Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Hauptkomponentenanalyse
Im vorigen Abschnitt haben wir gesehen, dass die EFA dazu dient, die zugrunde liegenden latenten Faktoren zu ermitteln. Und wie wir gesehen haben, kann in einem Szenario die geringere Anzahl latenter Faktoren in einer weiteren statistischen Analyse unter Verwendung einer Art von kombinierten Faktorwerten verwendet werden.
Auf diese Weise wird die EFA als „Datenreduktions“-Technik eingesetzt. Eine andere Art der Datenreduktionstechnik, die manchmal als Teil der EFA-Familie angesehen wird, ist die Hauptkomponentenanalyse (PCA). Bei der PCA werden jedoch keine zugrunde liegenden latenten Faktoren ermittelt. Stattdessen wird eine Linearkombination erstellt, die eine größere Menge von gemessenen Variablen repräsentiert.
Bei der PCA werden die ursprünglichen Daten mathematisch transformiert, ohne dass Annahmen darüber getroffen werden, wie (und warum) die Variablen kovariieren. Ziel der PCA ist es, Linearkombinationen (Komponenten) der ursprünglichen Variablen zu berechnen, die einen beobachteten Datensatz „zusammenfassen“ können, ohne dass viel Information verloren geht. Ist stattdessen die Identifizierung der zugrundeliegenden Struktur das Ziel der Analyse, dann ist die EFA vorzuziehen. Und wie wir gesehen haben, erzeugt die EFA Faktorenwerte, die genau wie die Hauptkomponentenwerte zur Datenreduktion verwendet werden können (Fabrigar et al., 1999).
Die PCA ist aus einer Reihe von Gründen in der Psychologie sehr beliebt. Deshalb lohnt es sich, sie zu behandeln, obwohl die EFA heutzutage angesichts der Leistungsfähigkeit von Computern genauso einfach durchzuführen ist. Dabei ist die EFA oft weniger anfällig für Verzerrungen als die PCA, insbesondere bei einer geringen Anzahl von Faktoren und Variablen. Wir verwenden denselben bfi_sample-Datensatz wie zuvor. Ein Großteil des Verfahrens ähnelt der EFA, so dass trotz einiger konzeptioneller Unterschiede die Schritte praktisch die gleichen sind,[1] Bei hinreichend großen Stichproben und einer ausreichenden Anzahl von Faktoren und Variablen sollten die Ergebnisse von PCA und EFA ziemlich ähnlich sein.
Durchführen einer PCA in jamovi
Nachdem Sie den Datensatz bfi_sample geladen haben, wählen Sie Factor → Principal Component Analysis (in der Registerkarte Analyses), um das Optionsfeld zu öffnen, in dem Sie die Einstellungen für die PCA festlegen können (Abb. 185). Wählen Sie dann die 25 Persönlichkeitsfragen aus und übertragen Sie diese in das Feld Variables. Wählen Sie die entsprechenden Optionen, einschließlich Assumption Checks, Rotation (unter Method), die Anzahl der zu extrahierenden Faktoren (Number of Factors), sowie die gewünschten Optionen unter Additional Output (siehe Abb. 185 für empfohlene Optionen für diese PCA; beachten Sie bitte außerdem, dass Rotation und Number of Factors normalerweise während der Analyse angepasst wird, um das beste Ergebnis zu finden; dies wird weiter unten beschrieben).
