Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Einfaktorielle ANOVA mit Messwiederholung
Der einfaktorielle ANOVA mit Messwiederholung ist eine statistische Analyse zum Testen auf signifikante Unterschiede zwischen drei oder mehr Gruppen, bei der die gleichen Teilnehmer in jeder Gruppe verwendet werden (oder jeder Teilnehmer eng mit einem Teilnehmer in einer anderen experimentellen Gruppen übereinstimmt). Aus diesem Grund sollte es in jeder Versuchsgruppe immer gleich viele Punkte (Datenpunkte) geben. Diese Art von Design und Analyse wird auch als „abhängige ANOVA“ - related ANOVA - oder Innersubjekt-ANOVA - within-subjects ANOVA - bezeichnet.
The logic behind a repeated measures ANOVA is very similar to that of an independent ANOVA (sometimes called a “between-subjects” ANOVA). You will remember that earlier we showed that in a between-subjects ANOVA total variability is partitioned into between-groups variability (SSb) and within-groups variability (SSw), then divided by their respective degrees of freedom to give MSb and MSw (see Tab. 16), whereupon the F-ratio is calculated as:
In a repeated measures ANOVA, the F-ratio is calculated in a similar way, but whereas in an independent ANOVA the within-group variability (SSw) is used as the basis for the MSw denominator, in a repeated measures ANOVA the SSw is partioned into two parts. As we are using the same subjects in each group, we can remove the variability due to the individual differences between subjects (referred to as SSsubjects) from the within-groups variability. We will not go into too much technical detail about how this is done, but essentially each subject becomes a level of a factor called subjects. The variability in this within-subjects factor is then calculated in the same way as any between-subjects factor. And then we can subtract SSsubjects from SSw to provide a smaller SSerror term:
This change in SSerror term often leads to a more powerful statistical test, but this does depend on whether the reduction in the SSerror more than compensates for the reduction in degrees of freedom for the error term: the degrees of freedom go from (n - k)[1] to (n - 1)(k - 1) remembering that there are more subjects in the independent ANOVA design.
Durchführen einer ANOVA mit Messwiederholung in jamovi
Zuerst brauchen wir einige Daten: Geschwind (1972) hat vorgeschlagen, dass die Art von Sprachdefiziten bei Schlaganfall-Patienten davon abhängt, welche spezifische Region des Gehirns geschädigt wurde (umgekehrt kann die Art von Defiziten verwendet werden kann, um zu diagnostizieren, welche Hirnregion von einer Läsion betroffen ist). Ein Forscher beschäftigt sich mit dem Identifizieren von spezifischen Kommunikationsschwierigkeiten von sechs Patienten, die an Broca-Aphasie leiden (ein Sprachdefizit, das häufig nach einem Schlaganfall auftritt).
Teilnehmer |
Sprachproduktion |
Semantik |
Syntax |
|---|---|---|---|
1 |
8 |
7 |
6 |
2 |
7 |
8 |
6 |
3 |
9 |
5 |
3 |
4 |
5 |
4 |
5 |
5 |
6 |
6 |
2 |
6 |
8 |
7 |
4 |
Die Patienten hatten drei Aufgaben. Im ersten Aufgabenbereich (Sprachproduktion) mussten die Patienten einzelne Wörter wiederholen, die vom Forscher laut vorgelesen wurden. Im zweiten Aufgabenbereich (Semantik), wurde das Wortverständnis getestet, und die Patienten mussten eine Reihe von Bildern der korrekten Bezeichnung zuordnen. Der dritte Aufgabenbereich (Syntax) sollte das Wissen über die korrekte Wortstellung testen, und die Patienten wurden gebeten, syntaktisch inkorrekte Sätze neu zu ordnen. Jeder Patient erhielt jeweils 10 Teilaufgaben aus allen drei Aufgabenbereichen. In welcher Reihenfolge die Patienten die Aufgaben aus den verschiedenen Bereichen durchführten, wurde zwischen den Teilnehmern balanciert. Die Anzahl der von jedem Patienten erfolgreich abgeschlossenen Teilaufgaben wird in Tab. 17 angezeigt. Geben Sie diese Daten entweder manuell in jamovi ein (oder nehmen Sie eine Abkürzung und laden Sie den Datensatz broca).
