Section author: Danielle J. Navarro and David R. Foxcroft
காரணி ANOVA 1: சீரான வடிவமைப்புகள், இடைவினைகள் இல்லை
அத்தியாயத்தில் மாறுபாட்டின் பகுப்பாய்வைப் பற்றி விவாதித்தபோது: DOC: ../ ch13/ch13_anova, நாங்கள் மிகவும் எளிமையான சோதனை வடிவமைப்பை ஏற்றுக்கொண்டோம். ஒவ்வொரு நபரும் பல குழுக்களில் ஒன்றில் உள்ளனர், மேலும் இந்த குழுக்கள் சில விளைவு மாறியில் வெவ்வேறு சராசரி மதிப்பெண்களைக் கொண்டுள்ளனவா என்பதை அறிய விரும்புகிறோம். இந்த பிரிவில், ** காரணியாலான வடிவமைப்புகள் ** எனப்படும் பரந்த அளவிலான சோதனை வடிவமைப்புகளைப் பற்றி விவாதிப்பேன், இதில் ஒன்றுக்கு மேற்பட்ட குழுக்கள் மாறுகின்றன | பெயரளவு |. இந்த வகையான வடிவமைப்பு மேலே எவ்வாறு எழக்கூடும் என்பதற்கு நான் ஒரு உதாரணத்தை அளித்தேன். அத்தியாயத்தில் மற்றொரு எடுத்துக்காட்டு தோன்றும்: DOC: ../ ch13/ch13_anova இதில் ஒவ்வொரு நபரும் அனுபவித்த` மனநிலையில் மனநிலையில் வெவ்வேறு மருந்துகளின் விளைவைப் பார்த்துக் கொண்டிருந்தோம் | தொடர்ச்சியான |. அந்த அத்தியாயத்தில் நாங்கள் மருந்தின் குறிப்பிடத்தக்க விளைவைக் கண்டோம், ஆனால் அத்தியாயத்தின் முடிவில் சிகிச்சையின் விளைவு இருக்கிறதா என்று ஒரு பகுப்பாய்வையும் நடத்தினோம். நாங்கள் ஒன்றைக் கண்டுபிடிக்கவில்லை, ஆனால் அதே முடிவைக் கணிக்க முயற்சிக்கும் இரண்டு * தனித்தனி * பகுப்பாய்வுகளை இயக்க முயற்சிப்பதைப் பற்றி கொஞ்சம் கவலைப்படுகிறார். மனநிலை ஆதாயத்தில் சிகிச்சையின் விளைவு * உண்மையில் * இருக்கலாம், ஆனால் போதைப்பொருளின் விளைவால் அது “மறைக்கப்பட்டுள்ளது” என்பதால் அதை எங்களால் கண்டுபிடிக்க முடியவில்லை? வேறு வார்த்தைகளில் கூறுவதானால், * `` மருந்து` மற்றும் `` சிகிச்சை` இரண்டையும் முன்னறிவிப்பாளர்களாக உள்ளடக்கிய * ஒற்றை * பகுப்பாய்வை இயக்க விரும்புகிறோம். இந்த பகுப்பாய்விற்கு ஒவ்வொரு நபரும் அவர்களுக்கு வழங்கப்பட்ட மருந்துகளால் குறுக்கு வகைப்படுத்தப்படுகிறார்கள் (3 நிலைகளைக் கொண்ட ஒரு காரணி) மற்றும் அவர்கள் எந்த சிகிச்சையைப் பெற்றார்கள் (2 நிலைகளைக் கொண்ட ஒரு காரணி). இதை நாங்கள் 3 × 2 காரணியாலான வடிவமைப்பு என்று குறிப்பிடுகிறோம்.
`` சிகிச்சை` மூலம் `` மருந்து` `` சிகிச்சை மூலம்,` அதிர்வெண்கள் →` `` தற்செயல் அட்டவணைகள்`` சாமோவியில் பகுப்பாய்வைப் பயன்படுத்தி நாம் குறுக்கு-தட்டச்சு செய்தால் (பார்க்க: டாக்: .. காட்டப்பட்டுள்ள அட்டவணையைப் பெறுங்கள்: NumRef: `Fig-factoralanova1.
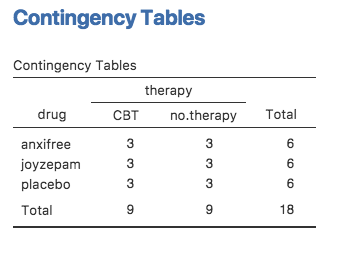
Fig. 144 `` சிகிச்சை` ஆல் `` மருந்து` க்கான சாமோவி தற்செயல் அட்டவணை
நீங்கள் பார்க்கிறபடி, இரண்டு காரணிகளின் சாத்தியமான அனைத்து சேர்க்கைகளுக்கும் ஒத்த பங்கேற்பாளர்கள் எங்களிடம் இருப்பது மட்டுமல்லாமல், எங்கள் வடிவமைப்பு ** முழுவதுமாக கடக்கப்பட்டது ** என்பதைக் குறிக்கிறது, ஒவ்வொரு குழுவிலும் சம எண்ணிக்கையிலான மக்கள் இருக்கிறார்கள் என்று மாறிவிடும். வேறு வார்த்தைகளில் கூறுவதானால், எங்களிடம் ** சீரான ** வடிவமைப்பு உள்ளது. இந்த பிரிவில் நான் சீரான வடிவமைப்புகளிலிருந்து தரவை எவ்வாறு பகுப்பாய்வு செய்வது என்பது பற்றி பேசுவேன், ஏனெனில் இது எளிமையான வழக்கு. சமநிலையற்ற வடிவமைப்புகளுக்கான கதை மிகவும் கடினமானது, எனவே நாங்கள் அதை ஒரு பக்கத்திற்கு இப்போதைக்கு வைப்போம்.
