Section author: Danielle J. Navarro and David R. Foxcroft
The paired-samples t-test¶
Regardless of whether we’re talking about the Student test or the Welch test, an independent samples t-test is intended to be used in a situation where you have two samples that are, well, independent of one another. This situation arises naturally when participants are assigned randomly to one of two experimental conditions, but it provides a very poor approximation to other sorts of research designs. In particular, a repeated measures design, in which each participant is measured (with respect to the same outcome variable) in both experimental conditions, is not suited for analysis using independent samples t-tests. For example, we might be interested in whether listening to music reduces people’s working memory capacity. To that end, we could measure each person’s working memory capacity in two conditions: with music, and without music. In an experimental design such as this one,[1] each participant appears in both groups. This requires us to approach the problem in a different way, by using the paired samples t-test.
The data¶
The data set that we’ll use this time comes from Dr Chico’s class.[2]
In her class students take two major tests, one early in the semester
and one later in the semester. To hear her tell it, she runs a very hard
class, one that most students find very challenging. But she argues that
by setting hard assessments students are encouraged to work harder. Her
theory is that the first test is a bit of a “wake up call” for students.
When they realise how hard her class really is, they’ll work harder for
the second test and get a better mark. Is she right? To test this, let’s
import the chico data set into jamovi. This time jamovi does a good
job during the import of attributing measurement levels correctly. The
chico data set contains three variables: an id variable that
identifies each student in the class, the grade_test1 variable that
records the student grade for the first test, and the grade_test2
variable that has the grades for the second test.
If we look at the jamovi spreadsheet it does seem like the class is a hard one (most grades are between 50% and 60%), but it does look like there’s an improvement from the first test to the second one.
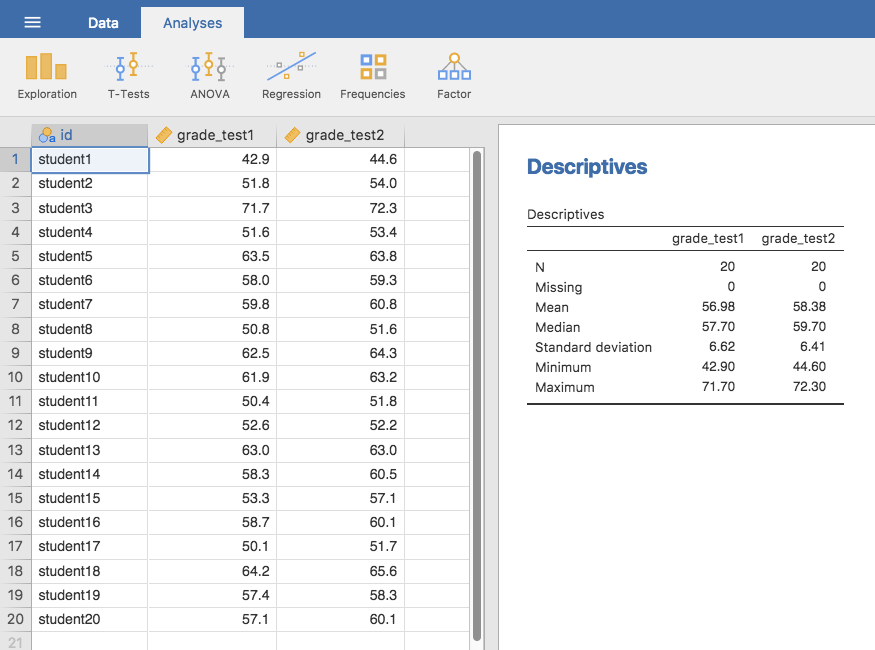
Fig. 94 Descriptives for the two grade test variables in the chico data set
If we take a quick look at the descriptive statistics, in Fig. 94, we see that this impression seems to be supported. Across all 20 students the mean grade for the first test is 57%, but this rises to 58% for the second test. Although, given that the standard deviations are 6.6% and 6.4% respectively, it’s starting to feel like maybe the improvement is just illusory; maybe just random variation. This impression is reinforced when you see the means and confidence intervals plotted in Fig. 95 (left panel). If we were to rely on this plot alone, looking at how wide those confidence intervals are, we’d be tempted to think that the apparent improvement in student performance is pure chance.