To perform a one-way related ANOVA in jamovi, open the one-way repeated
measures ANOVA dialogue box, as in Abb. 160, via ANOVA → Repeated
Measures ANOVA. Then:
Geben Sie einen Namen für den Messwiederholungsfaktor unter
Repeated Measures Factors``ein (d.h., ersetzen Sie das ursprüngliche ``RM Factor …mit diesem Namen). Dies sollte ein Name sein, der alle Bedingungen beschreibt, die von den Teilnehmern wiederholt wurden. Um beispielsweise die von allen Teilnehmern erledigten Sprachproduktions-, Semantik- und Syntaxaufgaben zu beschreiben, wäre eine geeignete Bezeichnung „Aufgabe“ oder „Aufgabenbereich“ (Task). Dieser neue Faktor-Name stellt die unabhängige Variable in der Analyse dar.Fügen Sie im Variablenfeld
Repeated Measures Factorseine dritte Ebene hinzu, da es drei Ebenen für die verschiedenen Aufgaben gibt und ändern Sie die Bezeichnungen der Ebenen entsprechend: Sprachproduktion (Speech), Semantik (Conceptual) und Syntax (Syntax).Verschieben Sie dann jede Variable in die ihr zugeordnete Ebene innnerhalb des Textfelds
Repeated Measures Cells.Aktivieren Sie schließlich unter den
Assumption Checks-Optionen dieSphericity checks-Checkbox.
