Section author: Danielle J. Navarro and David R. Foxcroft
The independent samples t-test (Student test)¶
Although the one sample t-test has its uses, it’s not the most typical example of a t-test.[1] A much more common situation arises when you’ve got two different groups of observations. In psychology, this tends to correspond to two different groups of participants, where each group corresponds to a different condition in your study. For each person in the study you measure some outcome variable of interest, and the research question that you’re asking is whether or not the two groups have the same population mean. This is the situation that the independent samples t-test is designed for.
The data¶
Suppose we have 33 students taking Dr Harpo’s statistics lectures, and Dr Harpo
doesn’t grade to a curve. Actually, Dr Harpo’s grading is a bit of a mystery,
so we don’t really know anything about what the average grade is for the class
as a whole. There are two tutors for the class, Anastasia and Bernadette. There
are N1 = 15 students in Anastasia’s tutorials, and N2 =
18 in Bernadette’s tutorials. The research question I’m interested in is
whether Anastasia or Bernadette is a better tutor, or if it doesn’t make much
of a difference. Dr Harpo sends me the harpo data set with the course
grades. file. As usual, I’ll load the file into jamovi and have a look at what
variables it contains - there are three variables, ID, grade and
tutor. The grade variable contains each student’s grade, but it is not
imported into jamovi with the correct measurement level attribute, so I need
to change this so it is regarded as a continuous variable  (see
Changing measurement levels). The
(see
Changing measurement levels). The tutor variable
is a factor  that indicates who each student’s tutor was - either
Anastasia or Bernadette.
that indicates who each student’s tutor was - either
Anastasia or Bernadette.
We can calculate means and standard deviations, using the Exploration →
Descriptives analysis, and here’s a nice little summary table:
| mean | std. dev. | N | |
|---|---|---|---|
| Anastasia’s students | 74.53 | 9.00 | 15 |
| Bernadette’s students | 69.06 | 5.77 | 18 |
To give you a more detailed sense of what’s going on here, I’ve plotted histograms (not in jamovi, but using R) showing the distribution of grades for both tutors (Fig. 88), as well as a simpler plot showing the means and corresponding confidence intervals for both groups of students (Fig. 89).

Fig. 88 Histograms showing the distribution of grades for students in Anastasia’s (left panel) and in Bernadette’s (right panel) classes. Visually, these suggest that students in Anastasia’s class may be getting slightly better grades on average, though they also seem a bit more variable.

Fig. 89 The plots show the mean grade for students in Anastasia’s and Bernadette’s tutorials. Error bars depict 95% confidence intervals around the mean. Visually, it does look like there’s a real difference between the groups, though it’s hard to say for sure.
Introducing the test¶
The independent samples t-test comes in two different forms, Student’s and Welch’s. The original Student t-test, which is the one I’ll describe in this section, is the simpler of the two but relies on much more restrictive assumptions than the Welch t-test. Assuming for the moment that you want to run a two-sided test, the goal is to determine whether two “independent samples” of data are drawn from populations with the same mean (the null hypothesis) or different means (the alternative hypothesis). When we say “independent” samples, what we really mean here is that there’s no special relationship between observations in the two samples. This probably doesn’t make a lot of sense right now, but it will be clearer when we come to talk about the paired samples t-test later on. For now, let’s just point out that if we have an experimental design where participants are randomly allocated to one of two groups, and we want to compare the two groups’ mean performance on some outcome measure, then an independent samples t-test (rather than a paired samples t-test) is what we’re after.
Okay, so let’s let µ1 denote the true population mean for group 1 (e.g., Anastasia’s students), and µ2 will be the true population mean for group 2 (e.g., Bernadette’s students),[2] and as usual we’ll let X̄1`and *X̄*:sub:`2 denote the observed sample means for both of these groups. Our null hypothesis states that the two population means are identical (µ1 = µ1) and the alternative to this is that they are not (µ1 ≠ µ1). Written in mathematical-ese, this is:

Fig. 90 Graphical illustration of the null and alternative hypotheses assumed by the Student t-test for Independent Samples. The null hypothesis assumes that both groups have the same mean µ, whereas the alternative assumes that they have different means µ1 and µ2. Notice that it is assumed that the population distributions are normal, and that, although the alternative hypothesis allows the group to have different means, it assumes they have the same standard deviation.
