Autor des Abschnitts: Danielle J. Navarro and David R. Foxcroft
Stichprobenverteilungen und der zentrale Grenzwertsatz
The law of large numbers is a very powerful tool but it is not going to be good enough to answer all our questions. Among other things, all it gives us is a “long run guarantee”. In the long run, if we were somehow able to collect an infinite amount of data, then the law of large numbers guarantees that our sample statistics will be correct. But as John Maynard Keynes famously argued in economics, a long run guarantee is of little use in real life.
Die Langfristigkeit ist ein irreführender Leitfaden für aktuelle Angelegenheiten. Auf lange Sicht sind wir alle tot. Die Ökonomen machen es sich zu leicht, zu nutzlos, wenn sie uns in stürmischen Zeiten nur sagen können, dass das Meer wieder flach ist, wenn der Sturm längst vorüber ist (Keynes, 1923).
Wie in der Wirtschaft gilt dies auch für die Psychologie und die Statistik. Es reicht nicht aus, zu wissen, dass wir langfristig die richtige Antwort erhalten, wenn wir den Stichprobenmittelwert berechnen. Das Wissen, dass ein unendlich großer Datensatz mir den genauen Wert des Mittelwerts der Grundgesamtheit sagen wird, ist ein schwacher Trost, wenn mein tatsächlicher Datensatz einen Stichprobenumfang von N = 100 hat. Im wirklichen Leben müssen wir also etwas über das Verhalten des Stichprobenmittelwerts wissen, wenn er aus einem bescheideneren Datensatz berechnet wird!
Stichprobenverteilung des Mittelwerts
With this in mind, let us abandon the idea that our studies will have sample
sizes of 10 000 and consider instead a very modest experiment indeed. This time
around we will sample N = 5 people and measure their IQ scores. As before, I
can simulate this experiment in jamovi = NORM(100, 15) function, but I only
need five participant IDs this time, not 10 000. These are the five numbers
that jamovi generated:
90 82 94 99 110
The mean IQ in this sample turns out to be exactly 95. Not surprisingly, this is much less accurate than the previous experiment. Now imagine that I decided to replicate the experiment. That is, I repeat the procedure as closely as possible and I randomly sample five new people and measure their IQ. Again, jamovi allows me to simulate the results of this procedure, and generates these five numbers:
78 88 111 111 117
Dieses Mal liegt der mittlere IQ in meiner Stichprobe bei 101. Wenn ich das Experiment 10 Mal wiederhole, erhalte ich die in Tab. 8 gezeigten Ergebnisse, und wie Sie sehen können, variiert der Stichprobenmittelwert von einer Wiederholung zur nächsten.
Person 1 |
Person 2 |
Person 3 |
Person 4 |
Person 5 |
Stichprobenmittelwert |
|
|---|---|---|---|---|---|---|
Replikation 1 |
90 |
82 |
94 |
99 |
110 |
95.0 |
Replikation 2 |
78 |
88 |
111 |
111 |
117 |
101.0 |
Replikation 3 |
111 |
122 |
91 |
98 |
86 |
101.6 |
Replikation 4 |
98 |
96 |
119 |
99 |
107 |
103.8 |
Replikation 5 |
105 |
113 |
103 |
103 |
98 |
104.4 |
Replikation 6 |
81 |
89 |
93 |
85 |
114 |
92.4 |
Replikation 7 |
100 |
93 |
108 |
98 |
133 |
106.4 |
Replikation 8 |
107 |
100 |
105 |
117 |
85 |
102.8 |
Replikation 9 |
86 |
119 |
108 |
73 |
116 |
100.4 |
Replikation 10 |
95 |
126 |
112 |
120 |
76 |
105.8 |
Now suppose that I decided to keep going in this fashion, replicating this “five IQ scores” experiment over and over again. Every time I replicate the experiment I write down the sample mean. Over time, I would be amassing a new data set, in which every experiment generates a single data point. The first 10 observations from my data set are the sample means listed in Tab. 8, so my data set starts out like this:
95.0 101.0 101.6 103.8 104.4 …
What if I continued like this for 10 000 replications, and then drew a histogram. Well that is exactly what I did, and you can see the results in Abb. 74. As this picture illustrates, the average of 5 IQ scores is usually between 90 and 110. But more importantly, what it highlights is that if we replicate an experiment over and over again, what we end up with is a distribution of sample means! This distribution has a special name in statistics, it is called the sampling distribution of the mean.