நாம் என்ன கருதுகோள்களை சோதிக்கிறோம்?
Like one-way ANOVA, தொடர்பெருக்கு ANOVA is a கருவி க்கு testing certain வகைகள் of hypotheses பற்றி population means. So a sensible place பெறுநர் தொடங்கு would be பெறுநர் be explicit பற்றி what our hypotheses actually are. However, before we can இரட்டை get பெறுநர் that point, it’s really useful பெறுநர் have some clean and simple notation பெறுநர் describe the population means. இரண்டு வெவ்வேறு காரணிகளின் அடிப்படையில் அவதானிப்புகள் குறுக்கு-வகைப்படுத்தப்பட்டவை என்ற உண்மையின் காரணமாக, ஒருவர் ஆர்வமாக இருக்கக்கூடிய வேறுபட்ட வழிமுறைகள் உள்ளன. இதைப் பார்க்க, வெவ்வேறு மாதிரிகளைப் பற்றி சிந்திப்பதன் மூலம் தொடங்குவோம் க்கு this kind of design. Firstly, there’s the obvious idea that we might be interested in this பட்டியல் of குழு means:
drug therapy mood.gain
placebo no.therapy 0.300000
anxifree no.therapy 0.400000
joyzepam no.therapy 1.466667
placebo CBT 0.600000
anxifree CBT 1.033333
joyzepam CBT 1.500000
இப்போது, இந்த வெளியீடு இரண்டு காரணிகளின் சாத்தியமான அனைத்து சேர்க்கைகளுக்கும் குழுவின் பட்டியலைக் காட்டுகிறது (எ.கா., மருந்துப்போலி பெற்றவர்கள் மற்றும் மருத்தீடு இல்லாதவர்கள், சிபிடி பெறும் போது மருந்துப்போலி பெற்றவர்கள்). இந்த எண்கள் அனைத்தையும், மற்றும் விளிம்பு மற்றும் பிரமாண்டமான வழிமுறைகளையும், ஒரே ஒரு அட்டவணையில் ஒழுங்கமைக்க இது உதவியாக இருக்கும்:
மருத்தீடு இல்லை |
சிபிடி |
மொத்தம் |
|
|---|---|---|---|
placebo |
0.30 |
0.60 |
0.45 |
anxifree |
0.40 |
1.03 |
0.72 |
joyzepam |
1.47 |
1.50 |
1.48 |
** மொத்தம் ** |
0.72 |
1.04 |
0.88 |
இப்போது, இந்த வெவ்வேறு வழிமுறைகள் ஒவ்வொன்றும் நிச்சயமாக ஒரு மாதிரி புள்ளிவிவரம். இது எங்கள் ஆய்வின் போது நாங்கள் செய்த குறிப்பிட்ட அவதானிப்புகளுடன் தொடர்புடைய ஒரு அளவு. நாம் அனுமானங்களைச் செய்ய விரும்புவது தொடர்புடைய மக்கள்தொகை அளவுருக்கள். அதாவது, சில பரந்த மக்கள்தொகைக்குள் அவை இருப்பதால் உண்மையான வழிமுறைகள். அந்த மக்கள்தொகையும் இதேபோன்ற அட்டவணையில் ஒழுங்கமைக்கப்படலாம், ஆனால் அவ்வாறு செய்ய எங்களுக்கு கொஞ்சம் கணிதக் குறியீடு தேவை. வழக்கம் போல், மக்கள்தொகை சராசரியைக் குறிக்க indem குறியீட்டைப் பயன்படுத்துவேன். இருப்பினும், பல்வேறு வழிமுறைகள் இருப்பதால், அவற்றுக்கு இடையில் வேறுபடுவதற்கு நான் சந்தாக்களைப் பயன்படுத்த வேண்டும்.
குறியீடு எவ்வாறு செயல்படுகிறது என்பது இங்கே. எங்கள் அட்டவணை இரண்டு காரணிகளின் அடிப்படையில் வரையறுக்கப்படுகிறது. ஒவ்வொரு வரிசையும் வெவ்வேறு அளவிலான காரணி A உடன் ஒத்துப்போகிறது (இந்த விசயத்தில் `` மருந்து``), மேலும் ஒவ்வொரு நெடுவரிசையும் வெவ்வேறு அளவிலான காரணி B உடன் ஒத்திருக்கிறது (இந்த விசயத்தில் `` சிகிச்சை``). நாம் * r * அட்டவணையில் உள்ள வரிசைகளின் எண்ணிக்கையைக் குறிக்க அனுமதித்தால், * C * நெடுவரிசைகளின் எண்ணிக்கையைக் குறிக்கிறது என்றால், இதை ஒரு R × C காரணியாலான ANOVA என குறிப்பிடலாம். இந்த வழக்கில் r = 3 மற்றும் c = 2. குறிப்பிட்ட வரிசைகள் மற்றும் நெடுவரிசைகளைக் குறிக்க சிறிய எழுத்துக்களைப் பயன்படுத்துவோம், எனவே µ : துணை: rc என்பது மக்கள்தொகையை குறிக்கிறது *r *வது காரணி மட்டத்துடன் தொடர்புடையது A (அதாவது வரிசை எண் *r *) மற்றும் *C *-th காரணி B (நெடுவரிசை எண் *C *). [#] _ எனவே மக்கள் தொகை இப்போது இதுபோன்று எழுதப்பட்டுள்ளது:
மருத்தீடு இல்லை |
சிபிடி |
மொத்தம் |
|
|---|---|---|---|
placebo |
µ11 |
µ11 |
|
anxifree |
µ21 |
µ11 |
|
joyzepam |
µ31 |
µ11 |
|