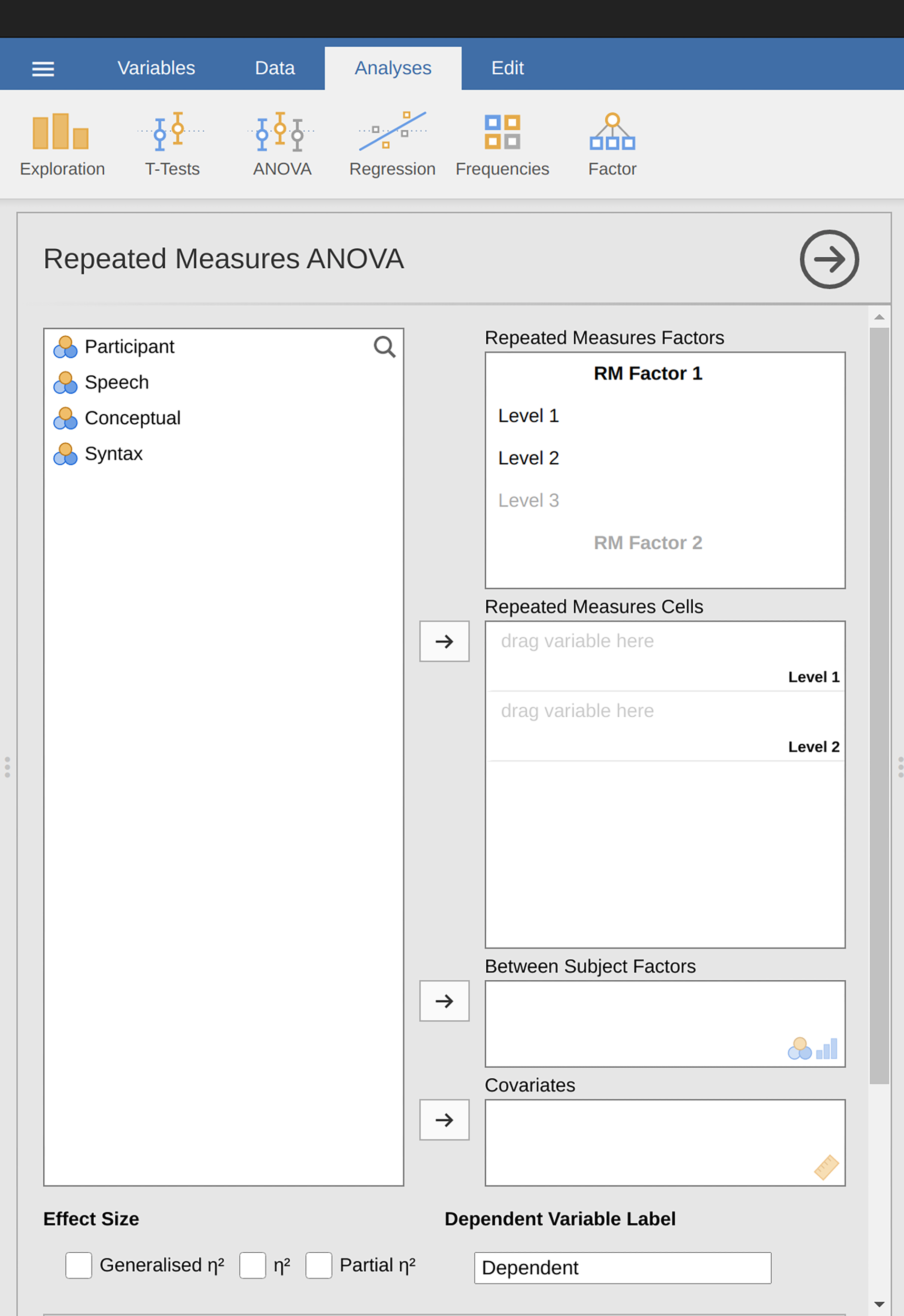
Abb. 160 Options-Dialogfeld für die ANOVA mit Messwiederholung in jamovi
jamovi output for a one-way Repeated Measures ANOVA is produced as shown
in the Abb. 161 to Abb. 164. The first output we should
look at is Mauchly’s Test of Sphericity, which tests the hypothesis that
the variances of the differences between the conditions are equal (meaning that
the spread of difference scores between the study conditions is approximately
the same). In Abb. 161, Mauchly’s test significance level is p =
0.720. If Mauchly’s test is non-significant (i.e., p > 0.05, as is the case
in this analysis) then it is reasonable to conclude that the variances of the
differences are not significantly different (i.e., they are roughly equal and
sphericity can be assumed).

Abb. 161 Ausgabe der einfaktoriellen ANOVA mit Messwiederholung: Mauchly’s Test auf Sphärizität
Wenn andererseits Mauchly’s Test signifikant gewesen wäre (p < 0,05), dann würden wir schlussfolgern, dass es signifikante Unterschiede zwischen der Varianz der Differenzwerte gibt und die Anforderung der Sphärizität nicht erfüllt ist. In diesem Fall sollten wir eine Korrektur auf den F-Wert anwenden, den wir in der einfaktoriellen ANOVA erhalten haben:
