,9 und 1,0 als ausgezeichnet.
Wozu ist die EFA gut?
Wenn die EFA eine gute Lösung (d. h. ein Faktorenmodell) ergeben hat, müssen wir entscheiden, was wir mit unseren glänzenden neuen Faktoren tun wollen. Forscher verwenden die EFA häufig bei der Entwicklung psychometrischer Skalen. Sie entwickeln einen Pool von Fragebogenitems, von denen sie glauben, dass diese sich auf ein oder mehrere psychologische Konstrukte beziehen, verwenden die EFA, um zu sehen, welche Items sich gut zu latenten Faktoren „zusammenführen“ lassen, und beurteilen dann, ob einige Items entfernt werden sollten, weil sie keinen der latenten Faktoren sinnvoll oder eindeutig messen.
In Verbindung mit diesem Ansatz besteht ein weiteres Ergebnis einer EFA darin, die Variablen, die auf unterschiedlichen Faktoren laden, jeweils zu einem Faktorwert zu kombinieren, der manchmal auch als Skalenwert bezeichnet wird. Es gibt zwei Optionen für die Kombination von Variablen zu einem Skalenwert:
Erstellen Sie eine neue Variable mit einer nach den Faktorladungen gewichteten Antwort (score) für jedes Item, das zum Faktor beiträgt.
Erstellen Sie eine neue Variable auf der Grundlage der einem Faktor zugeordneten Items, aber gewichten Sie sie diese gleich.
Bei der ersten Option hängt der Beitrag der einzelnen Items zum kombinierten Ergebnis davon ab, wie stark sie sich auf dem betreffenden Faktor laden. Bei der zweiten Option wird in der Regel einfach der Durchschnitt oder die Summe aller Antworten über die verschiedenen Items gebildet, die einen Beitrag zu diesem Faktor leisten, um die kombinierte Skalenwertvariable zu erstellen. Ein Nachteil der ersten Option ist jedoch, dass die Ladungen von Stichprobe zu Stichprobe unterschiedlich sein können. In den Verhaltens- und Gesundheitswissenschaften sind wir oft daran interessiert, zusammengesetzte Fragebogen-Skalenwerte für verschiedene Studien und verschiedene Stichproben zu entwickeln und zu verwenden. In diesem Fall ist es sinnvoll, ein zusammengesetztes Maß zu verwenden, das auf den gleichwertigen Beiträgen der wesentlichen Items basiert, anstatt sie mit stichprobenspezifischen Ladungen aus einer anderen Stichprobe zu gewichten. Auf jeden Fall ist es einfacher und intuitiver, wenn ein Durchschnitt oder eine Summe der betreffenden Items verwendet wird (im Vergleich zur Verwendung einer stichprobenspezifischen, optimal gewichteten Kombination).
Eine fortgeschrittenere statistische Technik, die den Rahmen dieses Buches sprengen würde, ist die Regressionsmodellierung, bei der latente Faktoren in Vorhersagemodellen für andere latente Faktoren verwendet werden. Diese werden als „Strukturgleichungsmodelle“ bezeichnet, und es gibt spezielle Softwareprogramme und R-Pakete für diesen Ansatz. Aber wir wollen nicht vorgreifen, sondern uns darauf konzentrieren, eine EFA in jamovi durchzuführen.
EFA in jamovi
Zunächst benötigen wir einen Datensatz: Fünfundzwanzig Persönlichkeits-Items zur Selbsteinschätzung (siehe Tab. 18) aus dem International Personality Item Pool (https://ipip.ori.org) wurden als Teil des Projekts Synthetic Aperture Personality Assessment (SAPA) zur webbasierten Persönlichkeitsbewertung (https://sapa-project.org) aufgenommen. Bei den 25 Items handelt es sich um kurze Sätze, für die man angibt, wie genau diese Aussage das eigene typische Verhalten oder die eigenen Einstellungen beschreibt. Die Items sind nach fünf mutmaßlichen Faktoren geordnet: Verträglichkeit, Gewissenhaftigkeit, Extraversion, Neurotizismus und Offenheit (für Erfahrungen).
Name |
Frage / Item |
|
|---|---|---|
A1 |
R |
Gleichgültig gegenüber den Gefühlen anderer. |
A2 |
Sich nach dem Wohlbefinden anderer erkundigen. |
|
A3 |
Wissen, wie Sie andere trösten können. |
|
A4 |
Kinder lieben. |
|
A5 |
Dafür sorgen, dass sich die Menschen wohlfühlen. |
|
C1 |
Anspruchsvoll in meiner Arbeit sein. |
|
C2 |
Fortfahren, bis alles perfekt ist. |
|
C3 |
Dinge entsprechend einem Plan erledigen. |
|
C4 |
R |
Dinge nur mit halber Kraft erledigen. |
C5 |
R |
Zeit verschwenden. |
E1 |
R |
Nicht viel reden. |
E2 |
R |
Es schwierig finden, auf andere zuzugehen. |
E3 |
Wissen, wie man Menschen fesselt. |
|
E4 |
Leicht Freunde finden. |
|
E5 |
Verantwortung übernehmen. |
|
N1 |
Leicht wütend werden. |
|
N2 |
Leicht gereizt werden. |
|
N3 |
Häufige Stimmungsschwankungen. |
|
N4 |
Sich oft traurig fühlen. |
|
N5 |
Leicht in Panik geraten. |
|
O1 |
Voller Ideen stecken. |
|
O2 |
R |
Schwierigen Lesestoff vermeiden. |
O3 |
Gespräche auf ein höheres Niveau bringen. |
|
O4 |
Zeit damit verbringen, über Dinge nachzudenken. |
|
O5 |
R |
Nicht tief in ein Thema eindringen. |
Die Daten wurden mit Hilfe einer 6-stufigen Antwortskala erhoben:
Trifft überhaupt nicht zu
Trifft nicht zu
Trifft eher nicht zu
Trifft eher zu
Trifft zu
Trifft absolut zu.