** மொத்தம் ** |
சரி, மீதமுள்ள உள்ளீடுகளைப் பற்றி என்ன? உதாரணமாக, சிபிடியில் இருந்ததா என்பதைப் பொருட்படுத்தாமல், இது போன்ற ஒரு பரிசோதனையில் சாய்செபமுக்கு வழங்கப்படக்கூடிய முழு (கற்பனையான) மக்கள்தொகையிலும் சராசரி மனநிலை ஆதாயத்தை நாம் எவ்வாறு விவரிக்க வேண்டும்? இதை வெளிப்படுத்த “புள்ளி” குறியீட்டைப் பயன்படுத்துகிறோம். சாய்செபம் விசயத்தில், அட்டவணையில் மூன்றாவது வரிசையுடன் தொடர்புடைய சராசரி பற்றி நாங்கள் பேசுகிறோம் என்பதைக் கவனியுங்கள். அதாவது, நாங்கள் இரண்டு செல் வழிமுறைகளில் சராசரியாக இருக்கிறோம் (அதாவது, µ : துணை: 31 மற்றும் µ : துணை:` 32`). இந்த சராசரியின் முடிவு ** விளிம்பு சராசரி ** என குறிப்பிடப்படுகிறது, மேலும் இது µ : துணை: 3. இந்த விசயத்தில் குறிக்கப்படும். CBT க்கான விளிம்பு சராசரி அட்டவணையில் இரண்டாவது நெடுவரிசையுடன் தொடர்புடைய மக்கள்தொகைக்கு ஒத்திருக்கிறது, எனவே அதை விவரிக்க µ : துணை: .2 என்ற குறியீட்டைப் பயன்படுத்துகிறோம். கிராண்ட் சராசரி குறிக்கப்படுகிறது µ : துணை: .. ஏனெனில் இது இரண்டையும் விட சராசரியாக (ஓரங்கட்டப்படுதல் [#] _) பெறப்பட்ட சராசரி. எனவே எங்கள் முழு மக்கள்தொகை அட்டவணையை இதுபோன்று எழுதலாம்:
மருத்தீடு இல்லை |
சிபிடி |
மொத்தம் |
|
|---|---|---|---|
placebo |
µ11 |
µ12 |
µ1. |
anxifree |
µ21 |
µ22 |
µ2. |
joyzepam |
µ31 |
µ32 |
µ3. |
** மொத்தம் ** |
µ.1 |
µ.2 |
µ.. |
இப்போது நம்மிடம் இந்த குறியீடு உள்ளது, சில கருதுகோள்களை வகுத்து வெளிப்படுத்துவது நேரடியானது. இரண்டு விசயங்களைக் கண்டுபிடிப்பதே குறிக்கோள் என்று வைத்துக்கொள்வோம். முதலாவதாக, மருந்தின் தேர்வு மனநிலையில் ஏதேனும் தாக்கத்தை ஏற்படுத்துமா? இரண்டாவதாக, சிபிடி மனநிலையில் ஏதேனும் தாக்கத்தை ஏற்படுத்துமா? இவை நிச்சயமாக நாம் உருவாக்கக்கூடிய ஒரே கருதுகோள்கள் அல்ல, மேலும் பிரிவில் வேறு வகையான கருதுகோளின் மிக முக்கியமான உதாரணத்தைக் காண்போம்: டிஓசி: CH14_ANOVA2_02, ஆனால் இவை சோதிக்க இரண்டு எளிய கருதுகோள்கள், மற்றும் நாங்கள் அங்கு தொடங்குவோம். முதல் சோதனையை கவனியுங்கள். மருந்து எந்த விளைவையும் ஏற்படுத்தவில்லை என்றால், வரிசை அனைத்தும் ஒரே மாதிரியாக இருக்கும் என்று நாங்கள் எதிர்பார்க்கிறோம், இல்லையா? எனவே இது எங்கள் சுழிய கருதுகோள். மறுபுறம், மருந்து முக்கியமானது என்றால், இந்த வரிசை வித்தியாசமாக இருக்கும் என்று நாம் எதிர்பார்க்க வேண்டும். முறையாக, விளிம்பு வழிமுறைகளின் *சமத்துவத்தின் அடிப்படையில் எங்கள் சுழிய மற்றும் மாற்று கருதுகோள்களை எழுதுகிறோம் *:
சுழிய கருதுகோள், h : துணை: 0: |
வரிசை வழிகள் ஒன்றே, அதாவது, µ : துணை: 1. = µ : துணை:` 2.` = µ : துணை: 3. |
மாற்று கருதுகோள், H : துணை: 1: |
குறைந்தது ஒரு வரிசை சராசரி வேறுபட்டது. |
இவை * சரியாக * இந்த தரவுகளில் ஒரு வழி ANOVA ஐ இயக்கும்போது நாங்கள் உருவாக்கிய அதே புள்ளிவிவர கருதுகோள்கள்: doc: முந்தைய அத்தியாயம் <../ ch13/ch13_anova>. பின்னர், மருந்துப்போலி குழுவிற்கான சராசரி மனநிலை ஆதாயத்தைக் குறிக்க µ : sub: p என்ற குறியீட்டைப் பயன்படுத்தினேன், : துணை:` a` மற்றும் µ : துணை: j குழுவுடன் தொடர்புடையது இரண்டு மருந்துகளுக்கு, மற்றும் சுழிய கருதுகோள் µ : துணை: p = µ : துணை:` a` = µ : துணை: j. எனவே நாங்கள் உண்மையில் அதே கருதுகோளைப் பற்றி பேசுகிறோம், பல குழுக்கள் இருப்பதால் மிகவும் சிக்கலான ANOVA க்கு மிகவும் கவனமான குறியீடு தேவைப்படுகிறது, எனவே இந்த கருதுகோளை இப்போது µ : 1. 1. 1. எனக் குறிப்பிடுகிறோம் = µ : துணை: 2. = µ : துணை:` 3.`. எவ்வாறாயினும், விரைவில் நாம் பார்ப்போம், கருதுகோள் ஒரே மாதிரியாக இருந்தாலும், அந்த கருதுகோளின் சோதனை நுட்பமாக வேறுபட்டது, ஏனெனில் இரண்டாவது குழு மாறியின் இருப்பை நாம் இப்போது ஒப்புக்கொள்கிறோம்.
