Section author: Danielle J. Navarro and David R. Foxcroft
ANOVA ஒரு நேரியல் மாதிரியாக
ANOVA மற்றும் பின்னடைவு பற்றி புரிந்து கொள்ள வேண்டிய மிக முக்கியமான விசயங்களில் ஒன்று, அவை அடிப்படையில் ஒரே சேதி. அதன் மேற்பரப்பில், இது உண்மை என்று நீங்கள் நினைக்க மாட்டீர்கள். எல்லாவற்றிற்கும் மேலாக, நான் இதுவரை அவற்றை விவரித்த விதம், ANOVA முதன்மையாக குழு வேறுபாடுகளுக்கான சோதனையில் அக்கறை கொண்டுள்ளது என்று கூறுகிறது, மேலும் பின்னடைவு முதன்மையாக மாறிகளுக்கு இடையிலான தொடர்புகளைப் புரிந்துகொள்வதில் அக்கறை கொண்டுள்ளது. மேலும், அது செல்லும் வரையில் அது உண்மைதான். ஆனால் நீங்கள் பேட்டைக்கு அடியில் பார்க்கும்போது, பேசுவதற்கு, ANOVA மற்றும் பின்னடைவின் அடிப்படை இயக்கவியல் மிகவும் ஒத்திருக்கிறது. உண்மையில், நீங்கள் இதைப் பற்றி சிந்தித்தால், இதற்கான ஆதாரங்களை நீங்கள் ஏற்கனவே பார்த்திருக்கிறீர்கள். ANOVA மற்றும் பின்னடைவு இரண்டும் சதுரங்களின் தொகையை (SS) பெரிதும் நம்பியுள்ளன, இவை இரண்டும் *F *-Tests ஐப் பயன்படுத்துகின்றன, மற்றும் பல. திரும்பிப் பார்க்கும்போது, அத்தியாயங்கள்: ../ CH12/CH12_REGRESSION மற்றும்: DOC:` ../ CH13/CH13_ANOVA` சற்று மீண்டும் மீண்டும் வந்தன என்ற உணர்விலிருந்து தப்பிப்பது கடினம்.
இதற்குக் காரணம், ANOVA மற்றும் பின்னடைவு ஆகியவை ** நேரியல் மாதிரிகள் **. பின்னடைவு விசயத்தில், இது ஒருவிதமான வெளிப்படையானது. முன்னறிவிப்பாளர்களுக்கும் விளைவுகளுக்கும் இடையிலான உறவை வரையறுக்க நாம் பயன்படுத்தும் பின்னடைவு சமன்பாடு * ஒரு நேர் கோட்டிற்கான சமன்பாடு *, எனவே இது ஒரு நேரியல் மாதிரி, சமன்பாட்டுடன்
எங்கே *y *: sub: p என்பது *p *-th கண்காணிப்புக்கான விளைவு மதிப்பு (எ.கா., *p *-th நபர்), *x *: துணை:` 1p` என்பது முதல்வரின் மதிப்பு *p *-th கண்காணிப்புக்கான முன்கணிப்பு, *x *: துணை: 2p என்பது *p *-th அவதானிப்புக்கான இரண்டாவது முன்கணிப்பாளரின் மதிப்பு, *b *: துணை:` 0`, *b . நாம் எச்சங்களை புறக்கணித்தால் *ϵ *: sub: p மற்றும் பின்னடைவு வரியில் கவனம் செலுத்துங்கள், பின்வரும் சூத்திரத்தைப் பெறுகிறோம்:
எங்கே *ŷ *: துணை: p என்பது *y *இன் மதிப்பு *y *இன் மதிப்பு *p *க்கு பின்னடைவு வரி கணிக்கிறது, உண்மையில் கவனிக்கப்பட்ட மதிப்புக்கு மாறாக *y *: sub:` p`. உடனடியாகத் தெரியாத சேதி என்னவென்றால், ANOVA ஐ ஒரு நேரியல் மாதிரியாக எழுதலாம். இருப்பினும், இதைச் செய்வது உண்மையில் மிகவும் நேரடியானது. 2 × 2 காரணி ANOVA ஐ ஒரு நேரியல் மாதிரியாக மீண்டும் எழுதுகையில், மிகவும் எளிமையான எடுத்துக்காட்டுடன் ஆரம்பிக்கலாம்.
சில தரவு
விசயங்களை உறுதியானதாக மாற்ற, எங்கள் விளைவு மாறி எனது வகுப்பில் ஒரு மாணவர் பெறும் `` கிரேடு`` என்று வைத்துக்கொள்வோம், இது 0 % முதல் 100 % வரை ஒரு அடையாளத்துடன் தொடர்புடைய விகித அளவிலான மாறி. ஆர்வத்தின் இரண்டு முன்கணிப்பு மாறிகள் உள்ளன: மாணவர் விரிவுரைகளுக்கு மாறினாரா இல்லையா (`` கலந்து கொள்ளுங்கள்` மாறுபாடு) மற்றும் மாணவர் உண்மையில் பாடப்புத்தகத்தைப் படிக்கிறாரா இல்லையா ( வாசிப்பு` மாறி). மாணவர் வகுப்பில் கலந்து கொண்டால் `` கலந்து கொள்ளுங்கள் = 1`` என்று கூறுவோம், அவர்கள் அவ்வாறு செய்யாவிட்டால் `` கலந்து கொள்ளுங்கள் = 0``. இதேபோல், மாணவர் பாடப்புத்தகத்தைப் படித்தால் `` வாசிப்பு = 1``, மற்றும் அவர்கள் அவ்வாறு செய்யாவிட்டால் `` படித்தல் = 0`` என்று கூறுவோம்.