Eine Stichprobe von N = 250 Antworten ist im Datensatz bfi_sample enthalten. Neben den Items gibt es drei weitere Spalten im Datensatz: ID (die Teilnehmer-ID, eine fünfstellige Zahl) sowie das Alter (age) und das Geschlecht (gender) der Befragten.
Als Forscher sind wir daran interessiert, die Daten zu untersuchen, um zu sehen, ob es zugrundeliegende latente Faktoren gibt, die durch die 25 beobachteten Variablen im Datensatz bfi_sample einigermaßen gut repräsentiert werden. Öffnen Sie den Datensatz und überprüfen Sie, ob die 25 Variablen als kontinuierliche Variablen  kodiert sind (technisch gesehen sind sie ordinal
kodiert sind (technisch gesehen sind sie ordinal  , aber für die EFA in jamovi spielt das meist keine Rolle; eine Ausnahme ist, wenn Sie sich entscheiden, gewichtete Faktorwerte zu berechnen, in diesem Fall werden kontinuierliche Variablen benötigt). Um eine EFA in jamovi durchzuführen:
, aber für die EFA in jamovi spielt das meist keine Rolle; eine Ausnahme ist, wenn Sie sich entscheiden, gewichtete Faktorwerte zu berechnen, in diesem Fall werden kontinuierliche Variablen benötigt). Um eine EFA in jamovi durchzuführen:
Wählen Sie
Factor→Exploratory Factor Analysisaus der RegisterkarteAnalyses. Damit öffnet sich ein Optionsfeld, in dem Sie die Einstellungen für die EFA (Abb. 175) festlegen können.Wählen Sie die 25 Persönlichkeitsfragen aus und übertragen Sie diese in das Feld
Variables.Setzen Sie die entsprechenden Optionen, einschließlich
Assumption Checks, welcheRotationverwendet werden soll (unterMethod), wie viele Faktoren Sie extrahieren möchten (Number of Factors), und die Optionen unterAdditional Output(siehe Abb. 175 für vorgeschlagene Optionen für diese EFA-Beispielanalyse; beachten Sie bitte, dass, wie weiter unten beschrieben,RotationundNumber of Factorsin der Regel während der Analyse durch den Forscher angepasst werden, um ein optimales Ergebnis zu erhalten).
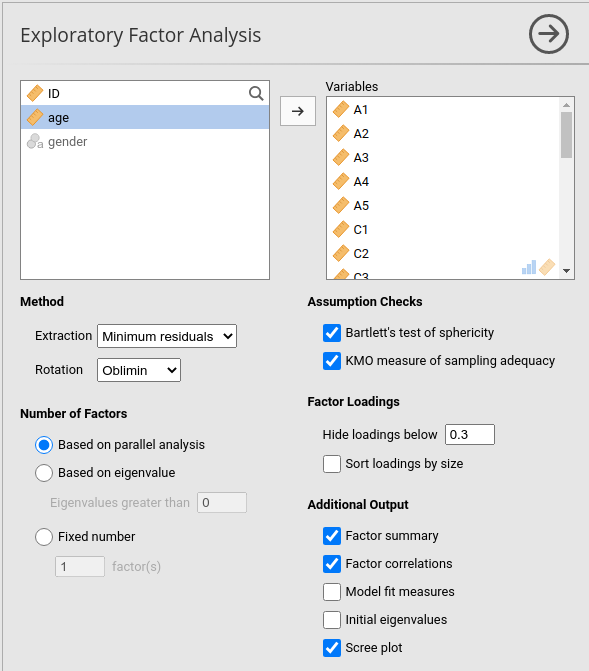
Abb. 175 Optionsfeld mit den Einstellungen zum Durchführen einer explorativen Faktorenanalyse (EFA) in jamovi
Überprüfen Sie zunächst die Annahmen (Abb. 176): Sie können sehen, dass (1) der Bartlett-Test auf Sphärizität signifikant ist, so dass diese Annahme erfüllt ist; und (2) das KMO-Maß für die Stichprobenangemessenheit (MSA) 0,81 beträgt, was darauf hindeutet, dass die Stichproben angemessen ist. Hier gibt es also keine Probleme!