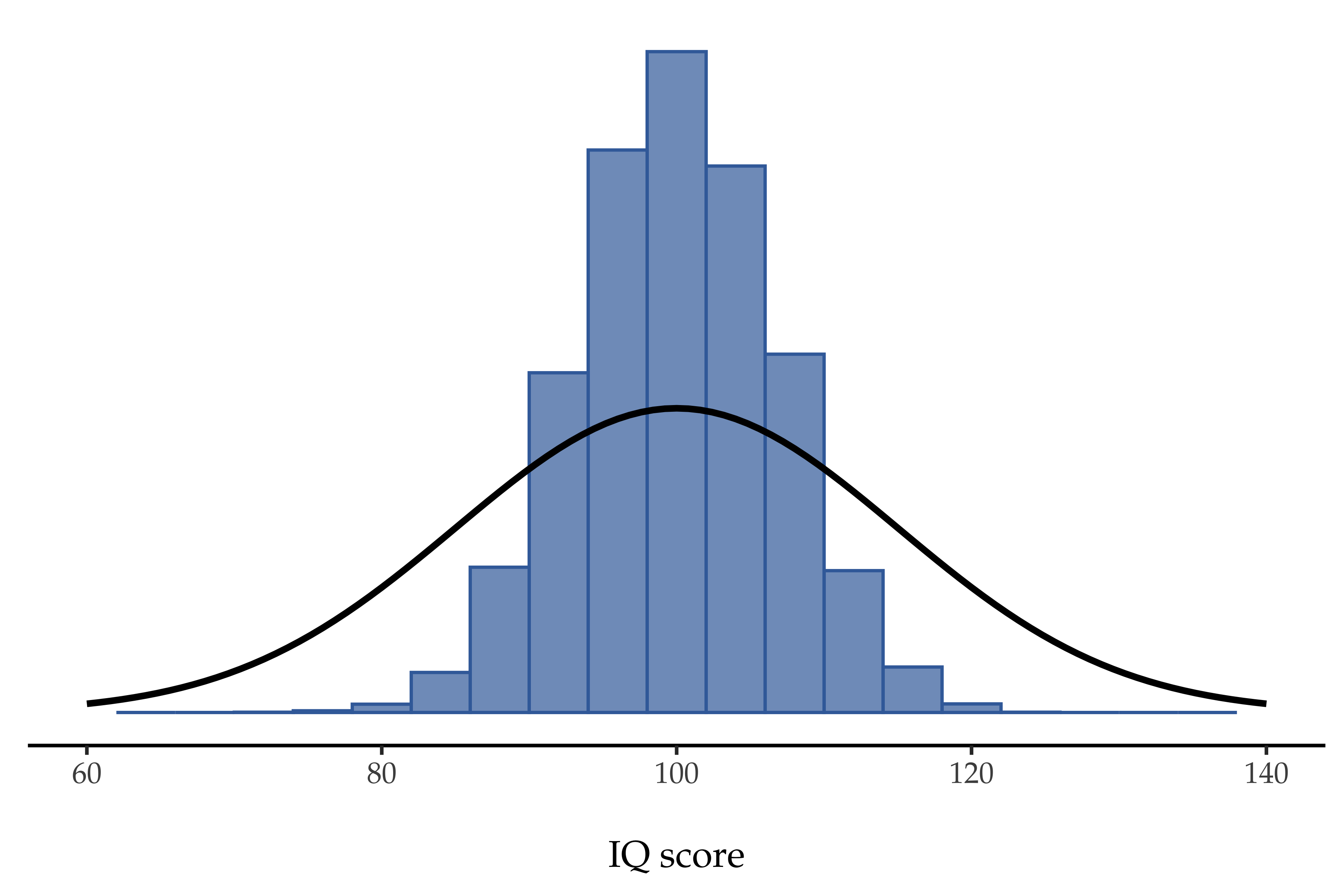
Abb. 74 The sampling distribution of the mean for the “five IQ scores experiment”: If you sample five people at random and calculate their average IQ you will almost certainly get a number between 80 and 120, even though there are quite a lot of individuals who have IQs above 120 or below 80. For comparison, the black line plots the population distribution of IQ scores.