சரி, இதுவரை அது போதுமானது. நாம் செய்ய வேண்டிய அடுத்த சேதி என்னவென்றால், இதைச் சுற்றி சில கணிதங்களை மடிக்க வேண்டும் (மன்னிக்கவும்!). இந்த எடுத்துக்காட்டின் நோக்கங்களுக்காக, *y *: sub: p வகுப்பில் உள்ள *p *-th மாணவரின்` தர` ஐக் குறிக்கிறது. இந்த அத்தியாயத்தில் நாம் முன்னர் பயன்படுத்திய அதே குறியீடு இது அல்ல. முன்னதாக, முன்கணிப்பு 1 (வரிசை காரணி) மற்றும் *c *-th குழு ஆகியவற்றிற்கான *r *-th குழுவில் உள்ள I-TH நபரைக் குறிக்க *y *: y: your: rci என்ற குறியீட்டைப் பயன்படுத்தினோம் முன்கணிப்பு 2 க்கு (நெடுவரிசை காரணி). SS மதிப்புகள் எவ்வாறு கணக்கிடப்படுகின்றன என்பதை விவரிக்க இந்த நீட்டிக்கப்பட்ட குறியீடு மிகவும் எளிது, ஆனால் இது தற்போதைய சூழலில் ஒரு வலி, எனவே நான் இங்கே குறியீட்டை மாற்றுவேன். இப்போது, *y *: துணை: p குறியீடு *y *: துணை:` rci` ஐ விட பார்வைக்கு எளிமையானது, ஆனால் அது உண்மையில் குழு உறுப்பினர்களைக் கண்காணிக்காது என்ற குறைபாட்டைக் கொண்டுள்ளது! அதாவது, *y *: துணை: 0,0,3 = 35 என்று நான் உங்களிடம் சொன்னால், நாங்கள் ஒரு மாணவனைப் பற்றி (அத்தகைய 3 வது மாணவர், உண்மையில்) பேசவில்லை என்பதை நீங்கள் உடனடியாக அறிவீர்கள் ' சொற்பொழிவுகளில் கலந்து கொள்ளுங்கள் (அதாவது, `` கலந்து கொள்ளுங்கள் = 0``) மற்றும் பாடப்புத்தகத்தைப் படிக்கவில்லை (அதாவது `` வாசிப்பு = 0``), மற்றும் வகுப்பில் தோல்வியுற்றவர் (`` தகுதி = 35``). ஆனால் *y *: sub: p = 35 என்று நான் உங்களுக்குச் சொன்னால், உங்களுக்குத் தெரிந்ததெல்லாம் *p *-th மாணவருக்கு நல்ல தரத்தைப் பெறவில்லை. சில முக்கிய தகவல்களை இங்கே இழந்துவிட்டோம். நிச்சயமாக, இதை எவ்வாறு சரிசெய்வது என்பதைக் கண்டுபிடிக்க இது நிறைய சிந்தனையை எடுக்காது. அதற்கு பதிலாக நாங்கள் என்ன செய்வோம் என்பது இரண்டு புதிய மாறிகளை அறிமுகப்படுத்துவதாகும் *x *: துணை: 1p மற்றும் *x *: இந்த தகவலை கண்காணிக்கும் துணை:` 2p`. எங்கள் கற்பனையான மாணவரின் விசயத்தில், *x *: துணை: 1p = 0 (அதாவது,` கலந்து கொள்ளுங்கள் = 0`) மற்றும் *x *: துணை:` 2p` = 0 (அதாவது, `` வாசிப்பு = 0``). எனவே தரவு இப்படி தோன்றலாம்:
நபர், ப |
|||
|---|---|---|---|
1 |
90 |
1 |
1 |
2 |
87 |
1 |
1 |
3 |
75 |
0 |
1 |
4 |
60 |
1 |
0 |
5 |
35 |
0 |
0 |
6 |
50 |
0 |
0 |
7 |
65 |
1 |
0 |
8 |
70 |
0 |
1 |
இது குறிப்பாக சிறப்பு இல்லை. இது எங்கள் தரவைப் பார்க்க எதிர்பார்க்கும் வடிவம்! | Rtfm | _ தரவு தொகுப்பு பார்க்கவும். இந்த தரவு தொகுப்பு ஒரு சீரான வடிவமைப்பிற்கு ஒத்திருக்கிறது என்பதை உறுதிப்படுத்த `` விளக்கங்கள்`` ஐப் பயன்படுத்தலாம், ஒவ்வொரு கலவைக்கும் 2 அவதானிப்புகள் கலந்து கொள்ளுங்கள் மற்றும்` வாசிப்பு`. அதே வழியில் ஒவ்வொரு கலவைக்கும் சராசரி தரத்தையும் கணக்கிடலாம். இது காட்டப்பட்டுள்ளது: NumRef: Fig-RTFMDescriptives. சராசரி மதிப்பெண்களைப் பார்க்கும்போது, உரையைப் படிப்பதும் வகுப்பில் கலந்துகொள்வதும் இருவருக்கும் நிறைய முதன்மை என்ற வலுவான எண்ணத்தை ஒருவர் பெறுகிறார்.
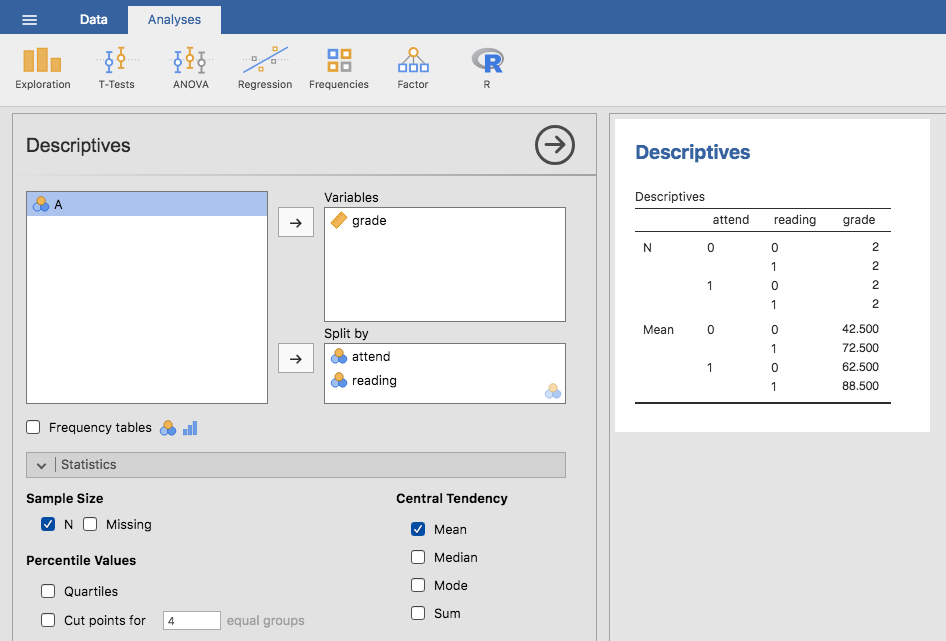
பின்னடைவு மாதிரியாக பைனரி காரணிகளுடன் ANOVA
சரி, கணிதத்தைப் பற்றி பேசுவோம். எங்கள் தரவு இப்போது மூன்று எண் மாறிகள் அடிப்படையில் வெளிப்படுத்தப்பட்டுள்ளது: தொடர்ச்சியான மாறி *y *மற்றும் இரண்டு பைனரி மாறிகள் *x *: துணை: 1 மற்றும் *x *: துணை:` 2`. நீங்கள் அடையாளம் காண விரும்புவது என்னவென்றால், எங்கள் 2 × 2 காரணி ANOVA * பின்னடைவு மாதிரிக்கு சமம் * சரியாக * உள்ளது:
நிச்சயமாக, இது இரண்டு-ப்ரெடிக்டர் பின்னடைவு மாதிரியை விவரிக்க நான் முன்பு பயன்படுத்திய அதே சமன்பாடு! ஒரே வேறுபாடு என்னவென்றால், *x *: துணை: 1 மற்றும் *x *: துணை:` 2` இப்போது *பைனரி *மாறிகள் (அதாவது, மதிப்புகள் 0 அல்லது 1 ஆக மட்டுமே இருக்க முடியும்), அதேசமயம் ஒரு பின்னடைவு பகுப்பாய்வில் நாம் *x *: துணை: 1 மற்றும் *x *: துணை:` 2` தொடர்ச்சியாக இருக்கும் என்று எதிர்பார்க்கலாம். இதைப் பற்றி நான் உங்களை நம்ப வைக்க சில வழிகள் உள்ளன. இரண்டும் ஒரே மாதிரியானவை என்பதை நிரூபிக்கும் ஒரு நீண்ட கணித பயிற்சியைச் செய்வதே ஒரு வாய்ப்பு. இருப்பினும், நான் ஒரு மூட்டுக்கு வெளியே சென்று இந்த புத்தகத்தின் வாசகர்களின் பெரும்பகுதி உதவியைக் காட்டிலும் எரிச்சலூட்டுவதைக் காணும் என்று நினைக்கிறேன். அதற்கு பதிலாக, நான் அடிப்படை யோசனைகளை விளக்குகிறேன், பின்னர் ANOVA பகுப்பாய்வுகள் மற்றும் பின்னடைவு பகுப்பாய்வுகள் ஒத்தவை அல்ல என்பதைக் காட்ட சமோவியை நம்பியிருக்கிறேன், அவை எல்லா நோக்கங்களுக்கும் நோக்கங்களுக்கும் ஒரே மாதிரியானவை. இதை ANOVA ஆக இயக்குவதன் மூலம் ஆரம்பிக்கலாம். இதைச் செய்ய, நாங்கள் | rtfm | _ தரவு தொகுப்பைப் பயன்படுத்துவோம், மேலும்: NumRef: fig-factoralananova6 சமோவியில் பகுப்பாய்வை இயக்கும்போது நமக்குப் பெறுவதைக் காட்டுகிறது.