If the
Greenhouse-Geisser εvalue in theTests of Sphericitytable is > 0.75 then you should use the Huynh-Feldt correction.But if the
Greenhouse-Geisser εvalue is < 0.75, then you should use the Greenhouse-Geisser correction.
Both these corrected F-values can be specified in the Sphericity
Corrections check boxes under the Assumption Checks options, and the
corrected F-values are then shown in the results table, as in
Abb. 162.
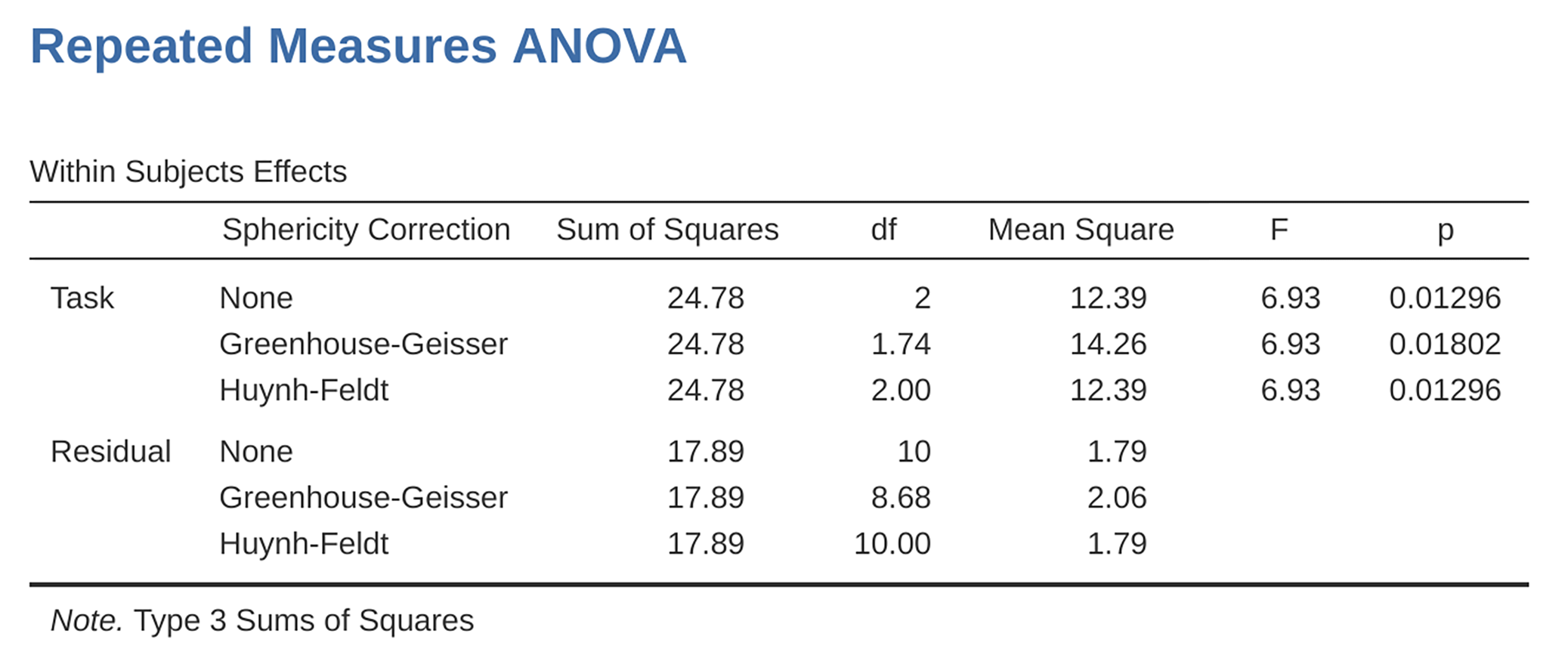
Abb. 162 Ausgabe der einfaktoriellen ANOVA mit Messwiederholung: Tests von Effekten innerhalb der Probanden
In our analysis, we saw that the significance of Mauchly’s Test of Sphericity
was p = 0.720 (i.e., p > 0.05). So, this means we can assume that the
requirement of sphericity has been met so no correction to the F-value is
needed. Therefore, we can use the None Sphericity Correction output values
for the repeated measure Task: F = 6.93, df1 = 2, df2 = 10,
p = 0.013, and we can conclude that the number of tests successfully