Sampling distributions are another important theoretical idea in statistics, and they are crucial for understanding the behaviour of small samples. For instance, when I ran the very first “five IQ scores” experiment, the sample mean turned out to be 95. What the sampling distribution in Abb. 74 tells us, though, is that the “five IQ scores” experiment is not very accurate. If I repeat the experiment, the sampling distribution tells me that I can expect to see a sample mean anywhere between 80 and 120.
Stichprobenverteilungen existieren für jede Stichprobenstatistik!
Wenn Sie über Stichprobenverteilungen nachdenken, sollten Sie daran denken, dass jede Stichprobenstatistik, die Sie berechnen möchten, eine Stichprobenverteilung hat. Nehmen wir zum Beispiel an, dass ich jedes Mal, wenn ich das Experiment „fünf IQ-Werte“ wiederhole, den höchsten IQ-Wert des Experiments notiere. Dadurch würde ich einen Datensatz erhalten, der wie folgt beginnt:
110 117 122 119 113 …
Doing this over and over again would give me a very different sampling distribution, namely the sampling distribution of the maximum. The sampling distribution of the maximum of 5 IQ scores is shown in Abb. 75. Not surprisingly, if you pick five people at random and then find the person with the highest IQ score, they are going to have an above average IQ. Most of the time you will end up with someone whose IQ is measured in the 100 to 140 range.
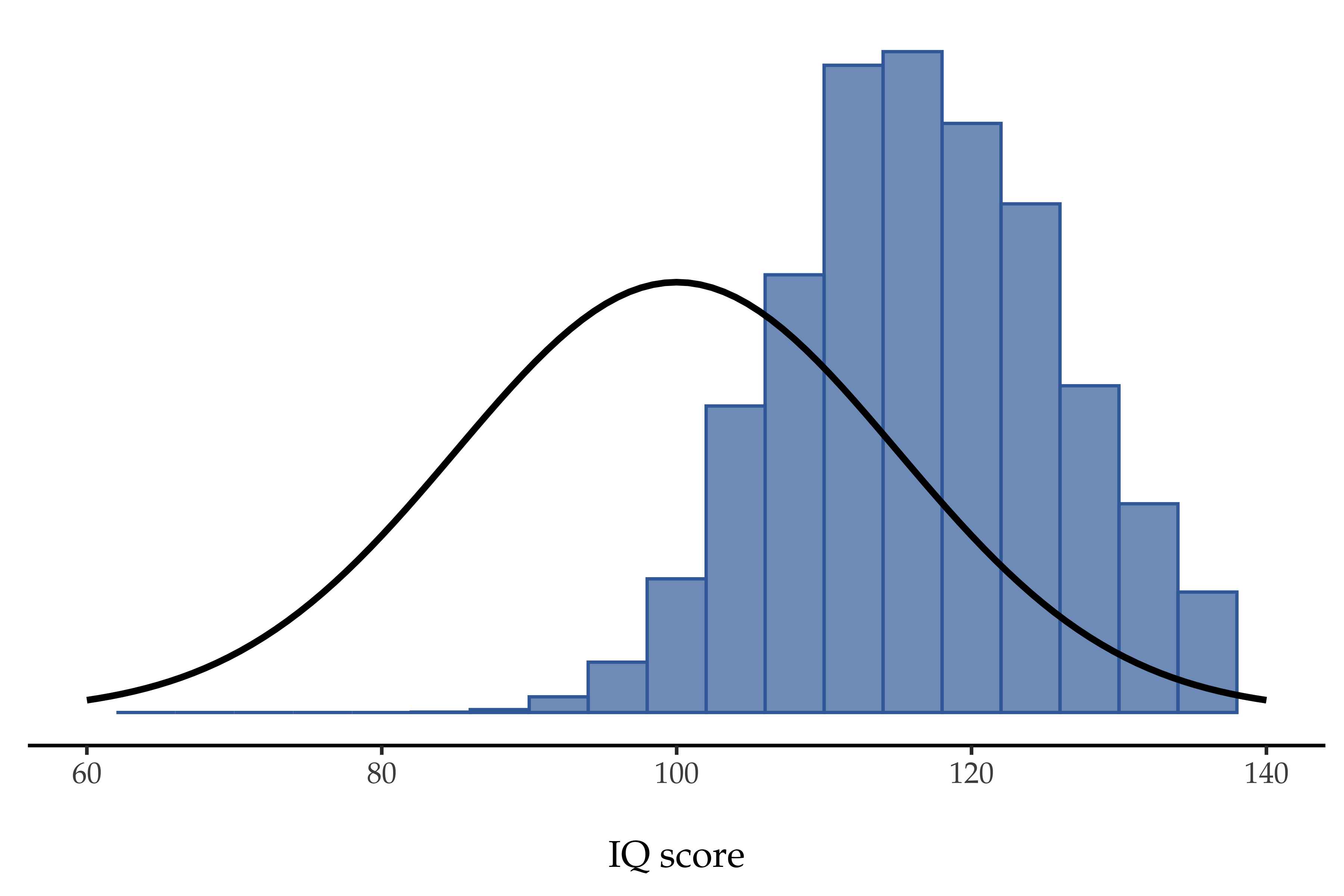
Abb. 75 The sampling distribution of the maximum for the “five IQ scores experiment”: If you sample five people at random and select the one with the highest IQ score you will probably see someone with an IQ between 100 and 140.
Der zentrale Grenzwertsatz
At this point I hope you have a pretty good sense of what sampling distributions are, and in particular what the sampling distribution of the mean is. In this section I want to talk about how the sampling distribution of the mean changes as a function of sample size. Intuitively, you already know part of the answer. If you only have a few observations, the sample mean is likely to be quite inaccurate. If you replicate a small experiment and recalculate the mean you will get a very different answer. In other words, the sampling distribution is quite wide. If you replicate a large experiment and recalculate the sample mean you will probably get the same answer you got last time, so the sampling distribution will be very narrow. You can see this visually in Abb. 76, showing that the bigger the sample size, the narrower the sampling distribution gets: In panel (a), each data set contained only a single observation, so the mean of each sample is just one person’s IQ score. As a consequence, the sampling distribution of the mean is of course identical to the population distribution of IQ scores. In panel (b), we raise the sample size to 2, and the mean of any one sample tends to be closer to the population mean than a one person’s IQ score, and so the histogram (i.e., the sampling distribution) is a bit narrower than the population distribution. In panel (c), we raise the sample size to 10 (right panel), and we can see that the distribution of sample means tend to be fairly tightly clustered around the true population mean.