Fig. 160 ANOVA of the rtfm data set in jamovi: Model with two factors attend
and reading but without the interaction term for these two factors
எனவே, ANOVA அட்டவணையின் முக்கிய எண்களையும், நாங்கள் முன்பு வழங்கிய சராசரி மதிப்பெண்களையும் படிப்பதன் மூலம், மாணவர்கள் வகுப்பில் (f(1,5) = 21.6,*ப* = 0.0056) மற்றும் அவர்கள் பாடப்புத்தகத்தைப் படித்தால்:f(1,5) = 52.3,*ப*= 0.0008. அந்த *பி *-மதிப்புகள் மற்றும் அந்த *எஃப் *-புள்ளிவிவரங்கள் ஆகியவற்றைக் குறிப்போம்.
இப்போது ஒரு நேரியல் பின்னடைவு கண்ணோட்டத்தில் அதே பகுப்பாய்வைப் பற்றி சிந்திக்கலாம். | Rtfm | _ தரவு தொகுப்பில், நாங்கள் `` கலந்துகொள்ளும்`` மற்றும் `` படித்தல்`` அவர்கள் எண் முன்கணிப்பாளர்களாக இருப்பதைப் போல குறியிட்டுள்ளோம். இந்த விசயத்தில், இது முற்றிலும் ஏற்றுக்கொள்ளத்தக்கது. வகுப்பிற்கு திரும்பும் ஒரு மாணவர் (அதாவது. எனவே பின்னடைவு மாதிரியில் முன்னறிவிப்பாளராக இதைச் சேர்ப்பது நியாயமற்றது. இது கொஞ்சம் அசாதாரணமானது, ஏனென்றால் முன்கணிப்பு இரண்டு சாத்தியமான மதிப்புகளை மட்டுமே எடுத்துக்கொள்கிறது, ஆனால் இது நேரியல் பின்னடைவின் எந்த அனுமானங்களையும் மீறாது. அதை விளக்குவது எளிது. `` கலந்துகொள்ளும்` க்கான பின்னடைவு குணகம் 0 ஐ விட அதிகமாக இருந்தால், விரிவுரைகளில் கலந்து கொள்ளும் மாணவர்கள் அதிக தரங்களைப் பெறுகிறார்கள் என்பதாகும். இது பூச்சியத்தை விடக் குறைவாக இருந்தால், விரிவுரைகளில் கலந்து கொள்ளும் மாணவர்கள் குறைந்த தரங்களைப் பெறுகிறார்கள். எங்கள் ` வாசிப்பு`` மாறிக்கும் இதே நிலைதான்.
ஒரு நொடி காத்திருங்கள். * ஏன்* இது உண்மை? இது சில புள்ளிவிவர வகுப்புகளை எடுத்த மற்றும் கணிதத்துடன் வசதியாக இருக்கும் அனைவருக்கும் உள்ளுணர்வாக வெளிப்படையான ஒன்று, ஆனால் இது முதல் பாசில் மற்ற அனைவருக்கும் தெளிவாக இல்லை. இது ஏன் உண்மை என்று பார்க்க, இது ஒரு சில குறிப்பிட்ட மாணவர்களை உற்று நோக்க உதவுகிறது. எங்கள் தரவுத் தொகுப்பில் 6 மற்றும் 7 வது மாணவர்களைக் கருத்தில் கொண்டு ஆரம்பிக்கலாம் (அதாவது பி = 6 மற்றும் பி = 7). யாரும் பாடப்புத்தகத்தைப் படிக்கவில்லை, எனவே இரண்டு சந்தர்ப்பங்களிலும் `` வாசிப்பு = 0`` ஐ அமைக்கலாம். அல்லது, எங்கள் கணிதக் குறியீட்டில் இதே விசயத்தைச் சொல்ல, *x *: துணை: 2,6 = 0 மற்றும் *x *: துணை:` 2,7` = 0. இருப்பினும், மாணவர் எண் 7 செய்தது விரிவுரைகளுக்கு திரும்பவும் (அதாவது, `` கலந்து கொள்ளுங்கள் = 1``, *x *: துணை: 1,7 = 1) மாணவர் எண் 6 இல்லை (அதாவது,` கலந்து கொள்ளுங்கள் = 0`, *x * : துணை: 1,6 = 0). எங்கள் பின்னடைவு வரிக்கான பொது சூத்திரத்தில் இந்த எண்களைச் செருகும்போது என்ன நடக்கும் என்பதைப் பார்ப்போம். மாணவர் எண் 6 க்கு, பின்னடைவு இதை முன்னறிவிக்கிறது:
எனவே இந்த மாணவர் *B *: துணை: 0 இடைமறிப்பு காலத்தின் மதிப்புக்கு ஒத்த தரத்தைப் பெறுவார் என்று நாங்கள் எதிர்பார்க்கிறோம். மாணவர் 7 பற்றி என்ன? இந்த முறை பின்னடைவு வரிக்கான சூத்திரத்தில் எண்களைச் செருகும்போது, பின்வருவனவற்றைப் பெறுகிறோம்:
இந்த மாணவர் வகுப்பில் கலந்துகொண்டதால், கணிக்கப்பட்ட தகுதி b *: துணை: `0` *பிளச் *` `கலந்துகொள்ளும்`` மாறுபாடு, *பி *: துணை: `1` . எனவே, *b *: துணை: `1` பூச்சியத்தை விட அதிகமாக இருந்தால், விரிவுரைகளுக்கு திரும்பும் மாணவர்கள் இல்லாத மாணவர்களை விட அதிக தரங்களைப் பெறுவார்கள் என்று நாங்கள் எதிர்பார்க்கிறோம். இந்த குணகம் எதிர்மறையாக இருந்தால், நாங்கள் இதற்கு நேர்மாறாக எதிர்பார்க்கிறோம்: வகுப்பில் வரும் மாணவர்கள் மிகவும் மோசமாக செயல்படுகிறார்கள். உண்மையில், இதை நாம் இன்னும் கொஞ்சம் தள்ளலாம். மாணவர் எண் 1 பற்றி, வகுப்பிற்கு (*x: துணை: 1,1 = 1)**மற்றும்*பாடப்புத்தகத்தைப் படியுங்கள் (x: துணை:` 2,1` = 1)? இந்த எண்களை நாம் பெறும் பின்னடைவில் செருகினால்:
ஆகவே, கலந்துகொள்வது ஒரு நல்ல தரத்தைப் பெற உதவுகிறது என்று நாங்கள் கருதினால் : துணை: 2> 0), மாணவர் 1 மற்றும் மாணவர் 7 ஐ விட அதிகமான தரத்தை மாணவர் 1 பெறுவார் என்பது எங்கள் எதிர்பார்ப்பு.