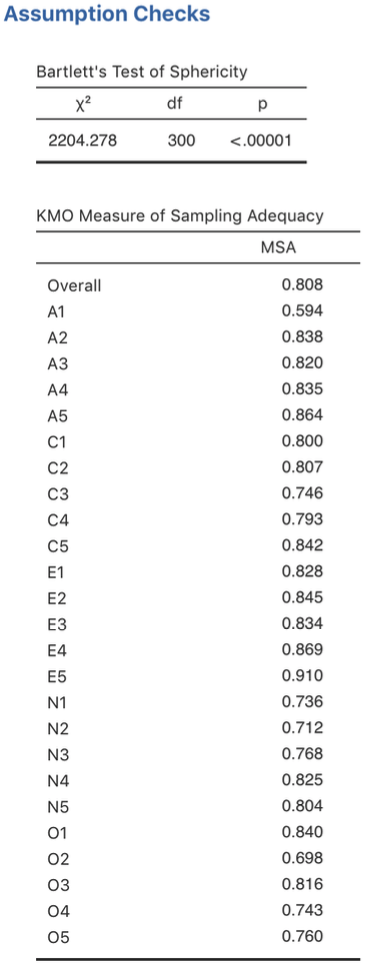
Abb. 176 Überprüfen der Voraussetzungen für eine EFA für die Daten des Persönlichkeitsfragebogens in jamovi
Als Nächstes ist zu prüfen, wie viele Faktoren verwendet (oder aus den Daten „extrahiert“) werden sollen. Es gibt drei verschiedene Ansätze:
Eine Konvention ist es, alle Komponenten mit Eigenwerten größer als 1,[2] auszuwählen. Damit würden wir aus unseren Daten vier Faktoren extrahieren (probieren Sie es aus).
Der Scree-Plot, wie in Abb. 177 gezeigt, ermöglicht es, einen „Knick“ bzw. einen „Wendepunkt“ zu identifizieren. Dies ist der Punkt, an dem die Steigung der Scree-Kurve unterhalb des „Ellenbogens“ deutlich abflacht. Dies würde bei unseren Daten fünf Faktoren ergeben. Die Interpretation von Scree-Plots erordert ein wenig Erfahrung: In Abb. 177 ist ein deutlicher Schritt von 5 auf 6 Faktoren zu erkennen, aber in anderen Scree-Plots, die Sie betrachten, ist dies nicht so eindeutig.
Mit Hilfe einer Technik der Parallelanalyse werden die aus den Daten erhaltenen Eigenwerte mit denen verglichen, die sich aus Zufallsdaten ergeben würden. Die Anzahl der extrahierten Faktoren ist die Anzahl der Eigenwerte, die größer sind als die, welche man mit Zufallsdaten erhalten würde.
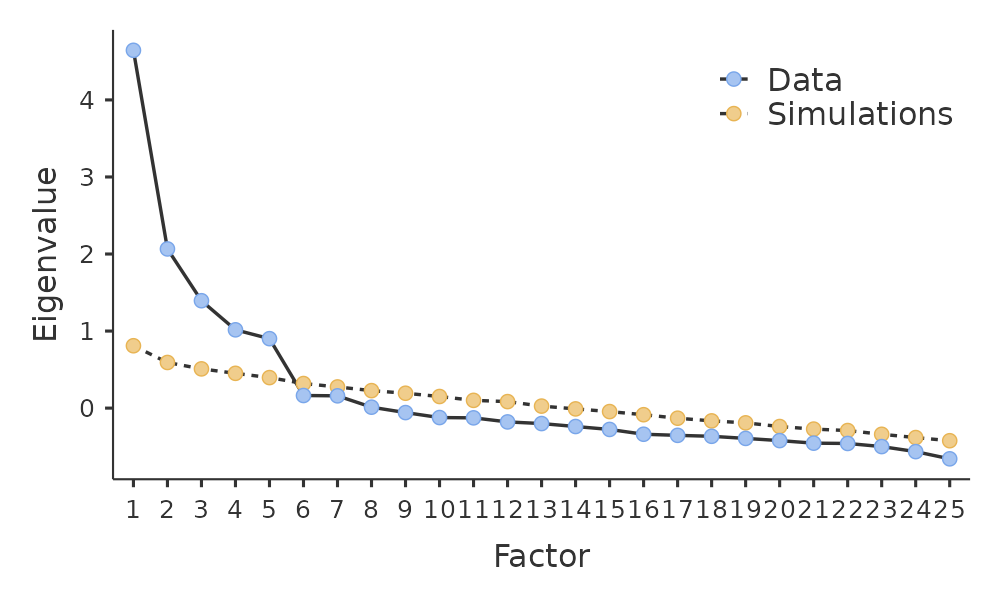
Abb. 177 Scree-Plot der Persönlichkeitsdaten während der EFA in jamovi; nach Punkt 5 zeigt sich ein deutlicher Knick und eine Abflachung (der „Ellbogen“)
Der dritte Ansatz ist laut Fabrigar et al. (1999) eine gute Herangehensweise, obwohl Forscher in der Praxis dazu neigen, alle drei Ansätze zu betrachten und dann ein Urteil über die Anzahl der Faktoren zu fällen, die am einfachsten oder hilfreichsten zu interpretieren sind. Dies kann als „Sinnhaftigkeitskriterium“ verstanden werden, und die Forscher werden in der Regel neben der Lösung aus einem der oben genannten Ansätze auch Lösungen mit einer oder zwei Faktoren mehr oder weniger untersuchen. Sie entscheiden sich dann für die Lösung, die für sie am sinnvollsten ist.