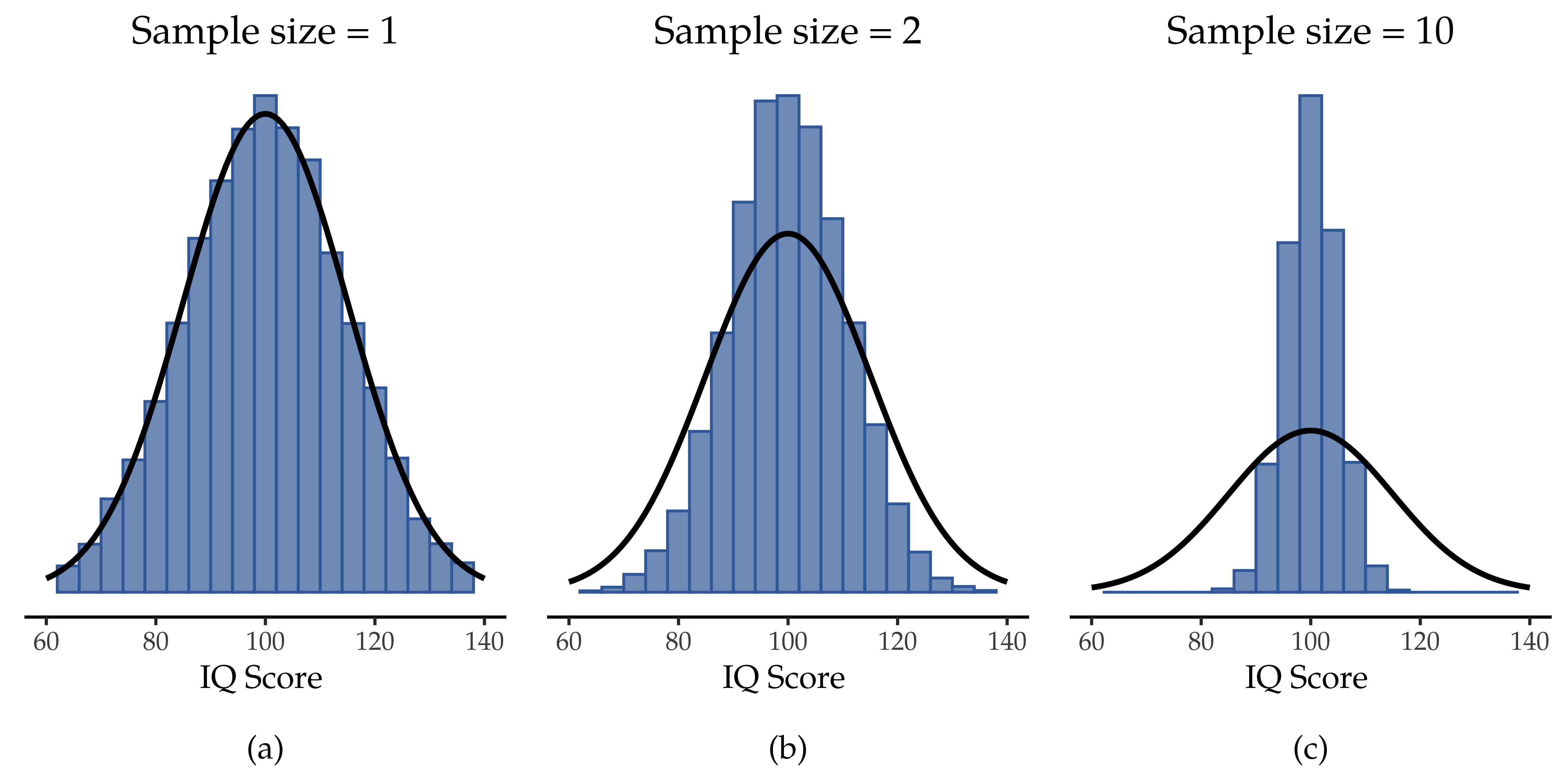
Abb. 76 Illustration of the how sampling distribution of the mean depends on sample size. In each panel I generated 10 000 samples of IQ data and calculated the mean IQ observed within each of these data sets. The histograms in these plots show the distribution of these means (i.e., the sampling distribution of the mean). Each individual IQ score was drawn from a normal distribution with mean 100 and standard deviation 15, which is shown as the solid black line.