இந்த கட்டத்தில் நீங்கள் புத்தகத்தைப் படித்த ஆனால் விரிவுரைகளில் கலந்து கொள்ளாத மாணவர் 3 b *: துணை: `2` + என்ற தரத்தைப் பெறுவார் என்று பின்னடைவு மாதிரி கணித்துள்ளது என்பதை அறிய நீங்கள் விரும்ப மாட்டீர்கள் *பி: துணை: 0. இன்னொரு பின்னடைவு சூத்திரத்துடன் நான் உங்களைத் தாங்க மாட்டேன். அதற்கு பதிலாக, நான் என்ன செய்வேன் என்பது *எதிர்பார்க்கப்படும் தரங்களின் பின்வரும் அட்டவணையை உங்களுக்குக் காண்பிப்பதாகும்:
பாடப்புத்தகத்தைப் படிக்கவா? |
|||
|---|---|---|---|
இல்லை |
ஆம் |
||
** கலந்து கொண்டதா? ** |
** இல்லை ** |
b0 |
b0 + b2 |
** ஆம் ** |
b0 + b1 |
b0 + b1 + b2 |
|
As you can see, the intercept term b0 acts like a kind of “baseline”
grade that you would expect from those students who don’t take the time to
attend class or read the textbook. Similarly, b1 represents the
boost that you’re expected to get if you come to class, and b2
represents the boost that comes from reading the textbook. In fact, if this
were an ANOVA you might very well want to characterise b1 as the
main effect of attendance, and b2 as the main effect of reading!
In fact, for a simple 2 × 2 ANOVA that’s exactly how it plays out.
சரி, இப்போது ANOVA மற்றும் பின்னடைவு ஏன் ஒரே மாதிரியானவை என்பதை இப்போது நாம் காணத் தொடங்கியுள்ளோம், இது உண்மையில் உண்மை என்று நம்மை நம்பவைக்க | RTFM | _ தரவு தொகுப்பு மற்றும் சாமோவி பின்னடைவு பகுப்பாய்வு ஆகியவற்றைப் பயன்படுத்தி எங்கள் பின்னடைவை உண்மையில் இயக்குவோம். வழக்கமான வழியில் பின்னடைவை இயக்குவது காட்டப்பட்டுள்ள முடிவுகளைத் தருகிறது: NUMREF: Fig-factoriananova7.

Fig. 161 Regression analysis for the rtfm data set in jamovi: Model with two
factors attend and reading but without the interaction term for
these two factors
இங்கே கவனிக்க வேண்டிய சில சுவையான விசயங்கள் உள்ளன. முதலாவதாக, இடைமறிப்பு காலமானது 43.5 என்பதைக் கவனியுங்கள், இது உரையைப் படிக்காத அல்லது வகுப்பில் கலந்து கொள்ளாத அந்த இரண்டு மாணவர்களுக்கும் 42.5 இன் “குழு” சராசரிக்கு அருகில் உள்ளது. இரண்டாவதாக, *B *: 1 = 18.0 இன் பின்னடைவு குணகம் எங்களிடம் இருப்பதைக் கவனியுங்கள்` கலந்து கொள்ளுங்கள்`, வகுப்பில் கலந்து கொண்ட அந்த மாணவர்கள் செய்யாதவர்களை விட 18 % அதிக மதிப்பெண் பெற்றனர் என்று பரிந்துரைக்கிறது. எனவே எங்கள் எதிர்பார்ப்பு என்னவென்றால், வகுப்பிற்கு திரும்பிய ஆனால் பாடப்புத்தகத்தைப் படிக்காத மாணவர்கள் *B *: துணை: 0 + *B *: துணை:` 1`, இது சமம் முதல் 43.5 + 18.0 = 61.5. பாடப்புத்தகத்தைப் படிக்கும் மாணவர்களைப் பார்க்கும்போது இதேதான் நடக்கும் என்பதை நீங்களே சரிபார்க்கலாம்.
உண்மையில், எங்கள் ANOVA மற்றும் எங்கள் பின்னடைவின் சமநிலையை நிறுவுவதில் நாம் இன்னும் கொஞ்சம் தள்ள முடியும். பின்னடைவு வெளியீட்டில் `` கலந்துகொள்ளும்` மாறுபாடு மற்றும் வாசிப்பு` மாறியுடன் தொடர்புடைய *p *-மதிப்புகளைப் பாருங்கள். ANOVA ஐ இயக்கும் போது நாம் முன்பு சந்தித்தவற்றுடன் அவை ஒத்தவை. இது கொஞ்சம் ஆச்சரியமாகத் தோன்றலாம், ஏனெனில் எங்கள் பின்னடைவு மாதிரியை இயக்கும் போது பயன்படுத்தப்படும் சோதனை ஒரு *t *-statistic ஐக் கணக்கிடுகிறது மற்றும் ANOVA ஒரு *f *-statistict ஐக் கணக்கிடுகிறது. இருப்பினும், அத்தியாயம்: டாக்: ../ ch07/ch07_probability க்கு திரும்பிச் செல்லும் வழியை நீங்கள் நினைவில் வைத்திருந்தால், *t *-distripution மற்றும் *f *-distripution க்கு இடையில் ஒரு உறவு இருப்பதாக நான் குறிப்பிட்டேன். *K *டிகிரி சுதந்திரத்துடன் ஒரு *t *-விநியோகத்தின் படி விநியோகிக்கப்படும் சில அளவு உங்களிடம் இருந்தால், நீங்கள் அதை சதுரப்படுத்துகிறீர்கள், இந்த புதிய ச்கொயர் அளவு ஒரு *f *-விநியோகத்தை பின்பற்றுகிறது, அதன் விடுதலை 1 மற்றும் *k * . எங்கள் பின்னடைவு மாதிரியில் *t *-புள்ளிவிவரங்கள் தொடர்பாக இதைச் சரிபார்க்கலாம். `` கலந்துகொள்ளும்` `மாறுபாட்டிற்கு 4.65 இன் *t *-மதிப்பு கிடைக்கும். இந்த எண்ணை நாம் சதுரப்படுத்தினால், 21.6 உடன் முடிவடைகிறோம், இது எங்கள் ANOVA இல் தொடர்புடைய *f *-statistict உடன் பொருந்துகிறது.
இறுதியாக, நீங்கள் தெரிந்து கொள்ள வேண்டிய கடைசி சேதி. ANOVA மற்றும் பின்னடைவு இரண்டும் நேரியல் மாதிரிகளின் எடுத்துக்காட்டுகள் என்ற உண்மையை சாமோவி புரிந்து கொண்டதால், `` நேரியல் பின்னடைவு`` - `` மாதிரி குணகங்கள்` - `` ஆம்னிபச் சோதனை`` .