To construct a hypothesis test that handles this scenario we start by noting that if the null hypothesis is true, then the difference between the population means is exactly zero, µ1 - µ1 = 0. As a consequence, a diagnostic test statistic will be based on the difference between the two sample means. Because if the null hypothesis is true, then we’d expect X̄1 – X̄2 to be pretty close to zero. However, just like we saw with our one-sample tests (i.e., the one-sample z-test and the one-sample t-test) we have to be precise about exactly how close to zero this difference should be. And the solution to the problem is more or less the same one. We calculate a standard error estimate (SE), just like last time, and then divide the difference between means by this estimate. So our t-statistic will be of the form:
We just need to figure out what this standard error estimate actually is. This is a bit trickier than was the case for either of the two tests we’ve looked at so far, so we need to go through it a lot more carefully to understand how it works.
A “pooled estimate” of the standard deviation¶
In the original “Student t-test”, we make the assumption that the two groups have the same population standard deviation. That is, regardless of whether the population means are the same, we assume that the population standard deviations are identical, σ1 = σ2. Since we’re assuming that the two standard deviations are the same, we drop the subscripts and refer to both of them as σ. How should we estimate this? How should we construct a single estimate of a standard deviation when we have two samples? The answer is, basically, we average them. Well, sort of. Actually, what we do is take a weighed average of the variance estimates, which we use as our pooled estimate of the variance. The weight assigned to each sample is equal to the number of observations in that sample, minus 1.
Mathematically, we can write this as
Now that we’ve assigned weights to each sample we calculate the pooled estimate of the variance by taking the weighted average of the two variance estimates, \({\hat\sigma_1}^2\) and \({\hat\sigma_2}^2\)
Finally, we convert the pooled variance estimate to a pooled standard deviation estimate, by taking the square root.
And if you mentally substitute w1 = N1 - 1 and w2 = N2 - 1 into this equation you get a very ugly looking formula. A very ugly formula that actually seems to be the “standard” way of describing the pooled standard deviation estimate. It’s not my favourite way of thinking about pooled standard deviations, however. I prefer to think about it like this. Our data set actually corresponds to a set of N observations which are sorted into two groups. So let’s use the notation Xik to refer to the grade received by the i-th student in the k-th tutorial group. That is, X11 is the grade received by the first student in Anastasia’s class, X21 is her second student, and so on. And we have two separate group means X̄1 and X̄2, which we could “generically” refer to using the notation X̄k, i.e., the mean grade for the k-th tutorial group. So far, so good. Now, since every single student falls into one of the two tutorials, we can describe their deviation from the group mean as the difference
So why not just use these deviations (i.e., the extent to which each student’s grade differs from the mean grade in their tutorial)? Remember, a variance is just the average of a bunch of squared deviations, so let’s do that. Mathematically, we could write it like this
where the notation “Σik” is a lazy way of saying “calculate a sum by looking at all students in all tutorials”, since each “ik” corresponds to one student.[3] But, as we saw in chapter Estimating unknown quantities from a sample, calculating the variance by dividing by N produces a biased estimate of the population variance. And previously we needed to divide by N - 1 to fix this. However, as I mentioned at the time, the reason why this bias exists is because the variance estimate relies on the sample mean, and to the extent that the sample mean isn’t equal to the population mean it can systematically bias our estimate of the variance. But this time we’re relying on two sample means! Does this mean that we’ve got more bias? Yes, yes it does. And does this mean we now need to divide by N - 2 instead of N - 1, in order to calculate our pooled variance estimate? Why, yes
Oh, and if you take the square root of this then you get \(\hat{\sigma}_p\), the pooled standard deviation estimate. In other words, the pooled standard deviation calculation is nothing special. It’s not terribly different to the regular standard deviation calculation.
Completing the test¶
Regardless of which way you want to think about it, we now have our pooled estimate of the standard deviation. From now on, I’ll drop the silly p subscript, and just refer to this estimate as \(\hat\sigma\). Great. Let’s now go back to thinking about the bloody hypothesis test, shall we? Our whole reason for calculating this pooled estimate was that we knew it would be helpful when calculating our standard error estimate. But standard error of what? In the one-sample t-test it was the standard error of the sample mean, SE(X̄), and since \(SE(X̄) = \sigma / \sqrt{N}\) that’s what the denominator of our t-statistic looked like. This time around, however, we have two sample means. And what we’re interested in, specifically, is the difference between the two X̄1 – X̄2. As a consequence, the standard error that we need to divide by is in fact the standard error of the difference between means.
