Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Erstellen von Häufigkeitstabellen und Kreuztabellen aus Ihren Daten
Eine sehr häufige Aufgabe bei der Analyse von Daten ist die Erstellung von Häufigkeitstabellen einer Variablen oder von Kreuztabellen einer Variablen mit einer anderen. Diese Aufgaben können in jamovi einfach erledigt werden. In diesem Abschnitt, zeige ich Ihnen, wie Sie das machen können.
Häufigkeitstabellen für einzelne Variablen erstellen
Lassen Sie uns mit einem einfachen Beispiel beginnen. Als Elternteil eines kleinen Kindes verbringe ich viel Zeit damit, Fernsehsendungen wie In the Night Garden zu sehen. In dem Datensatz nightgarden habe ich einen kurzen Abschnitt des Dialogs transkribiert. Die Datei enthält zwei Variablen, die von Interesse sind: speaker und utterance. Öffnen Sie diesen Datensatz in jamovi und werfen Sie einen Blick auf die Daten (drücken Sie auf den Tab Data). Sie werden sehen, dass die Daten etwa so aussehen:
Variable speaker
upsy-daisy upsy-daisy upsy-daisy upsy-daisy tombliboo tombliboo makka-pakka makka-pakka makka-pakka makka-pakka
Variable utterance
pip pip onk onk ee oo pip pip onk onk
Wenn ich mir das ansehe, wird mir klar, was mit meinem Verstand passiert ist! Eine Aufgabe, die ich mit diesen Daten zu erledigen habe, könnte zum Beispiel sein, eine Liste mit der Anzahl der Wörter, die jeder Charakter während der Serie spricht, zu erstellen. Das jamovi-Eingabefeld Descriptives hat eine Checkbox namens Frequency tables, welche die folgende Ausgabe erstellt, wenn man sie aktiviert (siehe Abb. 32):

Abb. 32 Häufigkeitstabelle für die Variable speaker
Die Ausgabe, die wir erhalten, sagt uns in der ersten Zeile, dass es sich um eine Tabelle für die Variable speaker handelt. In der Spalte Levels werden alle Sprecher aufgelistet, die es in diesem Datensatz gibt und in der Spalte Counts wird angegeben, wie häufig dieser Sprecher im Datensatz vorkommt. Mit anderen Worten, es ist eine Häufigkeitstabelle.
Wird die Checkbox Frequency tables in jamovi aktiviert, wird jeweils eine Tabelle für jede einzelne Variablen erstellt. Für eine Tabelle, welche die Kombination zweier Variablen darstellt, zum Beispiel die Kombination von speaker und utterance, brauchen wir eine Kreuztabelle. In dieser Kreuztabelle ist zu sehen, wie oft jeder Sprecher eine bestimmte Äußerung gemacht hat. In jamovi können Sie dies tun, indem Sie die Analyse Frequencies → Contingency Tables → Independent Samples auswählen und die Variable speaker in das Feld Rows und die Variable utterance in das Feld Columns verschieben. Sie sollten dann eine Kreuztabelle wie die in Abb. 33 gezeigte erhalten.