Gleichzeitig sollten wir auch überlegen, wie wir die endgültige Lösung am besten rotieren. Es gibt zwei Hauptansätze für die Rotation: Die orthogonale Rotation (z. B. Varimax) erzwingt, dass die ausgewählten Faktoren unkorreliert sind. Dagegen erlaubt die schiefwinklige Rotation (oblique; z. B. Oblimin), dass die ausgewählten Faktoren korreliert sind. Dimensionen, die für Psychologen und Verhaltenswissenschaftler von Interesse sind, sind nicht oft Dimensionen, von denen wir erwarten würden, dass sie orthogonal sind, so dass schiefwinklige Lösungen oft sinnvoller sind.[3]
Wenn sich bei einer schiefwinkligen Rotation herausstellt, dass die Faktoren erheblich korreliert sind (positiv oder negativ; mit einem Absolutwert > 0,3), wie in Abb. 178, wo die Korrelation zwischen zwei der extrahierten Faktoren 0,31 beträgt, dann würde dies unsere Intuition bestätigen, eine schräge Rotation vorzuziehen. Wenn die Faktoren tatsächlich korreliert sind, dann führt eine schräge Rotation zu einer besseren Schätzung der wahren Faktoren und einer besseren und einfacheren Struktur als eine orthogonale Rotation. Und wenn eine schiefwinklige Rotation darauf hindeutet, dass die Faktoren untereinander nahezu keine Korrelationen aufweisen, dann kann der Forscher stattdessen eine orthogonale Rotation durchführen (die dann ungefähr die gleiche Lösung wie die schiefwinklige Rotation ergeben sollte).
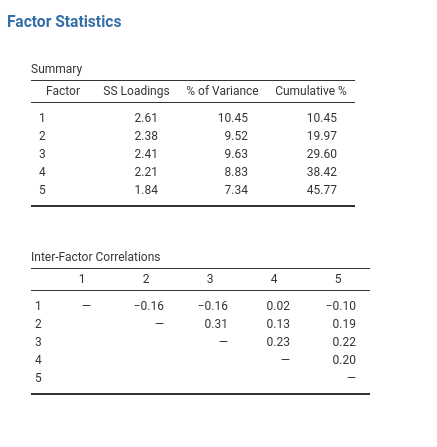
Abb. 178 Zusammenfassende Statistik der Faktoren und Korrelationen für eine EFA-Lösung mit fünf Faktoren in jamovi
Beim Überprüfen der Korrelation zwischen den extrahierten Faktoren war mindestens eine Korrelation größer als 0,3 (Abb. 178), so dass eine schiefwinklige Rotation (Oblimin) der fünf extrahierten Faktoren bevorzugt wird. Aus Abb. 178 geht auch hervor, dass der Anteil der Gesamtvarianz der Daten, der durch die fünf Faktoren erklärt wird, 46 % beträgt. Faktor eins macht etwa 10 % der Varianz aus, die Faktoren zwei bis vier jeweils etwa 9 % und Faktor fünf etwas mehr als 7 %. Dies ist nicht sehr gut; es wäre besser gewesen, wenn die Gesamtlösung einen größeren Anteil der Varianz in unseren Daten erklären würde.
Seien Sie sich bewusst, dass Sie bei jeder EFA potenziell die gleiche Anzahl von Faktoren wie beobachtete Variablen haben können. Allerdings fügt jeder zusätzliche Faktor, den Sie einbeziehen, oft nur einen relativ kleinen Betrag an erklärter Varianz hinzu. Wenn die ersten paar Faktoren einen guten Teil der Varianz in den ursprünglichen 25 Variablen erklären, dann sind diese Faktoren eindeutig ein nützlicher, einfacher Ersatz für die 25 Variablen. Sie können den Rest weglassen, ohne dass zu viel von der ursprünglichen Varianz verloren geht (unerklärt bleibt). Wenn jedoch (zum Beispiel) 18 Faktoren erforderlich sind, um den größten Teil der Varianz in diesen 25 Variablen zu erklären, dann sollten Sie eher die ursprünglichen 25 Variablen verwenden.
Abb. 179 zeigt die Faktorladungen, d.h. wie die 25 verschiedenen Persönlichkeitsmerkmale auf jedem der fünf ausgewählten Faktoren laden. Wir haben Ladungen von weniger als 0,3 ausgeblendet (in den Optionen unter Abb. 175 eingestellt).