மற்ற குழு மாறியைப் பற்றி பேசுகையில், எங்கள் இரண்டாவது கருதுகோள் சோதனை அதே வழியில் வடிவமைக்கப்பட்டுள்ளது என்பதைக் கண்டு நீங்கள் ஆச்சரியப்பட மாட்டீர்கள். எவ்வாறாயினும், மருந்துகளை விட உளவியல் சிகிச்சையைப் பற்றி நாம் பேசுவதால், எங்கள் சுழிய கருதுகோள் இப்போது நெடுவரிசையின் சமத்துவத்திற்கு ஒத்திருக்கிறது:
சுழிய கருதுகோள், h : துணை: 0: |
நெடுவரிசை வழிகள் ஒன்றே, அதாவது, µ : துணை: .1 = µ : துணை:` .2` |
மாற்று கருதுகோள், H : துணை: 1: |
நெடுவரிசை வழிமுறைகள் வேறுபட்டவை, அதாவது, µ : துணை: .1 ≠ µ : துணை:` .2` |
சமோவியில் பகுப்பாய்வை இயக்குகிறது
கடைசி பிரிவில் நான் விவரித்த சுழிய மற்றும் மாற்று கருதுகோள்கள் மிகவும் பரிச்சயமானதாகத் தோன்ற வேண்டும். அவை அடிப்படையில் எங்கள் எளிமையில் நாங்கள் சோதித்துக்கொண்டிருந்த கருதுகோள்களைப் போலவே இருக்கின்றன: டாக்: ஒரு வழி ANOVAS <../ CH13/CH13_ANOVA>. ஆகவே, காரணி ANOVA இல் பயன்படுத்தப்படும் கருதுகோள் *சோதனைகள் *அடிப்படையில் *f *-test இலிருந்து: doc: முந்தைய அத்தியாயம் <../ ch13/ch13_anova> போன்றதாக இருக்கும் என்று நீங்கள் எதிர்பார்க்கலாம். சதுரங்கள் (எச்.எச்), சராசரி சதுரங்கள் (எம்.எச்), டிகிரி விடுதலை (டி.எஃப்), இறுதியாக *பி *-மதிப்பாக மாற்றக்கூடிய ஒரு *எஃப் *-புள்ளிவிவரங்கள் பற்றிய குறிப்புகளைக் காணலாம் என்று நீங்கள் எதிர்பார்க்கிறீர்கள், இல்லையா? சரி, நீங்கள் முற்றிலும் மற்றும் முற்றிலும் சரியானவர். என் வழக்கமான அணுகுமுறையிலிருந்து நான் புறப்படப் போகிறேன். இந்த நூல் முழுவதும், ஒரு குறிப்பிட்ட பகுப்பாய்வை முதலில் ஆதரிக்கும் தர்க்கத்தை (மற்றும் கணிதத்தை ஒரு அளவிற்கு) விவரிக்கும் அணுகுமுறையை நான் பொதுவாக எடுத்துள்ளேன், பின்னர் சமோவியில் பகுப்பாய்வை அறிமுகப்படுத்துகிறேன். இந்த நேரத்தில் நான் இதை வேறு வழியில் செய்யப் போகிறேன், முதலில் அதை சமோவியில் எப்படி செய்வது என்பதைக் காண்பிப்பேன். இதைச் செய்வதற்கான காரணம் என்னவென்றால், நாங்கள் விவாதித்த எளிமையான ஒரு வழி ANOVA க்கு இடையிலான ஒற்றுமையை நான் முன்னிலைப்படுத்த விரும்புகிறேன்: DOC: முந்தைய அத்தியாயம் <../ CH13/CH13_ANOVA>, மேலும் நாம் மிகவும் சிக்கலான அணுகுமுறை இந்த அத்தியாயத்தில் பயன்படுத்தப் போகிறது.
நீங்கள் பகுப்பாய்வு செய்ய முயற்சிக்கும் தரவு ஒரு சீரான காரணி வடிவமைப்போடு ஒத்திருக்கும் என்றால், உங்கள் மாறுபாட்டின் பகுப்பாய்வை இயக்குவது எளிதானது. இது எவ்வளவு எளிதானது என்பதைப் பார்க்க, அத்தியாயம்: டாக்: ../ CH13/CH13_ANOVA இலிருந்து அசல் பகுப்பாய்வை மீண்டும் உருவாக்குவதன் மூலம் ஆரம்பிக்கலாம். நீங்கள் மறந்துவிட்டால், அந்த பகுப்பாய்விற்காக, எங்கள் விளைவு மாறியை (அதாவது, `` மனநிலை.கெய்ன்``) கணிக்க ஒரே ஒரு காரணியை (அதாவது, `` மருந்து``) பயன்படுத்துகிறோம், மேலும் அவை காட்டப்பட்ட முடிவுகளைப் பெற்றன .

Fig. 145 `` மருந்து` ஆல் `` மனநிலை.கெய்ன்` இன் சாமோவி ஒரு வழி அனோவா
இப்போது, `` சிகிச்சை`` `` மனநிலை.கெய்ன்`` உடன் உறவு இருக்கிறதா என்பதைக் கண்டறிய ஆர்வமாக உள்ளேன் என்று வைத்துக்கொள்வோம். அத்தியாயத்தில் பல பின்னடைவு பற்றிய எங்கள் விவாதத்திலிருந்து நாம் பார்த்தவற்றின் வெளிச்சத்தில்: DOC: ../ ch12/ch12_regression இரண்டாவது `` நிலையான காரணி`` `` பகுப்பாய்வில், காண்க: NumRef: Fig-factoralanova3.