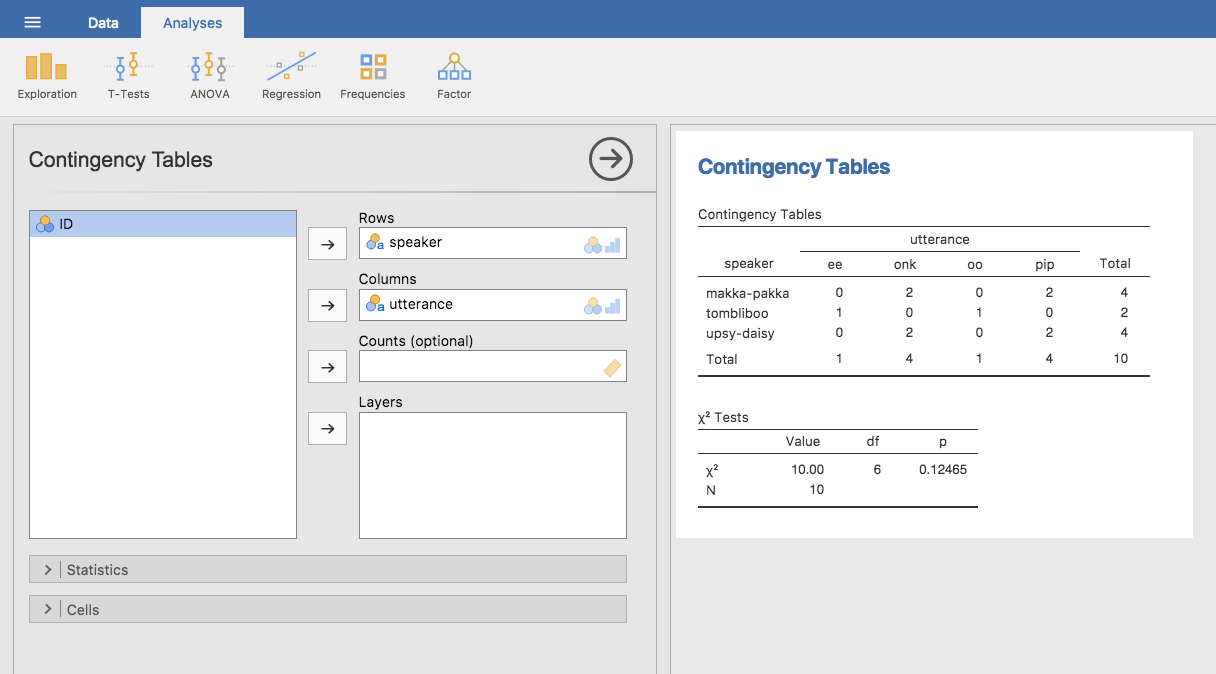
Abb. 33 Kreuztabelle für die Variablen speaker und utterance
Kümmern Sie sich nicht um die Tabelle „χ² Tests“, die automatisch mit erzeugt wird. Wir werden später in Kapitel Analyse kategorialer Daten darauf zurückkommen. Wenn Sie die Kreuztabelle interpretieren, denken Sie daran, dass es sich hier um Häufigkeiten handelt. Die Tatsache, dass in der ersten Zeile und in der zweiten Spalte, die Zahlen enthält, einen Wert von 2 steht, bedeutet, dass makka-pakka (Zeile 1) in diesem Datensatz zweimal onk (Spalte 2) sagt.
Prozentanteile zu einer Kreuztabelle hinzufügen
Die Kreuztabelle in Abb. 33 zeigt eine Tabelle der absoluten Häufigkeiten in den Rohdaten. Das heißt also die Gesamtzahl der Fälle für die jeweiligen Kombinationen der verschiedenen Ausprägungen (Level) der angegebenen Variablen. Häufig möchten Sie Ihre Daten jedoch nicht nur in Form von Häufigkeiten, sondern auch in Form von Prozentanteilen (relative Häufigkeiten) aufbereiten. Sie finden die Checkboxen für die verschiedenen Prozentangaben unter der Option Cells im Fenster Contingency Tables. Klicken Sie zunächst auf die Checkbox Rows und die Kreuztabelle im Ausgabefenster wird so verändert, so dass sie der Tabelle in der Abbildung Abb. 34 ähnelt.
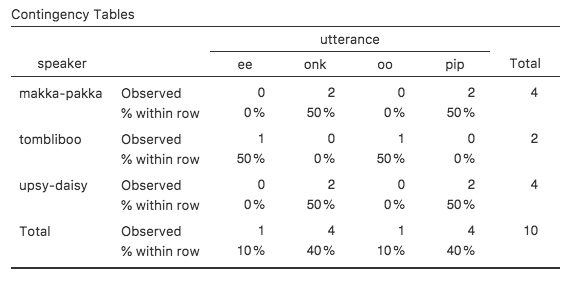
Abb. 34 Kreuztabelle für die Variablen speaker und utterances mit Prozentanteilen für jede Zeile
Was wir hier sehen können, ist der prozentuale Anteil der Äußerungen von jedem der Charaktere. Mit anderen Worten: 50 % der Äußerungen von makka-pakka sind pip, und die anderen 50 % sind onk. Vergleichen wir dies mit der Tabelle, die wir erhalten, wenn wir die prozentualen Anteile der Spalten berechnen (deaktivieren Sie das Kontrollhäkchen in Row und aktivieren Sie Column im Optionsfenster Cells), siehe Abb. 35. In dieser Version sehen wir den prozentualen Anteil der Charaktere, die zu jeder Äußerung gehören. Wenn in diesem Datensatz zum Beispiel ee gesagt wird, dann ist es in 100 % der Fälle ein Tombliboo, der das sagt.
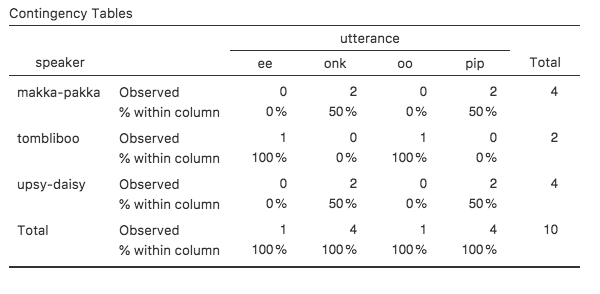
Abb. 35 Kreuztabelle für die Variablen speaker und utterance, mit Spaltenprozentsätzen