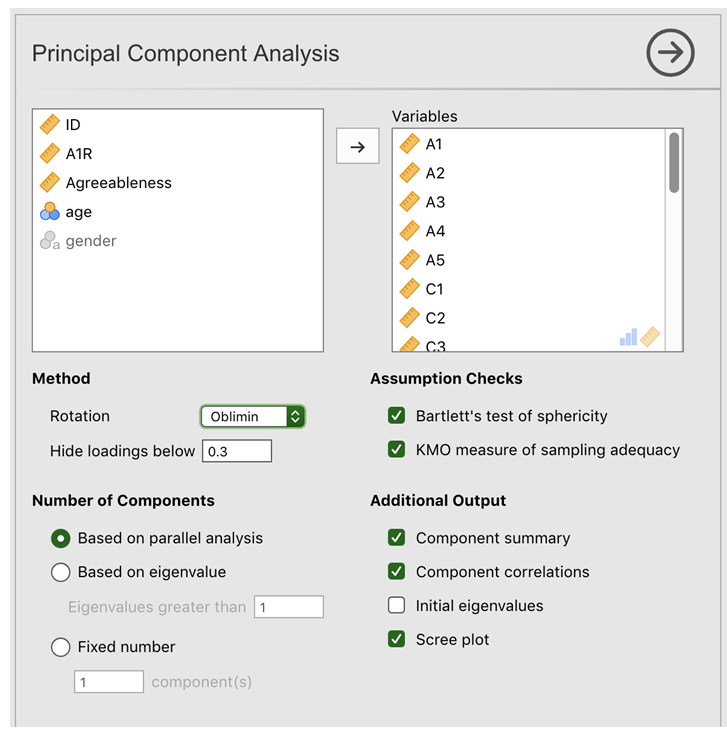
Abb. 185 Optionsfeld mit den Einstellungen für das Durchführen einer Hauptkomponentenanalyse (PCA) in jamovi
Wenn Sie zunächst die Annahmen überprüfen (siehe Abb. 186), können Sie feststellen, dass (1) der Bartlett-Test auf Sphärizität signifikant ist, so dass diese Annahme erfüllt ist; und (2) das KMO-Maß für die Angemessenheit der Stichprobe (MSA) 0,81 beträgt, was darauf hindeutet, dass die Stichprobe angemessen ist. Hier gibt es also keine Probleme!
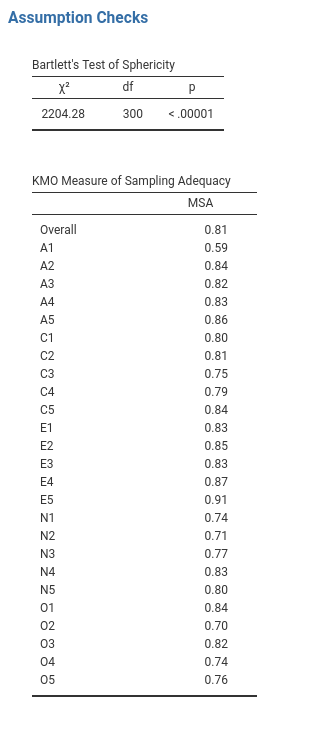
Abb. 186 Überprüfung der Voraussetzungen für das Durchführen einer PCA mit den Persönlichkeits-items in jamovi
Als Nächstes ist zu prüfen, wie viele Komponenten verwendet (oder aus den Daten „extrahiert“) werden sollen. Wie bei der EFA gibt es auch hier drei verschiedene Ansätze:
Eine Konvention besteht darin, alle Komponenten mit Eigenwerten größer als 1 auszuwählen, was bei unseren Daten zu zwei Komponenten führen würde.
Die Untersuchung des Scree Plots, wie in Abb. 187, ermöglicht es Ihnen, den „Knick“ oder „Wendepunkt“ zu identifizieren. Dies ist der Punkt, an dem die Steigung der Scree-Kurve unterhalb des „Ellenbogens“ deutlich abflacht. Auch hier würden wir zwei Komponenten erhalten, da die Abflachung eindeutig nach der zweiten Komponente erfolgt.
Mit Hilfe der Technik der Parallelanalyse werden die erhaltenen Eigenwerte mit denen verglichen, die sich aus Zufallsdaten ergeben würden. Die Anzahl der extrahierten Komponenten ist die Anzahl der Eigenwerte, die größer sind als die, welche man mit Zufallsdaten erhalten würde.