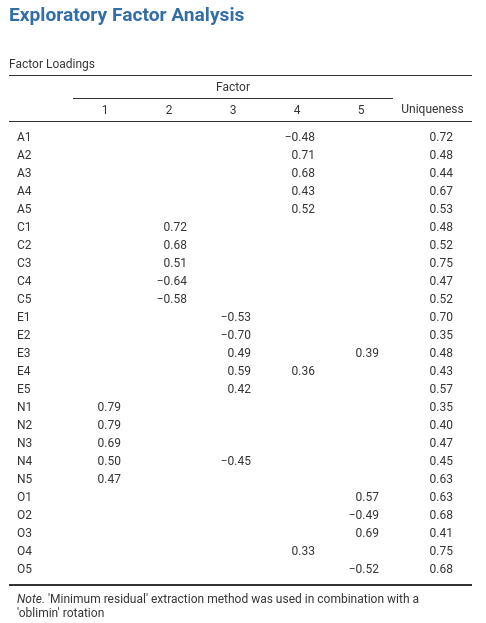
Abb. 179 Faktorladungen für eine EFA-Lösung mit fünf Faktoren in jamovi
Für die Faktoren 1, 2, 3 und 4 stimmt das Muster der Faktorladungen gut mit den in Tab. 18 angegebenen mutmaßlichen Faktoren überein. Faktor 5 ist ziemlich nahe dran, da vier der fünf beobachteten Variablen, die mutmaßlich „Offenheit (für Erfahrungen)“ messen, gut auf diesem Faktor laden. Die Variable O4 scheint allerdings nicht so gut zu passen, da die Faktorlösung in Abb. 179 darauf hindeutet, dass sie eher auf Faktor 4 (wenn auch mit einer relativ geringen Ladung), aber nicht wesentlich auf Faktor 5 lädt.
Außerdem ist zu beachten, dass die Variablen, die in Tab. 18 mit R (reverse coding) als invertiert bezeichnet wurden, negative Faktorladungen aufweisen. Schauen Sie sich die Items A1 („Gleichgültig gegenüber den Gefühlen anderer“) und A2 („Sich nach dem Wohlbefinden anderer erkundigen“) an. Wir sehen, dass ein hoher Wert bei A1 auf eine niedrige Verträglichkeit hinweist, während ein hoher Wert bei A2 (und bei allen anderen A-Variablen) auf eine hohe Verträglichkeit hinweist. Daher ist A1 negativ mit den anderen A-Variablen korreliert und hat daher eine negative Faktorladung, wie in Abb. 179 gezeigt.
In Abb. 179 können wir auch die Uniqueness jeder Variablen sehen. Mit „uniqueness“ wird der Anteil der Varianz beschrieben, der „einzigartig“ für die Variable ist und nicht durch die Faktoren erklärt wird.[4] So werden beispielsweise 72 % der Varianz von A1 nicht durch die Faktoren der fünffaktoriellen Lösung erklärt. Im Gegensatz dazu hat N1 eine relativ geringe Varianz, die nicht durch die Faktorenlösung erklärt wird (35 %). Beachten Sie, dass die Relevanz bzw. der Beitrag der Variable im Faktorenmodell umso geringer ist, je höher die Uniqueness ist.
Es ist eher ungewöhnlich, bei der EFA eine so klare (d.h., gut interpretierbare) Lösung zu erhalten. Oft sind die Lösungen unübersichtlich, und die Interpretation der Bedeutung der Faktoren ist daher eine größere Herausforderung. Es kommt nicht oft vor, dass man einen so klar umrissenen Item-Pool hat. Häufiger hat man einen ganzen Haufen beobachteter Variablen, von denen man annimmt, dass sie Indikatoren für einige zugrundeliegende latente Faktoren sind, aber man weiß nicht so genau, welche Variablen zu welchem Faktor / welcher latenten Variablen gehören!
Wir scheinen also eine ziemlich gute Lösung mit fünf Faktoren zu haben, selbst wenn sie nur einen relativ geringen Anteil an der beobachteten Varianz erklärt. Nehmen wir an, wir sind mit dieser Lösung zufrieden und möchten unsere Faktoren in der weiteren Analyse verwenden. Die einfachste Möglichkeit besteht darin, einen Gesamtwert für jeden Faktor zu berechnen, indem man die Werte für jede Variable, die substanziell auf den Faktor lädt, aufaddiert und diesen Wert dann durch die Anzahl der Variablen dividiert. Für jede Person in unserem Datensatz würde das zum Beispiel für den Faktor Verträglichkeit bedeuten, dass wir A1 + A2 + A3 + A4 + A5 addieren und dann durch 5 dividieren.[5] Das bedeutet im Wesentlichen, dass der von uns berechnete Faktorwert auf gleich gewichteten Punktzahlen für jede der einbezogenen Variablen basiert. Wir können dies in jamovi in zwei Schritten tun:
Rekodieren Sie
A1inA1Rdurch Umkehrung der Werte in der Variable (d.h. 6 = 1; 5 = 2; 4 = 3; 3 = 4; 2 = 5; 1 = 6) mit dem BefehlTransform variablein jamovi (siehe Abb. 180).Berechnen Sie eine neue Variable mit der Bezeichnung
Agreeableness, indem Sie den Mittelwert vonA1R,A2,A3,A4undA5berechnen. Verwenden Sie den jamovi-BefehlCompute, um eine neue Variable zu erstellen (siehe Abb. 181).