Fig. 146 `` மனநிலை.
இந்த வெளியீட்டையும் படிக்க மிகவும் எளிது. அட்டவணையின் முதல் வரிசை `` மருந்து` காரணத்துடன் தொடர்புடைய சதுரங்கள் (எச்எச்) மதிப்புக்கு இடையில் ஒரு குழு *டிஎஃப் *-மதிப்பு ஆகியவற்றுடன் தொடர்புடையது. இது சராசரி சதுர மதிப்பு (எம்.எச்), ஒரு *எஃப் *-ச்டாடிச்டிக் மற்றும் ஒரு *பி *-மதிப்பு ஆகியவற்றைக் கணக்கிடுகிறது. `` சிகிச்சை` காரணி மற்றும் எச்சங்களுடன் தொடர்புடைய ஒரு வரிசை (அதாவது, குழுக்கள் மாறுபாடு) உடன் தொடர்புடைய ஒரு வரிசையும் உள்ளது.
அனைத்து தனிப்பட்ட அளவுகளும் மிகவும் பழக்கமானவை மட்டுமல்ல, இந்த வெவ்வேறு அளவுகளுக்கு இடையிலான உறவுகள் மாறாமல் உள்ளன, அசல் ஒரு வழி ANOVA உடன் நாம் பார்த்தது போல. தொடர்புடைய *df *ஆல் SS ஐ பிரிப்பதன் மூலம் சராசரி சதுர மதிப்பு கணக்கிடப்படுகிறது என்பதை நினைவில் கொள்க. அதாவது, இது இன்னும் உண்மை:
`` மருந்து`, `` சிகிச்சை`` அல்லது எஞ்சியவர்களைப் பற்றி நாங்கள் பேசுகிறோமா என்பதைப் பொருட்படுத்தாமல். இதைப் பார்க்க, சதுர மதிப்புகளின் தொகைகள் எவ்வாறு கணக்கிடப்படுகின்றன என்பதைப் பற்றி கவலைப்பட வேண்டாம். அதற்கு பதிலாக, சமோவி எச்எச் மதிப்புகளை சரியாக கணக்கிட்டுள்ளார் என்ற நம்பிக்கையின் மீது எடுத்துக்கொள்வோம், மீதமுள்ள எண்கள் அனைத்தும் அர்த்தமுள்ளதா என்பதை சரிபார்க்க முயற்சிக்கிறோம். முதலாவதாக, `` மருந்து` காரணத்திற்காக, நாங்கள் 3.45 ஐ 2 ஆல் பிரித்து 1.73 என்ற சராசரி சதுர மதிப்புடன் முடிவடைகிறோம் என்பதை நினைவில் கொள்க. `` சிகிச்சை` காரணத்திற்காக, 1 டிகிரி விடுதலை மட்டுமே உள்ளது, எனவே எங்கள் கணக்கீடுகள் இன்னும் எளிமையானவை: 0.47 (எச்எச் மதிப்பு) ஐ 1 ஆல் வகுப்பது 0.47 (எம்எச் மதிப்பு) பதிலை நமக்கு அளிக்கிறது.
*F *-புள்ளிவிவரங்கள் மற்றும் *p *-மதிப்புகள் ஆகியவற்றிற்கு திரும்பும்போது, ஒவ்வொன்றிலும் இரண்டு இருப்பதைக் கவனியுங்கள்; ஒன்று `` மருந்து` காரணியுடன் தொடர்புடையது, மற்றொன்று `` சிகிச்சை` காரணியுடன் தொடர்புடையது. நாம் எதைப் பற்றி பேசினாலும், *f *-statistict காரணிடன் தொடர்புடைய சராசரி சதுர மதிப்பை எச்சங்களுடன் தொடர்புடைய சராசரி சதுர மதிப்பால் பிரிப்பதன் மூலம் கணக்கிடப்படுகிறது. முதல் காரணி (காரணி A; இந்த விசயத்தில் `` மருந்து``) மற்றும் “ஆர்” ஆகியவற்றைக் குறிக்க “A” ஐ சுருக்கெழுத்து குறியீடாகப் பயன்படுத்தினால், எஞ்சியவர்களைக் குறிக்க சுருக்கெழுத்து குறியீடாக காரணி A எனக் குறிக்கப்படுகிறது *f *: sub: a, மற்றும் பின்வருமாறு கணக்கிடப்படுகிறது:
காரணி B க்கு சமமான தேற்றம் உள்ளது (அதாவது, `` சிகிச்சை``). மீதமுள்ளவற்றைக் குறிக்க “ஆர்” இன் இந்த பயன்பாடு சற்று மோசமானது என்பதை நினைவில் கொள்க, ஏனென்றால் அட்டவணையில் உள்ள வரிசைகளின் எண்ணிக்கையைக் குறிக்க R என்ற எழுத்தையும் நாங்கள் பயன்படுத்தினோம், ஆனால் நான் “ஆர்” ஐ மட்டுமே பயன்படுத்தப் போகிறேன் SS : துணை: r மற்றும் MS : துணை:` r` இன் சூழல், எனவே இது குழப்பமாக இருக்கக்கூடாது என்று நம்புகிறோம். எப்படியிருந்தாலும், இந்த சூத்திரத்தை `` மருந்து` காரணிக்கு பயன்படுத்த நாங்கள் 1.73 இன் சராசரி சதுரத்தை எடுத்து 0.07 இன் மீதமுள்ள சராசரி சதுர மதிப்பால் பிரிக்கிறோம், இது 26.15 இன் *f *-15 -15 ஐ வழங்குகிறது. `` சிகிச்சை` `மாறிக்கான தொடர்புடைய கணக்கீடு 0.47 ஆல் 0.07 ஆல் வகுக்க வேண்டும், இது 7.08 ஐ *f *-statistic ஆக வழங்குகிறது. ஆச்சரியப்படுவதற்கில்லை, நிச்சயமாக, மேலே உள்ள ANOVA அட்டவணையில் சமோவி புகாரளித்த அதே மதிப்புகள் இவைதான்.