As long as the two variables really do have the same standard deviation, then our estimate for the standard error is
and our t-statistic is therefore
Just as we saw with our one-sample test, the sampling distribution of this t-statistic is a t-distribution (shocking, isn’t it?) as long as the null hypothesis is true and all of the assumptions of the test are met. The degrees of freedom, however, is slightly different. As usual, we can think of the degrees of freedom to be equal to the number of data points minus the number of constraints. In this case, we have N observations (N1 in sample 1, and N2 in sample 2), and 2 constraints (the sample means). So the total degrees of freedom for this test are N - 2.
Doing the test in jamovi¶
Not surprisingly, you can run an independent samples t-test
easily in jamovi. The outcome variable for our test is the student
grade, and the groups are defined in terms of the tutor for each
class. So you probably won’t be too surprised that all you have to do in
jamovi is go to the relevant analysis (Analyses → T-Tests →
Independent Samples T-Test) and move the grade variable across to
the Dependent Variables box, and the tutor variable across into
the Grouping Variable box, as shown in Fig. 91.
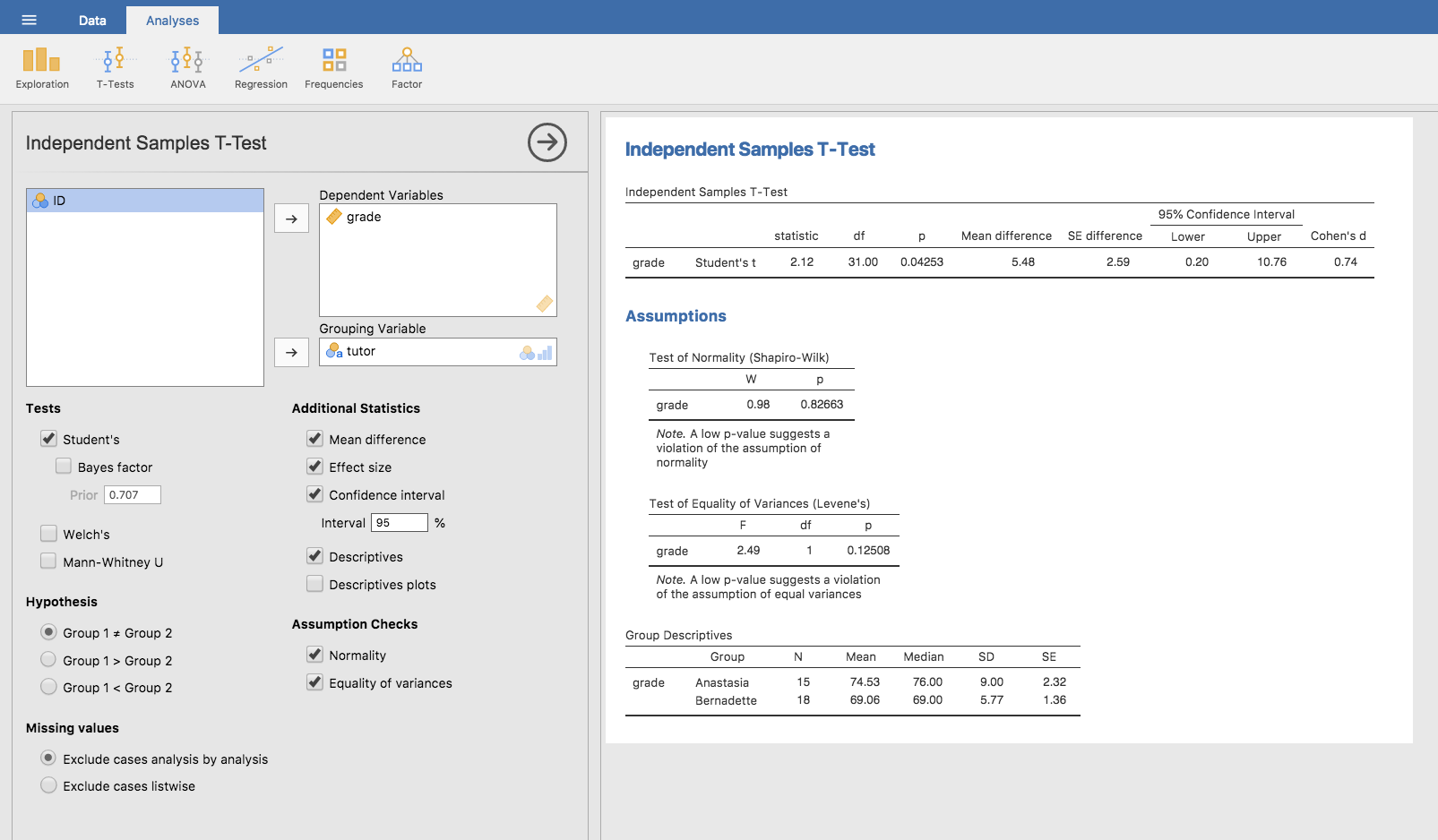
Fig. 91 Conducting an Independent Samples t-test in jamovi, with options for recommended outputs checked.