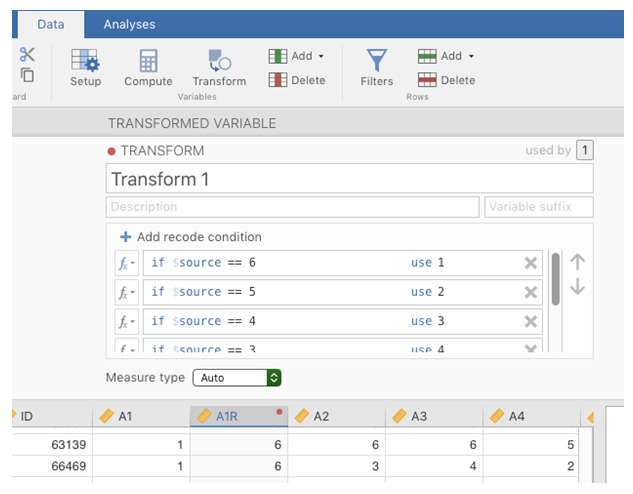
Abb. 180 Umkodierung der Variablen mit dem jamovi-Befehl Transform Variable
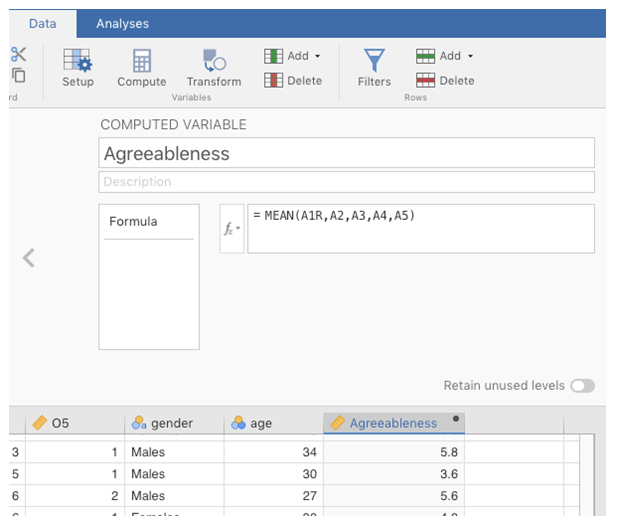
Abb. 181 Berechnung einer neuen Skalenwert-Variable unter Verwendung einer berechneten Variable in jamovi
Eine andere Möglichkeit besteht darin, einen optimal gewichteten Faktor-Score zu erstellen. Dazu können wir in R-Syntax innerhalb des jamovi Rj-Editor verwenden.[6] Auch hier sind zwei Schritte notwendig:
Benutzen Sie den Editor
Rj, um die EFA inRmit den gleichen Spezifikationen wie in jamovi auszuführen (d.h. fünf Faktoren und Oblimin-Rotation) und optimal gewichtete Faktor-Scores zu berechnen. Speichern Sie den neuen Datensatz mit den Faktorergebnissen in einer Datei (siehe Abb. 182).