ANOVA அட்டவணையில் p *-மதிப்புகளின் கணக்கீடு உள்ளது. மீண்டும், இங்கே புதிதாக எதுவும் இல்லை. எங்கள் இரண்டு காரணிகளில் ஒவ்வொன்றிற்கும், நாங்கள் செய்ய முயற்சிப்பது காரணி மற்றும் விளைவு மாறிக்கு இடையில் எந்த உறவும் இல்லை என்ற சுழிய கருதுகோளை சோதிப்பதாகும் (இதைப் பற்றி நான் பின்னர் இன்னும் கொஞ்சம் துல்லியமாக இருப்பேன்). அதற்காக, நாங்கள் (வெளிப்படையாக) ஒரு வழி ANOVA இல் செய்ததைப் போன்ற ஒரு மூலோபாயத்தைப் பின்பற்றி, இந்த ஒவ்வொரு கருதுகோள்களுக்கும் ஒரு *F *-புள்ளிவிவரத்தை கணக்கிட்டுள்ளோம். இவற்றை*பி-மதிப்புகளாக மாற்ற, நாம் செய்ய வேண்டியது சுழிய கருதுகோளின் கீழ்*f*-புள்ளிவிவர*க்கான மாதிரி வழங்கல் (கேள்விக்குரிய காரணி பொருத்தமற்றது) ஒரு*f-* விநியோகம்*. இரண்டு டிகிரி சுதந்திர மதிப்புகள் காரணி மற்றும் எஞ்சியவற்றுடன் தொடர்புடையவை என்பதையும் நினைவில் கொள்க. `` மருந்து` காரணத்திற்காக, 2 மற்றும் 14 டிகிரி சுதந்திரத்துடன் ஒரு *f *- விநியோகத்தைப் பற்றி பேசுகிறோம் (நான் சுதந்திரத்தின் அளவுகளை பின்னர் விரிவாக விவாதிப்பேன்). இதற்கு நேர்மாறாக, `` சிகிச்சை` காரணத்திற்காக மாதிரி வழங்கல் 1 மற்றும் 14 டிகிரி சுதந்திரத்துடன் * f * ஆகும்.
இந்த கட்டத்தில், இந்த மிகவும் சிக்கலான காரணியாலான பகுப்பாய்விற்கான ANOVA அட்டவணை எளிமையான ஒரு வழி பகுப்பாய்விற்கான ANOVA அட்டவணையைப் போலவே படிக்க வேண்டும் என்பதை நீங்கள் காணலாம் என்று நம்புகிறேன். சுருக்கமாக, எங்கள் 3 × 2 வடிவமைப்பிற்கான காரணி ANOVA மருந்தின் குறிப்பிடத்தக்க விளைவைக் கண்டறிந்தது: f *(2,14) = 26.15, *p *<0.001, அத்துடன் சிகிச்சையின் குறிப்பிடத்தக்க விளைவு: *F(1,14) = 7.08,*ப*= 0.02. அல்லது, தொழில்நுட்ப ரீதியாக சரியான சொற்களைப் பயன்படுத்த, மருந்து மற்றும் சிகிச்சையின் இரண்டு ** முக்கிய விளைவுகள் ** உள்ளன என்று நாங்கள் கூறுவோம். இந்த நேரத்தில், இவற்றை "முக்கிய" விளைவுகள் என்று குறிப்பிடுவது சற்று பணிநீக்கம் செய்யப்பட்டதாகத் தெரிகிறது, ஆனால் அது உண்மையில் அர்த்தமுள்ளதாக இருக்கிறது. பிற்காலத்தில், இரண்டு காரணிகளுக்கிடையேயான “தொடர்புகளின்” சாத்தியத்தைப் பற்றி பேச விரும்புகிறோம், எனவே பொதுவாக முக்கிய விளைவுகளுக்கும் தொடர்பு விளைவுகளுக்கும் இடையில் வேறுபாட்டை உருவாக்குகிறோம்.
சதுரங்களின் தொகை எவ்வாறு கணக்கிடப்படுகிறது?
முந்தைய பிரிவில் எனக்கு இரண்டு இலக்குகள் இருந்தன. முதலாவதாக, காரணியாலான ANOVA ஐ செய்ய சமோவி முறை ஒரு வழி ANOVA க்கு நாங்கள் பயன்படுத்தியதைப் போலவே உள்ளது என்பதை உங்களுக்குக் காண்பிப்பது. ஒரே வேறுபாடு இரண்டாவது காரணியைச் சேர்ப்பதுதான். இரண்டாவதாக, இந்த விசயத்தில் ANOVA அட்டவணை எப்படி இருக்கும் என்பதை நான் உங்களுக்குக் காட்ட விரும்பினேன், இதன் மூலம் காரணி ANOVA க்குப் பின்னால் உள்ள அடிப்படை தர்க்கமும் கட்டமைப்பும் ஒரு வழி ANOVA ஐ ஆதரிப்பதைப் போன்றது என்பதை நீங்கள் ஆரம்பத்தில் இருந்தே காணலாம். அந்த உணர்வைப் பிடிக்க முயற்சி செய்யுங்கள். இது உண்மையிலேயே உண்மை, காரணியாலான ANOVA எளிமையான ஒரு வழி ANOVA மாதிரியைப் போலவே அதிகமாகவோ அல்லது குறைவாகவோ கட்டப்பட்டுள்ளது. நீங்கள் விவரங்களைத் தோண்டத் தொடங்கியவுடன் இந்த பரிச்சயமான உணர்வு ஆவியாகத் தொடங்குகிறது. பாரம்பரியமாக, இந்த ஆறுதலான உணர்வு புள்ளிவிவர பாடப்புத்தகங்களின் ஆசிரியர்களிடம் தீய பயன்பாடு செய்ய வேண்டும் என்ற தூண்டுதலால் மாற்றப்படுகிறது.