The output has a very familiar form. First, it tells you what test was run, and it tells you the name of the dependent variable that you used. It then reports the test results. Just like last time the test results consist of a t-statistic, the degrees of freedom, and the p-value. The final section reports two things: it gives you a confidence interval and an effect size. I’ll talk about effect sizes later. The confidence interval, however, I should talk about now.
It’s pretty important to be clear on what this confidence interval actually refers to. It is a confidence interval for the difference between the group means. In our example, Anastasia’s students had an average grade of 74.53, and Bernadette’s students had an average grade of 69.06, so the difference between the two sample means is 5.48. But of course the difference between population means might be bigger or smaller than this. The confidence interval reported in Fig. 91 tells you that there’s a if we replicated this study again and again, then 95% of the time the true difference in means would lie between 0.20 and 10.76. Look back at Estimating a confidence interval for a reminder about what confidence intervals mean.
In any case, the difference between the two groups is significant (just barely), so we might write up the result using text like this:
The mean grade in Anastasia’s class was 74.5% (std dev = 9.0), whereas the mean in Bernadette’s class was 69.1% (std dev = 5.8). A Student’s independent samples t-test showed that this 5.4% difference was significant (t(31) = 2.1, p < 0.05, CI95 = [0.2, 10.8]`, d = 0.74), suggesting that a genuine difference in learning outcomes has occurred.
Notice that I’ve included the confidence interval and the effect size in the stat block. People don’t always do this. At a bare minimum, you’d expect to see the t-statistic, the degrees of freedom and the p-value. So you should include something like this at a minimum: t(31) = 2.1, p < 0.05. If statisticians had their way, everyone would also report the confidence interval and probably the effect size measure too, because they are useful things to know. But real life doesn’t always work the way statisticians want it to so you should make a judgment based on whether you think it will help your readers and, if you’re writing a scientific paper, the editorial standard for the journal in question. Some journals expect you to report effect sizes, others don’t. Within some scientific communities it is standard practice to report confidence intervals, in others it is not. You’ll need to figure out what your audience expects. But, just for the sake of clarity, if you’re taking my class, my default position is that it’s usually worth including both the effect size and the confidence interval.
Positive and negative t-values¶
Before moving on to talk about the assumptions of the t-test, there’s one additional point I want to make about the use of t-tests in practice. The first one relates to the sign of the t-statistic (that is, whether it is a positive number or a negative one). One very common worry that students have when they start running their first t-test is that they often end up with negative values for the t-statistic and don’t know how to interpret it. In fact, it’s not at all uncommon for two people working independently to end up with results that are almost identical, except that one person has a negative t-values and the other one has a positive t-value. Assuming that you’re running a two-sided test then the p-values will be identical. On closer inspection, the students will notice that the confidence intervals also have the opposite signs. This is perfectly okay. Whenever this happens, what you’ll find is that the two versions of the results arise from slightly different ways of running the t-test. What’s happening here is very simple. The t-statistic that we calculate here is always of the form
If “mean 1” is larger than “mean 2” the t-statistic will be positive, whereas if “mean 2” is larger then the t-statistic will be negative. Similarly, the confidence interval that jamovi reports is the confidence interval for the difference “(mean 1) minus (mean 2)”, which will be the reverse of what you’d get if you were calculating the confidence interval for the difference “(mean 2) minus (mean 1)”.