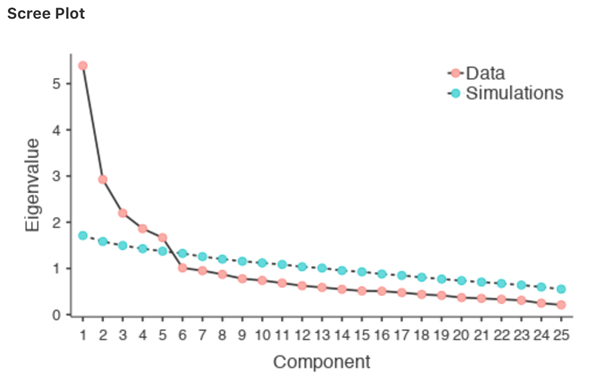
Abb. 187 Scree-Plot der Persönlichkeits-Items beim Durchführen einer PCA in jamovi; er zeigt den Nivellierungspunkt, den „Ellenbogen“, nach Komponente 5
Der dritte Ansatz ist laut Fabrigar et al. (1999) eine gute Herangehensweise, obwohl Forscher in der Praxis dazu neigen, alle drei Ansätze zu betrachten und dann ein Urteil über die Anzahl der Komponenten zu fällen, die am einfachsten oder hilfreichsten zu interpretieren sind. Dies kann als „Sinnhaftigkeitskriterium“ verstanden werden, und die Forscher werden in der Regel neben der Lösung aus einem der oben genannten Ansätze auch Lösungen mit einer oder zwei Komponenten mehr oder weniger untersuchen. Sie entscheiden sich dann für die Lösung, die für sie am sinnvollsten ist.
Gleichzeitig sollten wir überlegen, wie wir die endgültige Lösung am besten drehen. Auch hier gibt es, wie bei der EFA, zwei Hauptansätze für die Rotation: orthogonale (z. B. Varimax) Rotation erzwingt, dass die ausgewählten Komponenten unkorreliert sind, während schiefwinklige (z. B. Oblimin) Rotation erlaubt, dass die ausgewählten Komponenten korreliert sind. Dimensionen, die für Psychologen und Verhaltenswissenschaftler von Interesse sind, sind nicht oft Dimensionen, von denen wir erwarten würden, dass sie orthogonal sind. Daher sind schiefwinklige Lösungen oft sinnvoller. Sollte sich in der Praxis herausstellen, dass die Komponenten bei einer schiefwinkligen Rotation stark korreliert sind (d. h. > 0,3), würde dies unsere Intuition bestätigen, eine schiefwinklige Rotation zu bevorzugen. Wenn die Komponenten tatsächlich korreliert sind, dann führt eine schiefwinklige Rotation zu einer besseren Schätzung der wahren Komponenten und einer besseren einfachen Struktur als eine orthogonale Rotation. Wenn die schiefwinklige Rotation stattdessen darauf hindeutet, dass die Komponenten untereinander kaum korreliert sind, dann kann man eine orthogonale Rotation durchführen (die dann in etwa die gleiche Lösung wie die schiefwinklige Rotation ergeben sollte). In Abb. 188 sehen wir, dass keine der Korrelationen > 0,3 ist, so dass eine orthogonale Rotation (Varimax) als angemessener erscheint.
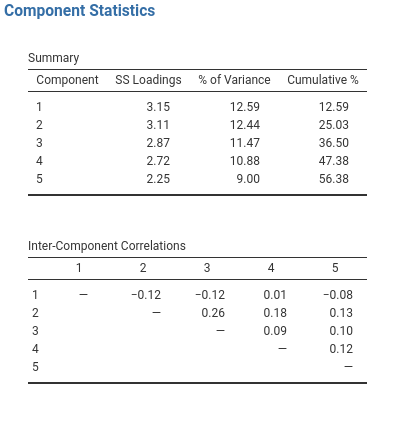
Abb. 188 Zusammenfassende Komponentenstatistiken und Korrelationen für eine Fünf-Komponenten-Lösung beim Durchführen einer PCA mit den Persönlichkeitsdaten in jamovi
In Abb. 188 ist auch der Anteil der Gesamtvarianz der Daten angegeben, der auf die beiden Komponenten entfällt. Die Komponenten eins und zwei machen jeweils etwas mehr als 12 % der Varianz aus. Zusammengenommen macht die Fünf-Komponenten-Lösung etwas mehr als die Hälfte der Varianz (56 %) in den beobachteten Daten aus. Beachten Sie, dass Sie in jeder PCA potenziell die gleiche Anzahl von Komponenten wie beobachtete Variablen haben können, aber jede zusätzliche Komponente, die Sie einbeziehen, fügt einen kleineren Betrag an erklärter Varianz hinzu. Wenn die ersten paar Komponenten einen guten Teil der Varianz in den ursprünglichen 25 Variablen erklären, dann sind diese Komponenten eindeutig ein nützlicher, einfacher Ersatz für alle 25 Variablen. Sie können den Rest weglassen, ohne zu viel von der ursprünglich erklärten Varianz zu verlieren. Wenn jedoch 18 Komponenten erforderlich sind, um den größten Teil der Varianz in diesen 25 Variablen zu erklären, können Sie genauso gut nur die ursprünglichen 25 verwenden.