Fig. 95 Mean grade for test 1 and test 2, with associated 95% confidence intervals (left panel). Scatterplot showing the individual grades for test 1 and test 2 (middle panel). Histogram showing the improvement made by each student in Dr Chico’s class (right panel). In the right panel, notice that almost the entire distribution is above zero: the vast majority of students did improve their performance from the first test to the second one.
Nevertheless, this impression is wrong. To see why, take a look at the
scatterplot of the grades for test 1 against the grades for test 2,
shown in Fig. 95 (middle panel). In this plot each
dot corresponds to the two grades for a given student. If their grade
for test 1 (x co-ordinate) equals their grade for test 2
(y co-ordinate), then the dot falls on the line. Points falling
above the line are the students that performed better on the second
test. Critically, almost all of the data points fall above the diagonal
line: almost all of the students do seem to have improved their grade,
if only by a small amount. This suggests that we should be looking at
the improvement made by each student from one test to the next and
treating that as our raw data. To do this, we’ll need to create a new
variable for the improvement that each student makes, and add it to
the chico data set. The easiest way to do this is to compute a new
variable, with the expression grade_test2 - grade_test1.
Once we have computed this new improvement variable we can draw a
histogram showing the distribution of these improvement scores, shown in
Fig. 95 (right panel). When we look at the
histogram, it’s very clear that there is a real improvement here. The
vast majority of the students scored higher on test 2 than on test 1,
reflected in the fact that almost the entire histogram is above zero.
What is the paired samples t-test?¶
In light of the previous exploration, let’s think about how to construct
an appropriate t-test. One possibility would be to try to run an
independent samples t-test using grade_test1 and
grade_test2 as the variables of interest. However, this is clearly
the wrong thing to do as the independent samples t-test assumes
that there is no particular relationship between the two samples. Yet
clearly that’s not true in this case because of the repeated measures
structure in the data. To use the language that I introduced in the last
section, if we were to try to do an independent samples t-test,
we would be conflating the within subject differences (which is what
we’re interested in testing) with the between subject variability
(which we are not).
The solution to the problem is obvious, I hope, since we already did all
the hard work in the previous section. Instead of running an independent
samples t-test on grade_test1 and grade_test2, we run a
one-sample t-test on the within-subject difference variable,
improvement. To formalise this slightly, if Xi1 is the
score that the i-th participant obtained on the first variable,
and Xi2 is the score that the same person obtained on the
second one, then the difference score is:
Notice that the difference scores is variable 1 minus variable 2 and not the other way around, so if we want improvement to correspond to a positive valued difference, we actually want “test 2” to be our “variable 1”. Equally, we would say that µD = µ1 - µ2 is the population mean for this difference variable. So, to convert this to a hypothesis test, our null hypothesis is that this mean difference is zero and the alternative hypothesis is that it is not
This is assuming we’re talking about a two-sided test here. This is more or less identical to the way we described the hypotheses for the one-sample t-test. The only difference is that the specific value that the null hypothesis predicts is 0. And so our t-statistic is defined in more or less the same way too. If we let D̄ denote the mean of the difference scores, then
which is
where \(\hat\sigma_D\) is the standard deviation of the difference scores. Since this is just an ordinary, one-sample t-test, with nothing special about it, the degrees of freedom are still N - 1. And that’s it. The paired samples t-test really isn’t a new test at all. It’s a one-sample t-test, but applied to the difference between two variables. It’s actually very simple. The only reason it merits a discussion as long as the one we’ve just gone through is that you need to be able to recognise when a paired samples test is appropriate, and to understand why it’s better than an independent samples t-test.
Doing the test in jamovi¶
How do you do a paired samples t-test in jamovi? One possibility is to follow
the process I outlined above. That is, create a difference variable and
then run a one sample t-test on that. Since we’ve already created a variable
called improvement, let’s do that and see what we get
(see Fig. 96).

Fig. 96 Results showing a one sample t-test on paired difference scores
The output shown in Fig. 96 is (obviously) formatted
exactly the same was as it was the last time we used the One Sample T-Test
analysis (section The one-sample t-test), and it confirms our intuition.
There’s an average improvement of 1.4% from test 1 to test 2, and this is
significantly different from 0 (t(19) = 6.48, p < 0.001).
However, suppose you’re lazy and you don’t want to go to all the effort
of creating a new variable. Or perhaps you just want to keep the
difference between one-sample and paired-samples tests clear in your
head. If so, you can use the jamovi Paired Samples T-Test analysis,
getting the results shown in Fig. 97.

Fig. 97 Results showing a paired sample t-test. Compare it with Fig. 96.
The numbers are identical to those that come from the one sample test, which of course they have to be given that the paired samples t-test is just a one sample test under the hood.
| [1] | This design is very similar to the one in section
The McNemar test that motivated the McNemar test. This should
be no surprise. Both are standard repeated measures designs involving two
measurements. The only difference is that this time our outcome variable is
interval scale (working memory capacity,  ) rather than a binary
scale variable (a yes-or-no question, ) rather than a binary
scale variable (a yes-or-no question,  ). ). |
| [2] | At this point we have Drs Harpo, Chico and Zeppo. No prizes for guessing who Dr Groucho is. |