Öffnen Sie die neue Datei in jamovi (siehe Abb. 183) und überprüfen Sie, ob die Variablentypen korrekt gesetzt wurden. Beschriften Sie die neuen Faktor-Score-Variablen mit den entsprechenden Faktorennamen oder -definitionen (Hinweis: Es ist möglich, dass die Faktoren nicht in der erwarteten Reihenfolge stehen, überprüfen Sie dies also unbedingt).
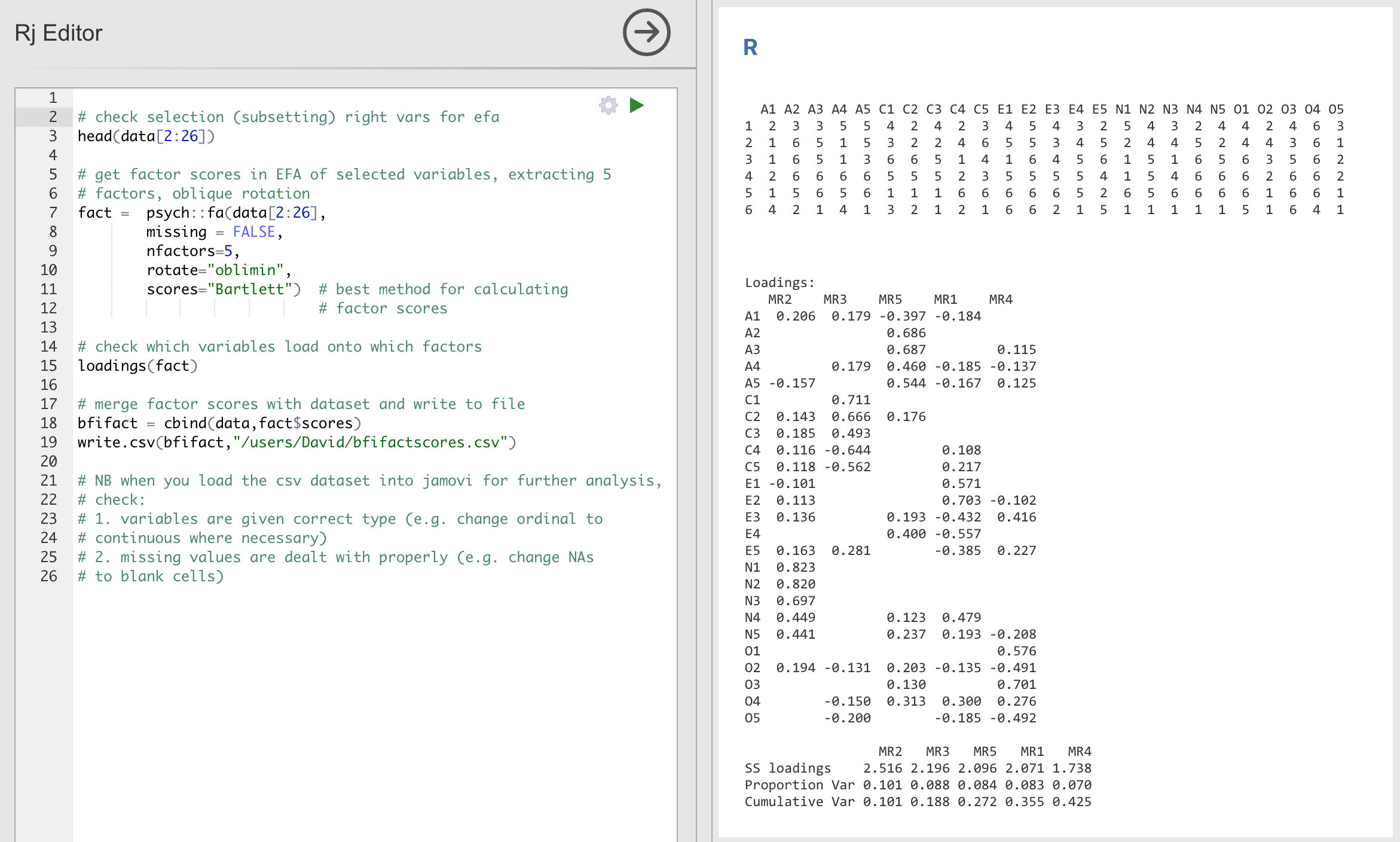
Abb. 182 Rj-Editor-Befehle für das Berechnen von optimal gewichteten Faktor-Scores für die Fünf-Faktoren-Lösung
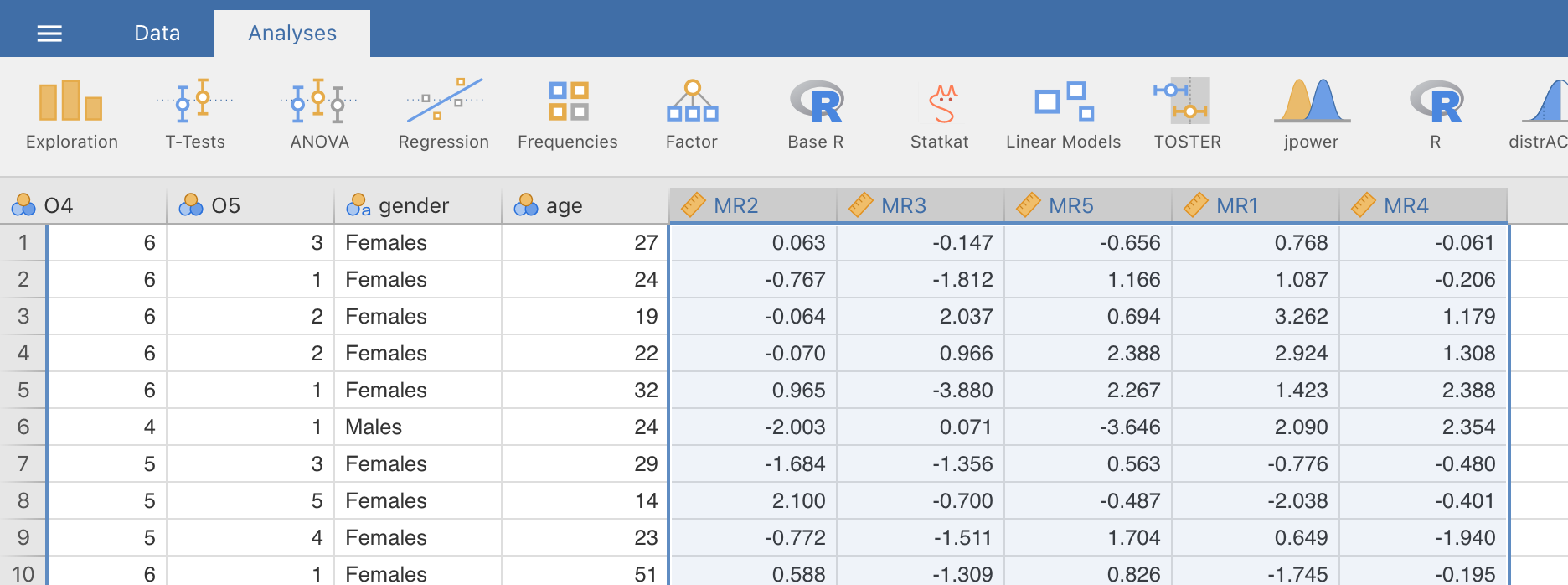
Abb. 183 Mit Hilfe der Befehle im Editor Rj erstellte Datendatei bfifactscores.csv, welche die fünf Faktor-Score-Variablen enthält. Beachten Sie, dass jede der neuen Faktor-Score-Variablen entsprechend der Reihenfolge der Faktoren in der Tabelle der Faktorladungen beschriftet ist.