Abb. 189 zeigt die Komponentenladungen. Das heißt, wie sich die 25 verschiedenen Persönlichkeits-Items auf jede der ausgewählten Komponenten auswirken. Wir haben Ladungen unter 0,4 (in den Optionen unter Abb. 185 eingestellt) ausgeblendet, da wir an Elementen mit einer substanziellen Ladung interessiert waren und die Einstellung des Schwellenwerts auf den höheren Wert von 0,4 auch eine sauberere, klarere Lösung bot.
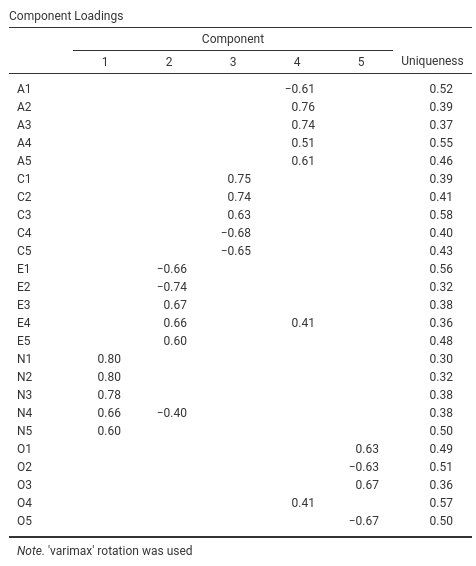
Abb. 189 Komponentenladungen für eine Fünf-Komponenten-Lösung beim Durchführen einer PCA mit den Persönlichkeitsdaten in jamovi
Für die Komponenten 1, 2, 3 und 4 stimmt das Muster der Komponentenladungen eng mit den in Tab. 18 angegebenen mutmaßlichen Faktoren überein. Und Komponente 5 ist ziemlich nahe dran, da vier der fünf beobachteten Variablen, die mutmaßlich „Offenheit (für Erfahrungen)“ messen, ziemlich gut auf die Komponente laden. Die Variable O4 scheint jedoch nicht ganz zu passen, da die Komponentenlösung in Abb. 189 darauf hindeutet, dass sie auf Komponente 4 (wenn auch mit einer relativ geringen Ladung), aber nicht wesentlich auf Komponente 5 lädt.
Wir können auch in Abb. 185 die Uniqueness jeder Variablen sehen. Dieses Maß beschreibt den Anteil der Varianz, der „einzigartig“ (unique) für die Variable ist und nicht durch die Komponenten erklärt wird. So werden zum Beispiel 52 % der Varianz von A1 nicht durch die Komponenten der Fünf-Komponenten-Lösung erklärt. Im Gegensatz dazu hat N1 eine relativ geringe Varianz, die nicht durch die Komponentenlösung erklärt wird (30 %). Beachten Sie, dass die Relevanz oder der Beitrag der Variable im Komponentenmodell umso geringer ist, je größer Uniqueness ist.
Wir hoffen, dass Sie einen guten ersten Eindruck davon bekommen haben, wie die PCA in jamovi durchgeführt werden kann und dass sie sich konzeptionell von der EFA unterscheidet, während die Ergebnisse (mit den richtigen Daten) denen einer EFA recht ähnlich sind.
Die Erstellung und Speicherung von Komponentenscores erfolgt in ähnlicher Weise wie bei der EFA. Wenn Sie jedoch die Option wählen, einen optimal gewichteten Komponenten-Score-Index zu erstellen, sind die Befehle und die Syntax im jamovi Rj-Editor ein wenig anders. Siehe Abb. 190.