சரி, அந்த விவரங்களில் சிலவற்றைப் பார்த்து ஆரம்பிக்கலாம். கடைசி பிரிவில் நான் கொடுத்த விளக்கம் முக்கிய விளைவுகளுக்கான கருதுகோள் சோதனைகள் (`` மருந்து`` மற்றும் `` சிகிச்சை`` இந்த விசயத்தில்) f *-tests, ஆனால் அது என்ன செய்யாது என்ற உண்மையை விளக்குகிறது சதுரங்கள் (எச்எச்) மதிப்புகளின் தொகை எவ்வாறு கணக்கிடப்படுகிறது என்பதைக் காண்பிப்பதாகும். ஒப்பிடுவதன் மூலம் இது ஒரு எளிய சேதி என்றாலும், சுதந்திரத்தின் அளவுகளை எவ்வாறு கணக்கிடுவது (*df-மதிப்புகள்) என்பதை இது வெளிப்படையாகச் சொல்லவில்லை. விளைவு மாறியைக் குறிக்க நாம் *y *ஐப் பயன்படுத்தினால், காரணி A மற்றும் காரணி B. குழு RC இன் I-TH உறுப்பினருடன் தொடர்புடையது (அதாவது, காரணி A மற்றும் நிலை/நெடுவரிசை * C * காரணி B க்கு நிலை/வரிசை * r *). ஆகவே, ஒரு மாதிரி சராசரியைக் குறிக்க நாம் பயன்படுத்தினால், குழு வழிமுறைகள், விளிம்பு வழிமுறைகள் மற்றும் பெரிய வழிமுறைகளைக் குறிக்க முன்பு இருந்த அதே குறியீட்டைப் பயன்படுத்தலாம். அதாவது, ȳ : துணை: rc என்பது காரணி A இன் *r *வது நிலை மற்றும் *C *வது காரணி B, ȳ : துணை:` r.` உடன் தொடர்புடைய மாதிரி சராசரி காரணி A, ȳ : துணை: .c காரணி B இன் *c *வது நிலை, மற்றும் ȳ : sub:` .. `என்பது பெரிய சராசரி. வேறு வார்த்தைகளில் கூறுவதானால், எங்கள் மாதிரி வழிமுறைகள் மக்கள்தொகையின் அதே அட்டவணையில் ஒழுங்கமைக்கப்படலாம். எங்கள் | கிளினிக்கல் ட்ரீல் | _ தரவுகளுக்கு, அந்த அட்டவணை இப்படி தெரிகிறது:
மருத்தீடு இல்லை |
சிபிடி |
மொத்தம் |
|
|---|---|---|---|
placebo |
Ȳ11 |
Ȳ12 |
Ȳ1. |
anxifree |
Ȳ21 |
Ȳ22 |
Ȳ2. |
joyzepam |
Ȳ31 |
Ȳ32 |
Ȳ3. |
** மொத்தம் ** |
Ȳ.1 |
Ȳ.2 |
Ȳ.. |
மாதிரியைப் பார்த்தால், நான் முன்பு காட்டினேன் என்று பொருள், எங்களிடம் ȳ : துணை: 11 = 0.30, ȳ : துணை:` 12` = 0.60 போன்றவை. `` காரணி 3 நிலைகளைக் கொண்டுள்ளது மற்றும் `` சிகிச்சை`` காரணி 2 நிலைகளைக் கொண்டுள்ளது, எனவே நாங்கள் இயக்க முயற்சிப்பது 3 × 2 காரணியாலான ANOVA ஆகும். இருப்பினும், நாங்கள் இன்னும் கொஞ்சம் பொதுவானவராக இருப்போம், காரணி A (வரிசை காரணி) * r * அளவுகள் மற்றும் காரணி B (நெடுவரிசை காரணி) * c * அளவைக் கொண்டுள்ளது என்று கூறுவோம், எனவே இங்கே நாங்கள் இயங்குவது ஒரு r ஆகும் × சி காரணி ANOVA.