We can quantify this effect by calculating the standard deviation of the sampling distribution, which is referred to as the standard error. The standard error of a statistic is often denoted SE, and since we are usually interested in the standard error of the sample mean, we often use the acronym SEM. As you can see just by looking at the picture, as the sample size N increases, the SEM decreases.
Okay, so that is one part of the story. However, there is something I have been glossing over so far. All my examples up to this point have been based on the “IQ scores” experiments, and because IQ scores are roughly normally distributed I have assumed that the population distribution is normal. What if it is not normal? What happens to the sampling distribution of the mean? The remarkable thing is this, no matter what shape your population distribution is, as N increases the sampling distribution of the mean starts to look more like a normal distribution. To give you a sense of this I ran some simulations. To do this, I started with the “ramped” distribution shown in the histogram in Abb. 77 (a). As you can see by comparing the triangular shaped histogram to the bell curve plotted by the black line, the population distribution does not look very much like a normal distribution at all. Next, I simulated the results of a large number of experiments. In each experiment I took N = 2 samples from this distribution, and then calculated the sample mean. Abb. 77 (b) plots the histogram of these sample means (i.e., the sampling distribution of the mean for N = 2). This time, the histogram produces a ∩-shaped distribution. It is still not normal, but it is a lot closer to the black line than the population distribution in Abb. 77 (a). When I increase the sample size to N = 4, the sampling distribution of the mean is very close to normal (Abb. 77, c), and by the time we reach a sample size of N = 8 (Abb. 77, d) it is almost perfectly normal. In other words, as long as your sample size is not tiny, the sampling distribution of the mean will be approximately normal no matter what your population distribution looks like!
Abb. 77 Demonstration of the central limit theorem: In the panel (a), we have a non-normal population distribution, and the remaining panels show the sampling distribution of the mean for samples of size 2 (panel b), 4 (panel c) and 8 (panel d) for data drawn from the distribution in the top-left panel. As you can see, even though the original population distribution is non-normal the sampling distribution of the mean becomes pretty close to normal by the time you have a sample of even four observations.
On the basis of these figures, it seems like we have evidence for all of the following claims about the sampling distribution of the mean:
The mean of the sampling distribution is the same as the mean of the population.
The standard deviation of the sampling distribution (i.e., the standard error) gets smaller as the sample size increases.
The shape of the sampling distribution becomes normal as the sample size increases.
As it happens, not only are all of these statements true, there is a very famous theorem in statistics that proves all three of them, known as the central limit theorem. Among other things, the central limit theorem tells us that if the population distribution has mean µ and standard deviation σ, then the sampling distribution of the mean also has mean µ and the standard error of the mean is:
Because we divide the population standard deviation σ by the square root of the sample size N, the SEM gets smaller as the sample size increases. It also tells us that the shape of the sampling distribution becomes normal.[1]
Dieses Ergebnis ist für alle möglichen Dinge nützlich. Es sagt uns, warum große Experimente zuverlässiger sind als kleine, und weil es eine explizite Formel für den Standardfehler angibt, sagt es uns wie viel zuverlässiger ein großes Experiment ist. Sie sagt uns auch, warum die Normalverteilung, normal ist. In realen Experimenten sind viele der Dinge, die wir messen wollen, eigentlich Durchschnittswerte aus vielen verschiedenen Größen (z. B. ist die „allgemeine“ Intelligenz, die durch den IQ gemessen wird, wohl ein Durchschnittswert aus einer großen Anzahl „spezifischer“ Fähigkeiten und Fertigkeiten), und wenn das passiert, sollte die gemittelte Größe einer Normalverteilung folgen. Aufgrund dieses mathematischen Gesetzes taucht die Normalverteilung immer wieder in realen Daten auf.