Fig. 162 Results table showing the Omnibus ANOVA Test from the jamovi regression
analysis using the rtfm dataset
அல்லாத பைனரி காரணிகளை முரண்பாடுகளாக எவ்வாறு குறியாக்கம் செய்வது
இந்த கட்டத்தில், 2 × 2 ANOVA ஐ ஒரு நேரியல் மாதிரியாக எவ்வாறு பார்க்க முடியும் என்பதை நான் உங்களுக்குக் காட்டியுள்ளேன். இது 2 × 2 × 2 ANOVA அல்லது 2 × 2 × 2 × 2 ANOVA க்கு எவ்வாறு பொதுமைப்படுத்துகிறது என்பதைப் பார்ப்பது மிகவும் எளிதானது. உண்மையில் இதே சேதி. உங்கள் ஒவ்வொரு காரணிகளுக்கும் புதிய பைனரி மாறியைச் சேர்க்கிறீர்கள். இரண்டு நிலைகளுக்கு மேல் உள்ள காரணிகளைக் கருத்தில் கொள்ளும்போது அது தந்திரமான இடத்தைப் பெறத் தொடங்குகிறது. உதாரணமாக, இந்த அத்தியாயத்தில் நாங்கள் முன்னர் ஓடிய 3 × 2 ANOVA ஐ | மருத்துவமனை | _ தரவு தொகுப்பைப் பயன்படுத்தி கவனியுங்கள். மூன்று-நிலை `` மருந்து` காரணி | பெயரளவு | பின்னடைவுக்கு பொருத்தமான எண் வடிவத்தில்?
இந்த கேள்விக்கான பதில் உண்மையில் மிகவும் எளிது. நாம் செய்ய வேண்டியது என்னவென்றால், மூன்று-நிலை காரணி * இரண்டு * பைனரி மாறிகள் என மறுவடிவமைக்க முடியும் என்பதை உணர வேண்டும். உதாரணமாக, நான் `` மருந்து அன்சிஃப்ரீ`` என்ற புதிய பைனரி மாறியை உருவாக்க வேண்டும் என்று வைத்துக்கொள்வோம். `` மருந்து`` மாறுபடும் `` கவலை`` க்கு சமமாக இருக்கும்போதெல்லாம் நாங்கள் `` Progmancanxifree = 1`` ஐ அமைத்துக்கொள்கிறோம். இல்லையெனில், நாங்கள் `` Progmancanxifree = 0`` ஐ அமைத்தோம். இந்த மாறி ** மாறுபாடு ** ஐ அமைக்கிறது, இந்த விசயத்தில் `` கவலை'` மற்றும் பிற இரண்டு மருந்துகளுக்கும் இடையில். நிச்சயமாக, எங்கள் `` மருந்து` மாறியில் உள்ள அனைத்து தகவல்களையும் முழுமையாகப் பிடிக்க மருந்து அன்சிஃப்ரீ` மாறுபாடு போதுமானதாக இல்லை. எங்களுக்கு இரண்டாவது மாறுபாடு தேவை, இது `` சாய்செபம்`` மற்றும் `` மருந்துப்போலி`` ஆகியவற்றை வேறுபடுத்துவதற்கு நம்மை அனுமதிக்கிறது. இதைச் செய்ய, `` மருந்து சாய்செபம்` என்று அழைக்கப்படும் இரண்டாவது பைனரி மாறுபாட்டை நாம் உருவாக்கலாம், இது `` மருந்து`` `` சாய்செபம்`` மற்றும் இல்லாவிட்டால் 1 க்கு சமம். ஒன்றாக எடுத்துக்கொண்டால், இந்த இரண்டு முரண்பாடுகளும் `` மருந்து`` இன் மூன்று நிலைகளுக்கும் இடையில் பாகுபாடு காட்ட அனுமதிக்கிறது. கீழே உள்ள அட்டவணை இதை விளக்குகிறது:
`` மருந்து`` |
`` Progmancanxifree`` |
`` மருந்து சாய்செபம்`` |
`` மருந்துப்போலி`` |
0 |
0 |
`` incifree`` |
1 |
0 |
`` சாய்செபம்`` |
0 |
1 |
ஒரு நோயாளிக்கு நிர்வகிக்கப்படும் `` மருந்து`` ஒரு `` மருந்துப்போலி`` என்றால், இரண்டு மாறுபட்ட மாறிகள் இரண்டும் சமமாக இருக்கும். 1 க்கு சமமாக இருக்கும், மற்றும் `` மருந்து சாய்செபம்`` 0 ஆக இருக்கும். `` சாய்செபம்`` க்கு தலைகீழ் உண்மை: `` மருந்து சாய்செபம்`` 1 மற்றும் `` மருந்து அன்சிஃப்ரீ`` 0.
புதிய மாறியை உருவாக்க சமோவி `` கம்ப்யூட்`` கட்டளையைப் பயன்படுத்தி மாறுபட்ட மாறிகளை உருவாக்குவது மிகவும் கடினம் அல்ல. எடுத்துக்காட்டாக, `` Progmancanxifree`` மாறியை உருவாக்க, இந்த தர்க்கரீதியான வெளிப்பாட்டை ஃபார்முலா பெட்டியில் எழுதுங்கள்: `` என்றால் (மருந்து == 'கவலை', 1, 0) . இதேபோல், புதிய மாறியை உருவாக்க `` மருந்து சாய்செபம் இந்த தர்க்கரீதியான வெளிப்பாட்டைப் பயன்படுத்தவும்: `` என்றால் (மருந்து == 'சாய்செபம்', 1, 0) . அதேபோல் `` therapy `therapy` therapy `சிகிச்சை CBT:` என்றால் (சிகிச்சை == 'சிபிடி', 1, 0) `. இந்த புதிய மாறிகள் மற்றும் அதனுடன் தொடர்புடைய தர்க்கரீதியான வெளிப்பாடுகளை நீங்கள் காணலாம் | கிளினிக்கல் ட்ரியல் 2 | _ தரவு தொகுப்பில்.
இரண்டு பைனரி மாறிகள் அடிப்படையில் இப்போது எங்கள் மூன்று-நிலை காரணியை நாங்கள் மறுசீரமைத்துள்ளோம், மேலும் ANOVA மற்றும் பின்னடைவு பைனரி மாறிகளுக்கு ஒரே மாதிரியாக செயல்படுவதை நாங்கள் ஏற்கனவே கண்டோம். இருப்பினும், இந்த வழக்கில் சில கூடுதல் சிக்கல்கள் எழுகின்றன, அவை அடுத்த பகுதியில் விவாதிப்போம்.
பைனரி அல்லாத காரணிகளுக்கான ANOVA க்கும் பின்னடைவுக்கும் இடையிலான சமநிலை
இப்போது ஒரே தரவு தொகுப்பின் இரண்டு வெவ்வேறு பதிப்புகள் உள்ளன. எங்கள் அசல் தரவு, | `` மருந்து`` மாறுபடும் | கிளினிக்கல் ட்ரீல் | மீண்டும், நாம் நிரூபிக்க விரும்பும் சேதி என்னவென்றால், எங்கள் அசல் 3 × 2 காரணி ANOVA மாறுபட்ட மாறிகள் பயன்படுத்தப்படும் பின்னடைவு மாதிரிக்கு சமம். முடிவுகளுடன், ANOVA ஐ மீண்டும் இயக்குவதன் மூலம் ஆரம்பிக்கலாம்: NumRef: Fig-factoralananova9.