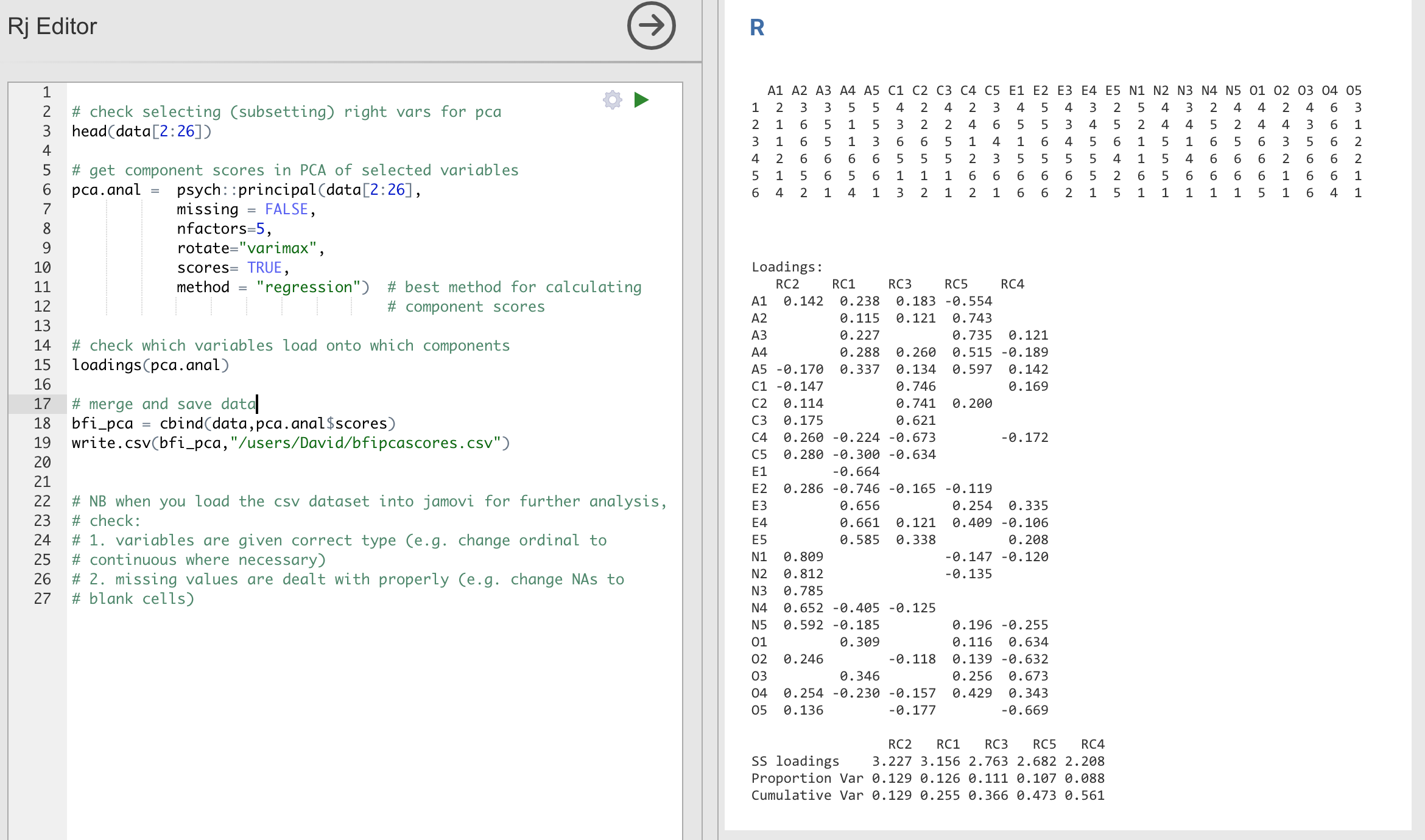
Abb. 190 Rj-Editor-Befehle für das Berechnen von optimal gewichteten Komponenten-Scores für die Fünf-Komponenten-Lösung beim Durchführen einer PCA mit den Persönlichkeitsdaten in jamovi