completed on each language task did vary significantly depending on whether
the task was speech, comprehension or syntax based (F(2,10) = 6.93,
p = 0.013).
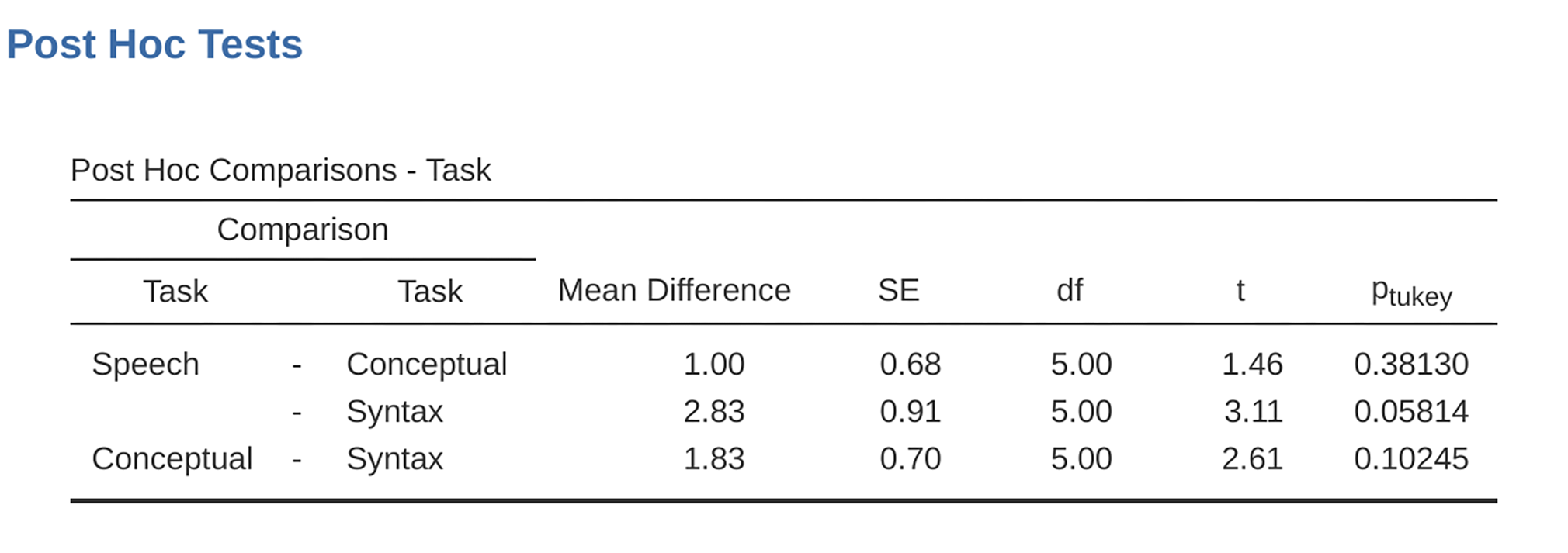
Abb. 163 Post-hoc-Tests bei der ANOVA mit Messwiederholung in jamovi
Post-hoc tests can also be specified in jamovi for repeated measures ANOVA in
the same way as for an independent ANOVA. The results are shown in
Abb. 163. These indicate that there is a significant difference
between Speech and Syntax, but not between other levels.
Descriptive statistics (marginal means) can be reviewed to help interpret the
results, produced in the jamovi output as in Abb. 164. Comparison of
the mean number of trials successfully completed by participants shows that
Broca’s Aphasics perform reasonably well on speech production (mean = 7.17) and
language comprehension (mean = 6.17) tasks. However, their performance was
considerably worse on the syntax task (mean = 4.33), with a significant
difference in post-hoc tests between Speech and Syntax task
performance.
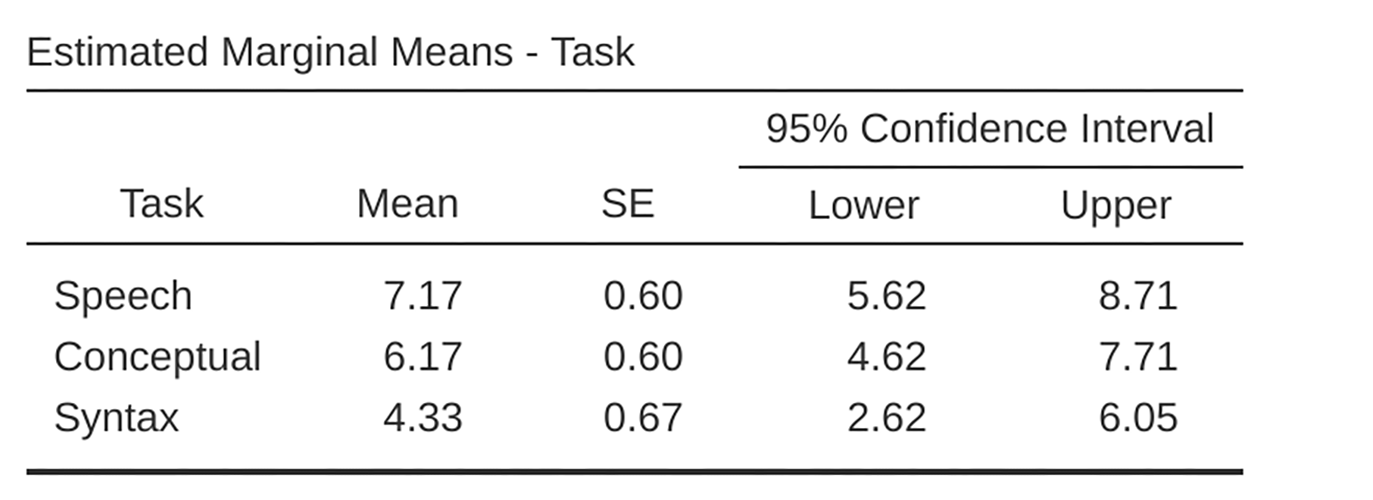
Abb. 164 Ausgabe der einfaktoriellen ANOVA mit Messwiederholung: Deskriptive Statistik