Fig. 163 jamovi ANOVA results for the clinicaltrial dataset: Unsaturated model
with the two main effects for drug and therapy but without an
interaction component for these two factors
வெளிப்படையாக, இங்கே எந்த ஆச்சரியமும் இல்லை. நாங்கள் முன்பு ஓடிய அதே ANOVA இதுதான். அடுத்து, `` Progmancanxifree``, `` மருந்து சாய்செபம்`` மற்றும் `` தெரபி கிளிபிடி`` ஆகியவற்றைப் பயன்படுத்தி பின்னடைவை இயக்குவோம். முடிவுகள் இதில் காட்டப்பட்டுள்ளன: NumRef: Fig-factoralanova10.

Fig. 164 jamovi regression results for the clinicaltrial data set: Model with the
generated contrast variables druganxifree and drugjoyzepam
அ்ம். கடைசியாக எங்களுக்கு கிடைத்த அதே வெளியீடு இதுவல்ல. ஆச்சரியப்படுவதற்கில்லை, பின்னடைவு வெளியீடு மூன்று முன்னறிவிப்பாளர்களில் ஒவ்வொருவருக்கும் தனித்தனியாக முடிவுகளை அச்சிடுகிறது, ஒவ்வொரு முறையும் நாங்கள் ஒரு பின்னடைவு பகுப்பாய்வை நடத்தியதைப் போலவே. ஒருபுறம் `` தெரபி கிளிபிடி`` மாறிக்கான *பி *-மதிப்பு `` சிகிச்சை` காரணி | பெயரளவு | எங்கள் அசல் ANOVA இல், ஆகவே பின்னடைவு மாதிரி ANOVA செய்ததைப் போலவே செய்கிறது என்பதை நாம் உறுதியளிக்க முடியும். மறுபுறம், இந்த பின்னடைவு மாதிரியானது `` மருந்து அன்சிஃப்ரீ` மாறுபாட்டையும், மருந்து சாய்செபாம்` மாறுபாடு *தனித்தனியாக *, அவை முற்றிலும் தொடர்பில்லாத இரண்டு மாறிகள் போலவும் சோதிக்கின்றன. நிச்சயமாக ஆச்சரியப்படுவதற்கில்லை, ஏனென்றால் `` மருந்து சாய்செபம்`` மற்றும் `` ட்ரிக்அன்எக்சிஃப்ரீ`` உண்மையில் எங்கள் மூன்று-நிலை `` மருந்து` காரணியை குறியாக்கப் பயன்படுத்திய இரண்டு வெவ்வேறு முரண்பாடுகள் என்பதை அறிய மோசமான பின்னடைவு பகுப்பாய்விற்கு எந்த வழியும் இல்லை. அது தெரிந்தவரை, `` மருந்து சாய்செபம்`` மற்றும் `` ட்ரெக்ஆன்எக்சிஃப்ரீ`` ஆகியவை ஒருவருக்கொருவர் தொடர்புடையவை அல்ல `` மருந்து சாய்செபம்`` மற்றும் `` தெரபி கிபிடி``. இருப்பினும், உங்களுக்கும் எனக்கும் நன்றாகத் தெரியும். இந்த கட்டத்தில் இந்த இரண்டு முரண்பாடுகளும் தனித்தனியாக குறிப்பிடத்தக்கவை என்பதை தீர்மானிக்க நாங்கள் ஆர்வம் காட்டவில்லை. `` மருந்து`` இன் “ஒட்டுமொத்த” விளைவு இருக்கிறதா என்பதை நாங்கள் அறிய விரும்புகிறோம். அதாவது, சமோவி செய்ய விரும்புவது என்னவென்றால், ஒருவித “மாதிரி ஒப்பீடு” சோதனையை இயக்க வேண்டும், அதில் ஒன்று “போதைப்பொருள் தொடர்பான” முரண்பாடுகள் சோதனையின் நோக்கத்திற்காக ஒன்றாக இணைக்கப்பட்டுள்ளன. தெரிந்திருக்கிறதா? நாம் செய்ய வேண்டியது எங்கள் சுழிய மாதிரியைக் குறிப்பிடுவதுதான், இந்த விசயத்தில் `` தெரபி கிபிடி`` முன்னறிவிப்பாளரை உள்ளடக்கியிருக்கும், மேலும் போதைப்பொருள் தொடர்பான இரண்டு மாறிகள் இரண்டையும் தவிர்த்து விடுங்கள்: எண்: அத்தி-கார்ட்ரியோரியனோவா 11 .