Okay, that’s pretty straightforward when you think about it, but now consider our t-test comparing Anastasia’s class to Bernadette’s class. Which one should we call “mean 1” and which one should we call “mean 2”. It’s arbitrary. However, you really do need to designate one of them as “mean 1” and the other one as “mean 2”. Not surprisingly, the way that jamovi handles this is also pretty arbitrary. In earlier versions of the book I used to try to explain it, but after a while I gave up, because it’s not really all that important and to be honest I can never remember myself. Whenever I get a significant t-test result, and I want to figure out which mean is the larger one, I don’t try to figure it out by looking at the t-statistic. Why would I bother doing that? It’s foolish. It’s easier just to look at the actual group means since the jamovi output actually shows them!
Here’s the important thing. Because it really doesn’t matter what jamovi shows you, I usually try to report the t-statistic in such a way that the numbers match up with the text. Suppose that what I want to write in my report is “Anastasia’s class had higher grades than Bernadette’s class”. The phrasing here implies that Anastasia’s group comes first, so it makes sense to report the t-statistic as if Anastasia’s class corresponded to group 1. If so, I would write
Anastasia’s class had higher grades than Bernadette’s class: t(31) = 2.1, p = 0.04.
(I wouldn’t actually underline the word “higher” in real life, I’m just doing it to emphasise the point that “higher” corresponds to positive t-values). On the other hand, suppose the phrasing I wanted to use has Bernadette’s class listed first. If so, it makes more sense to treat her class as group 1, and if so, the write up looks like this
Bernadette’s class had lower grades than Anastasia’s class: t(31) = -2.1, p = 0.04.
Because I’m talking about one group having “lower” scores this time around, it is more sensible to use the negative form of the t-statistic. It just makes it read more cleanly.
One last thing: please note that you can’t do this for other types of test statistics. It works for t-tests, but it wouldn’t be meaningful for χ²-tests, F-tests or indeed for most of the tests I talk about in this book. So don’t over-generalise this advice! I’m really just talking about t-tests here and nothing else!
Assumptions of the Student t-test¶
As always, our hypothesis test relies on some assumptions. So what are they? For the Student t-test there are three assumptions, some of which we saw previously in the context of the one sample t-test (see section Assumptions of the one sample *t*-test):
- Normality. Like the one-sample t-test, it is assumed that the data are normally distributed. Specifically, we assume that both groups are normally distributed. In section Checking the normality of a sample, we’ll discuss how to test for normality, and in section Testing non-normal data with Wilcoxon tests we’ll discuss possible solutions.
- Independence. Once again, it is assumed that the observations are independently sampled. In the context of the Student test this has two aspects to it. Firstly, we assume that the observations within each sample are independent of one another (exactly the same as for the one-sample test). However, we also assume that there are no cross-sample dependencies. If, for instance, it turns out that you included some participants in both experimental conditions of your study (e.g., by accidentally allowing the same person to sign up to different conditions), then there are some cross sample dependencies that you’d need to take into account.
- Homogeneity of variance (also called “homoscedasticity”). The third assumption is that the population standard deviation is the same in both groups. You can test this assumption using the Levene test, which I’ll talk about later on in the book (section Checking the homogeneity of variance assumption). However, there’s a very simple remedy for this assumption if you are worried, which I’ll talk about in the next section.
| [1] | Although it is the simplest, which is why I started with it. |
| [2] | A funny question almost always pops up at this point: what the heck is the population being referred to in this case? Is it the set of students actually taking Dr Harpo’s class (all 33 of them)? The set of people who might take the class (an unknown number of them)? Or something else? Does it matter which of these we pick? It’s traditional in an introductory behavioural stats class to mumble a lot at this point, but since I get asked this question every year by my students, I’ll give a brief answer. Technically yes, it does matter. If you change your definition of what the “real world” population actually is, then the sampling distribution of your observed mean X̄ changes too. The t-test relies on an assumption that the observations are sampled at random from an infinitely large population and, to the extent that real life isn’t like that, then the t-test can be wrong. In practice, however, this isn’t usually a big deal. Even though the assumption is almost always wrong, it doesn’t lead to a lot of pathological behaviour from the test, so we tend to just ignore it. |
| [3] | A more correct notation will be introduced in chapter Comparing several means (one-way ANOVA). |