Nun können Sie weitere Analysen durchführen, entweder mit den als Durchschnitt der zu einem Faktor beitragenden Variablen berechneten Skalenwerten oder mit den optimal gewichteten Faktor-Scores, die mit dem Editor Rj berechnet wurden. Sie haben die Wahl! Sie könnten zum Beispiel untersuchen, für welche unserer Persönlichkeitsdimensionen es geschlechtsspezifische Unterschiede gibt. Wir haben dies für den Wert für Verträglichkeit getan, den wir mit dem Durchschnitts-Ansatz berechnet haben, und obwohl das Diagramm (siehe Abb. 184) audeutet, dass Männer weniger verträglich sind als Frauen, war der Unterschied nicht signifikant (Mann-Whitney U = 5760.5, p = 0.073).
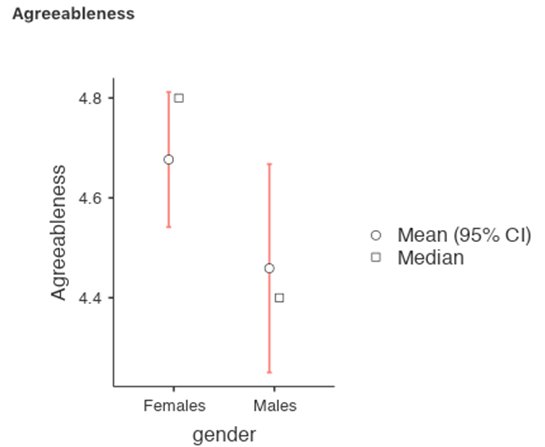
Abb. 184 Vergleich der Unterschiede zwischen Männern und Frauen in Bezug auf die Ausprägung auf dem Faktor „Verträglichkeit“
Berichten einer EFA
Hoffentlich konnten wir Ihnen einen Eindruck darüber vermitteln, was eine EFA ist und wie sie in jamovi durchgeführt wird. Wenn Sie Ihre EFA abgeschlossen haben, wie berichten Sie diese? Es gibt keine Standardmethode, um eine EFA zu berichten, und die Beispiele variieren je nach Disziplin und Forscher. Dennoch gibt es einige Informationen, die Sie in Ihren Bericht aufnehmen sollten:
Welches sind die theoretischen Grundlagen für den von Ihnen untersuchten Gegenstand und insbesondere was sind die Konstrukte, die Sie mittels der EFA untersuchen möchten?
Eine Beschreibung der Stichprobe (z. B. demografische Informationen, Stichprobengröße, Verfahren zur Stichprobenziehung).
Eine Beschreibung der Art der verwendeten Daten (z. B. nominal
 , kontinuierlich ) sowie Deskriptivstatistik für diese Variablen.
, kontinuierlich ) sowie Deskriptivstatistik für diese Variablen.Beschreiben Sie, wie Sie beim Testen der Voraussetzungen für das Durchführen einer EFA vorgegangen sind. Dies sollte Details zu Sphärizitätsprüfungen (Bartlett) und Maßen der Stichprobenangemessenheit (KMO) umfassen.
Erläutern Sie, welche FA-Extraktionsmethode verwendet wurde (z. B. Maximum Likelihood).
Erläutern Sie die Kriterien und den Prozess, nach denen entschieden wurde, wie viele Faktoren in der endgültigen Lösung extrahiert wurden und welche Items ausgewählt wurden. Erläutern Sie klar die Gründe für wichtige Entscheidungen während dieses Auswahlprozesses.
Erläutern Sie, welche Rotationsmethoden ausprobiert wurden, die Gründe dafür und die Ergebnisse.
Die endgültigen Faktorladungen sollten in den Ergebnissen in einer Tabelle angegeben werden. In dieser Tabelle sollte auch die Uniqueness (oder die Kommunalität) für jede Variable angegeben werden (in der letzten Spalte). Die Faktorladungen sollten mit beschreibenden Bezeichnungen zusätzlich zu den Item-Nummern angegeben werden. Die Korrelationen zwischen den Faktoren sollten ebenfalls angegeben werden, entweder am Ende dieser Tabelle oder in einer separaten Tabelle.
Es sollten aussagekräftige Namen für die extrahierten Faktoren angegeben werden. Es kann sein, dass Sie zuvor gewählte Faktornamen verwenden möchten. Es kann aber auch sein, dass Sie bei der Untersuchung der tatsächlichen Items und Faktoren denken, dass ein anderer Name besser geeignet ist.