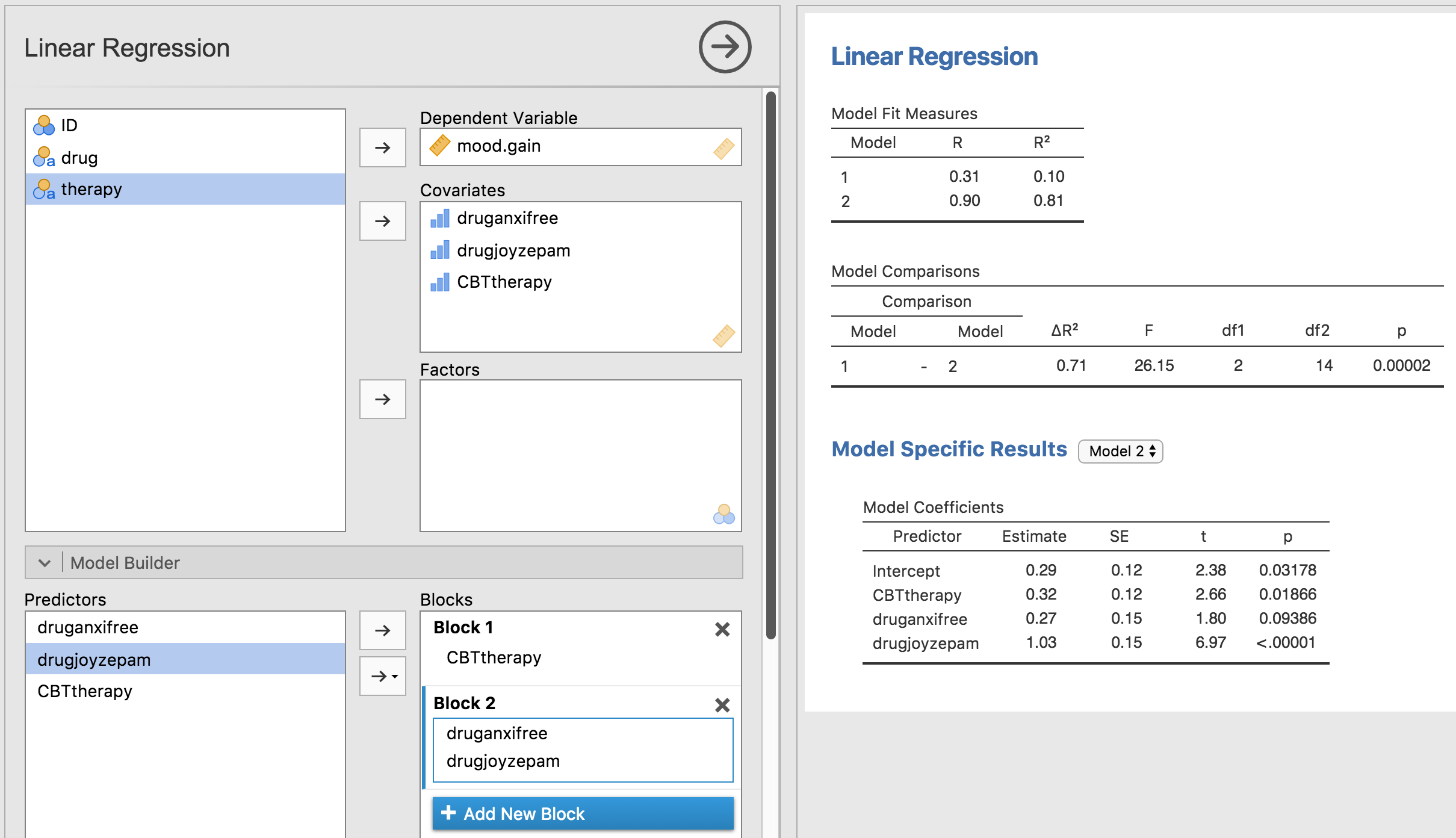
Fig. 165 சாமோவி பின்னடைவில் மாதிரி ஒப்பீடு: சுழிய மாதிரி (மாதிரி 1) வெர்சச் மாதிரி உருவாக்கப்பட்ட மாறுபட்ட மாறிகள் (மாதிரி 2)
ஆ, அது சிறந்தது. எங்கள் *f *-statistic 26.15, சுதந்திரத்தின் அளவுகள் 2 மற்றும் 14, மற்றும் *p *-மதிப்பு 0.00002 ஆகும். எங்கள் அசல் ANOVA இல் `` மருந்து`` இன் முக்கிய விளைவுக்காக எண்கள் நாம் பெற்றவற்றுடன் ஒத்தவை. ANOVA மற்றும் பின்னடைவு ஆகியவை ஒரே மாதிரியானவை என்பதை மீண்டும் காண்கிறோம். அவை இரண்டும் நேரியல் மாதிரிகள், மற்றும் ANOVA க்கான அடிப்படை புள்ளிவிவர இயந்திரங்கள் பின்னடைவில் பயன்படுத்தப்படும் இயந்திரங்களுக்கு ஒத்ததாகும். இந்த உண்மையின் முக்கியத்துவத்தை குறைத்து மதிப்பிடக்கூடாது. இந்த அத்தியாயத்தின் எஞ்சிய பகுதி முழுவதும் நாம் இந்த யோசனையை பெரிதும் நம்பியிருக்கிறோம்.
`` மருந்து அன்சிஃப்ரீ`` மற்றும் `` மருந்து சாய்செபம்`` ஆகியவற்றுக்கு சாமோவியில் புதிய மாறிகளைக் கணக்கிடுவதற்கான அனைத்து குறைபாடுகளையும் நாங்கள் கடந்து சென்றாலும், ANOVA மற்றும் பின்னடைவு ஆகியவை ஒரே மாதிரியானவை என்பதைக் காண்பிப்பதற்காக, சாமோவி நேரியல் பின்னடைவு பகுப்பாய்வில் உண்மையில் ஒரு உள்ளது இந்த முரண்பாடுகளைப் பெற நிஃப்டி குறுக்குவழி, காண்க: எண்ரெஃப்: அத்தி-ரெசாக்டர்கள். சாமோவி இங்கே என்ன செய்கிறார் என்பது முன்னறிவிப்பு மாறிகளுக்குள் நுழைய உங்களை அனுமதிக்கிறது, அதற்காக காத்திருங்கள்… காரணிகள்! அறிவுள்ள, ஈ. `` குறிப்பு நிலைகள்`` விருப்பம் வழியாக எந்த குழுவைக் குறிப்பு மட்டமாகப் பயன்படுத்த வேண்டும் என்பதையும் நீங்கள் குறிப்பிடலாம். இதை முறையே `` மருந்துப்போலி`` மற்றும் `.
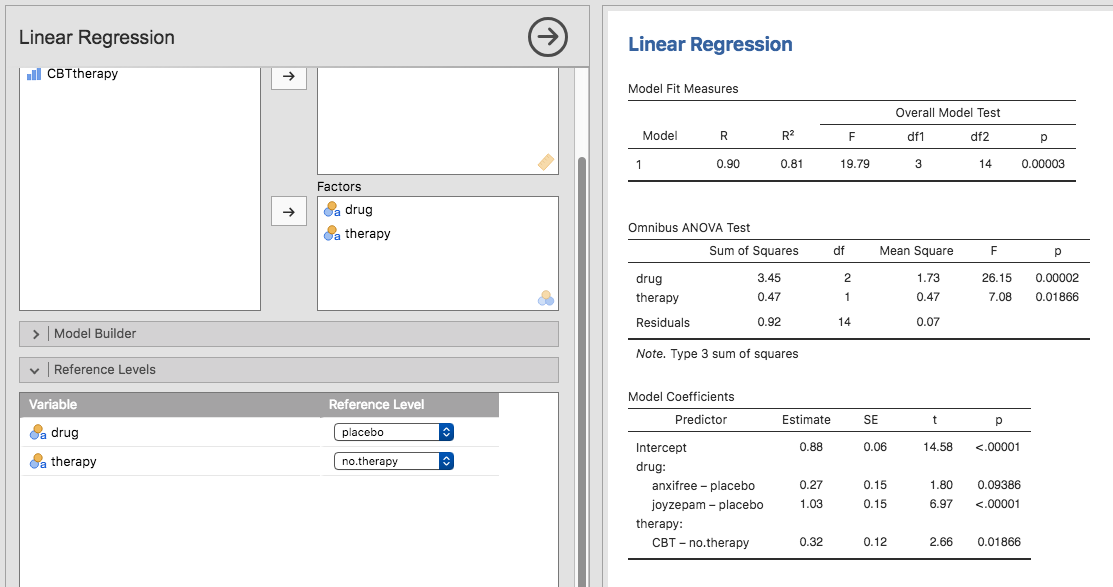
Fig. 166 ஓம்னிபச் ANOVA சோதனை முடிவுகள் உட்பட சாமோவியில் காரணிகள் மற்றும் முரண்பாடுகளுடன் பின்னடைவு பகுப்பாய்வு
`` மாதிரி குணகங்கள்` `` ஆம்னிபச் டெச்ட்` விருப்பத்தின் கீழ்` அனோவா டெச்ட்` தேர்வுப்பெட்டியையும் நீங்கள் சொடுக்கு செய்தால், *எஃப் *-ச்டாட்டிச்டிக் 26.15 ஐக் காண்கிறோம், சுதந்திரத்தின் அளவுகள் 2 மற்றும் 14 ஆகும் , மற்றும் *பி *-மதிப்பு 0.00002 (பார்க்க: எண்ரெஃப்: அத்தி-ரெசாக்டர்கள்). எங்கள் அசல் ANOVA இல் `` மருந்து`` இன் முக்கிய விளைவுக்காக எண்கள் நாம் பெற்றவற்றுடன் ஒத்தவை. மீண்டும், ANOVA மற்றும் பின்னடைவு ஆகியவை ஒரே மாதிரியானவை என்பதைக் காண்கிறோம். அவை இரண்டும் நேரியல் மாதிரிகள், மற்றும் ANOVA க்கான அடிப்படை புள்ளிவிவர இயந்திரங்கள் பின்னடைவில் பயன்படுத்தப்படும் இயந்திரங்களுக்கு ஒத்ததாகும்.
அளவுரு எண்ணாக சுதந்திரத்தின் அளவுகள்!
நீண்ட காலமாக, நான் மகிழ்ச்சியாக இருக்கும் சுதந்திரத்தின் டிகிரி வரையறையை இறுதியாக வழங்க முடியும். ஒரு மாதிரியில் மதிப்பிடப்பட வேண்டிய அளவுருக்களின் எண்ணிக்கையின் அடிப்படையில் சுதந்திரத்தின் அளவுகள் வரையறுக்கப்படுகின்றன. ஒரு பின்னடைவு மாதிரி அல்லது ANOVA க்கு, அளவுருக்களின் எண்ணிக்கை பின்னடைவு உட்பட பின்னடைவு குணகங்களின் எண்ணிக்கையுடன் (அதாவது *B *-மதிப்புகள்) ஒத்திருக்கிறது. எந்தவொரு *f *-Test என்பது எப்போதும் இரண்டு மாதிரிகள் மற்றும் முதல் *df *ஆகியவற்றுக்கு இடையேயான ஒப்பீடு என்பதை நினைவில் வைத்துக் கொள்வது அளவுருக்களின் எண்ணிக்கையில் உள்ள வித்தியாசமாகும். எடுத்துக்காட்டாக, மேலே உள்ள மாதிரி ஒப்பீட்டில், சுழிய மாதிரி (`` mood.gain ~ reacycbt``) இரண்டு அளவுருக்களைக் கொண்டுள்ளது: `` சிகிச்சை CBT` மாறிக்கு ஒரு பின்னடைவு குணகம் உள்ளது, மேலும் இடைமறிப்புக்கு இரண்டாவது ஒன்று. மாற்று மாதிரி (`` மனநிலை. எனவே இந்த இரண்டு மாடல்களுக்கிடையேயான *வித்தியாசத்துடன் *தொடர்புடைய சுதந்திரத்தின் அளவுகள் *df *: துணை: 1 = 4 - 2 = 2.
What about the case when there doesn’t seem to be a null model? For
instance, you might be thinking of the F-test that shows up when
you select F Test under the Linear Regression - Model
Fit options. I originally described that as a test of the regression
model as a whole. However, that is still a comparison between two
models. The null model is the trivial model that only includes 1
regression coefficient, for the intercept term. The alternative model
contains K + 1 regression coefficients, one for each of the K
predictor variables and one more for the intercept. So the
df-value that you see in this F-test is equal to
df1 = K + 1 - 1 = K.
F *-test இல் தோன்றும் இரண்டாவது *df *-மதிப்பு பற்றி என்ன? இது எப்போதும் எச்சங்களுடன் தொடர்புடைய சுதந்திரத்தின் அளவைக் குறிக்கிறது. அளவுருக்களின் அடிப்படையில் இதைப் பற்றி சிந்திக்க முடியும், ஆனால் சற்று எதிர்-உள்ளுணர்வு வழியில். இதை இப்படி நினைத்துப் பாருங்கள். ஒட்டுமொத்தமாக ஆய்வில் உள்ள மொத்த அவதானிப்புகளின் எண்ணிக்கை *n *என்று வைத்துக்கொள்வோம். இந்த * n * மதிப்புகள் ஒவ்வொன்றையும் நீங்கள் * சரியாக * விவரிக்க விரும்பினால், நீங்கள் அவ்வாறு செய்ய வேண்டும், நன்றாக… * n * எண்கள். நீங்கள் ஒரு பின்னடைவு மாதிரியை உருவாக்கும்போது, நீங்கள் உண்மையில் என்ன செய்கிறீர்கள் என்பது சில எண்கள் தரவை சரியாக விவரிக்க வேண்டும் என்பதைக் குறிப்பிடுகிறது. உங்கள் மாதிரியில் * K * முன்னறிவிப்பாளர்கள் மற்றும் இடைமறிப்பு இருந்தால், நீங்கள் * K * + 1 எண்களைக் குறிப்பிட்டுள்ளீர்கள். எனவே, இது எப்படி செய்யப்படும் என்பதை சரியாகக் கண்டுபிடிக்க கவலைப்படாமல், * K * + 1 அளவுரு பின்னடைவு மாதிரியை மூலத்தின் சரியான மறு விளக்கமாக மாற்ற எத்தனை * இன்னும் * எண்கள் தேவைப்படும் என்று நீங்கள் நினைக்கிறீர்கள் தரவு? (*K + 1) + (n -k - 1) =*n*, எனவே பதில்*n* -k - 1 ஆக இருக்க வேண்டும் என்று நீங்கள் நினைத்தால் ! அது சரி. கொள்கையளவில் ஒவ்வொரு தரவு புள்ளிக்கும் ஒரு அளவுருவை உள்ளடக்கிய ஒரு அபத்தமான சிக்கலான பின்னடைவு மாதிரியை நீங்கள் கற்பனை செய்யலாம், மேலும் இது தரவின் சரியான விளக்கத்தை நிச்சயமாக வழங்கும். இந்த மாதிரியில் மொத்தம் *n *அளவுருக்கள் இருக்கும், ஆனால் இந்த முழு மாதிரியை விவரிக்க தேவையான அளவுருக்களின் எண்ணிக்கையிலும் (அதாவது *n *) மற்றும் நீங்கள் இருக்கும் எளிமையான பின்னடைவு மாதிரியால் பயன்படுத்தப்படும் அளவுருக்களின் எண்ணிக்கை ஆகியவற்றுக்கும் இடையிலான வேறுபாட்டில் நாங்கள் ஆர்வமாக உள்ளோம் ' உண்மையில் (அதாவது, *k * + 1) இல் ஆர்வம் காட்டுங்கள், எனவே *f *-test இல் இரண்டாவது டிகிரி விடுதலை *df *: துணை: 2 = *n * - *k * - 1, * k * என்பது முன்னறிவிப்பாளர்களின் எண்ணிக்கை (பின்னடைவு மாதிரியில்) அல்லது முரண்பாடுகளின் எண்ணிக்கை (ANOVA இல்). நான் மேலே கொடுத்த எடுத்துக்காட்டில், தரவு தொகுப்பில் *n *= 18 அவதானிப்புகள் மற்றும் *k * + 1 = 4 ANOVA மாதிரியுடன் தொடர்புடைய பின்னடைவு குணகங்கள் உள்ளன, எனவே எச்சங்களுக்கான சுதந்திரத்தின் அளவு *df *: துணை : 2 = 18 - 4 = 14.