இப்போது எங்கள் குறியீட்டை நேராகப் பெற்றுள்ளோம், ஒவ்வொரு இரண்டு காரணிகளுக்கும் சதுர மதிப்புகளின் தொகையை ஒப்பீட்டளவில் பழக்கமான முறையில் கணக்கிடலாம். காரணி A ஐப் பொறுத்தவரை, (வரிசை) விளிம்பு என்றால் ȳ : துணை: 1., ȳ : துணை:` 2.` போன்றவற்றிலிருந்து எந்த அளவிற்கு மதிப்பிடுவதன் மூலம் சதுரங்களின் குழு தொகை கணக்கிடப்படுகிறது சராசரி ȳ : துணை: .. . ஒரு வழி ANOVA க்காக நாங்கள் செய்ததைப் போலவே இதைச் செய்கிறோம்: ȳ : துணை: I. மதிப்புகள் மற்றும் ȳ : துணை:` ..` மதிப்புகளுக்கு இடையிலான சதுர வேறுபாட்டின் தொகையை கணக்கிடுங்கள். குறிப்பாக, ஒவ்வொரு குழுவிலும் * n * நபர்கள் இருந்தால், நாங்கள் இதைக் கணக்கிடுகிறோம்
ஒரு வழி ANOVA ஐப் போலவே, இந்த சூத்திரத்தின் மிகவும் சுவையான [#] _ ஒரு பகுதி (ȳ : sub: r.-ȳ : sub:` ..`) ² பிட், இது ச்கொயர் உடன் ஒத்திருக்கிறது நிலை *r *உடன் தொடர்புடைய விலகல். இந்த தேற்றம் செய்யும் அனைத்தும் காரணி அனைத்து *r *நிலைகளுக்கும் இந்த சதுர விலகலைக் கணக்கிடுவது, அவற்றைச் சேர்க்கவும், பின்னர் முடிவை *n *× *C *மூலம் பெருக்கவும். இந்த கடைசி பகுதிக்கான காரணம் என்னவென்றால், எங்கள் வடிவமைப்பில் பல செல்கள் உள்ளன, அவை காரணி A இல் நிலை * r * உள்ளன. உண்மையில், அவற்றில் * c * உள்ளன, இது காரணி B இன் ஒவ்வொரு மட்டத்திற்கும் தொடர்புடையது! உதாரணமாக, எங்கள் எடுத்துக்காட்டில் `` கவலை 'மருந்துடன் தொடர்புடைய வடிவமைப்பில் * இரண்டு * வெவ்வேறு செல்கள் உள்ளன: ஒன்று ``. அது மட்டுமல்லாமல், இந்த ஒவ்வொரு உயிரணுக்களிலும் * n * அவதானிப்புகள் உள்ளன. எனவே, எங்கள் எச்எச் மதிப்பை “ஒரு கண்காணிப்புக்கு” அடிப்படையில் குழுக்களின் தொகையை கணக்கிடும் அளவாக மாற்ற விரும்பினால், நாம் *n *× *c *ஆல் பெருக்க வேண்டும். காரணி B க்கான தேற்றம் நிச்சயமாக ஒரே சேதி
இப்போது எங்களிடம் இந்த சூத்திரங்கள் இருப்பதால், முந்தைய பகுதியிலிருந்து சாமோவி வெளியீட்டிற்கு எதிராக அவற்றை சரிபார்க்கலாம்.
முதலில், `` மருந்து`` இன் முக்கிய விளைவுடன் தொடர்புடைய சதுரங்களின் தொகையை கணக்கிடுவோம். ஒவ்வொரு குழுவிலும் மொத்தம் * n * = 3 பேர் மற்றும் * c * = 2 வெவ்வேறு வகையான சிகிச்சைகள் உள்ளன. அல்லது, இதை வேறு வழியில் செலுத்த, எந்தவொரு குறிப்பிட்ட மருந்தையும் பெற்ற 3 · 2 = 6 பேர் உள்ளனர். இந்த கணக்கீடுகளை ஒரு விரிதாள் திட்டத்தில் செய்யும்போது, `` மருந்து`` இன் முக்கிய விளைவுடன் தொடர்புடைய சதுரங்களின் தொகைக்கு 3.45 மதிப்பைப் பெறுகிறோம். ஆச்சரியப்படுவதற்கில்லை, நான் முன்பு வழங்கிய ANOVA அட்டவணையில் `` மருந்து`` காரணிக்கான SS மதிப்பைப் பார்க்கும்போது நீங்கள் பெறும் அதே எண் இதுதான்: IN: NUMREF: Fig-factoriananova3.
`` சிகிச்சை`` இன் விளைவுக்கு அதே வகையான கணக்கீட்டை நாம் மீண்டும் செய்யலாம். மீண்டும், ஒவ்வொரு குழுவிலும் * n * = 3 பேர் உள்ளனர், ஆனால் `` மருந்து`` இல் r = 3 வெவ்வேறு மதிப்புகள் இருப்பதால், இந்த நேரத்தில் `` cbt` பெற்ற 3 · 3 = 9 பேர் இருக்கிறார்கள் என்பதை நாங்கள் கவனிக்கிறோம் மற்றும் கூடுதலாக 9 பேர் இல்லை. எனவே இந்த வழக்கில் எங்கள் கணக்கீடு ` சிகிச்சை`` இன் முக்கிய விளைவுடன் தொடர்புடைய சதுரங்களின் தொகைக்கு 0.47 மதிப்பை நமக்கு வழங்குகிறது. மீண்டும், எங்கள் கணக்கீடுகள் ANOVA வெளியீட்டிற்கு ஒத்தவை என்பதைக் கண்டு நாங்கள் ஆச்சரியப்படுவதில்லை: NumRef: Fig-factoralanova3.
எனவே இரண்டு முக்கிய விளைவுகளுக்கான SS மதிப்புகளை நீங்கள் எவ்வாறு கணக்கிடுகிறீர்கள். இந்த எச்எச் மதிப்புகள் ஒரு வழி ANOVA ஐச் செய்யும்போது நாம் கணக்கிட்ட சதுர மதிப்புகளின் குழுக்கு இடையிலான தொகைக்கு ஒப்பானவை: doc: முந்தைய அத்தியாயம் <../ ch13/ch13_anova>. எவ்வாறாயினும், குழுக்களுக்கு இடையில் எச்.எச் மதிப்புகள் என நினைப்பது நல்ல யோசனையல்ல, ஏனென்றால் எங்களிடம் இரண்டு வெவ்வேறு குழும மாறிகள் இருப்பதால், குழப்பமடைவது எளிது. இருப்பினும், ஒரு *f *-Test ஐ உருவாக்க, இருப்பினும், குழுக்களுக்குள் சதுரங்களின் தொகையை கணக்கிட வேண்டும். அத்தியாயத்தில் நாம் பயன்படுத்திய சொற்களாட்டைக் கருத்தில் கொண்டு: டாக்: ../ சி.எச். * சதுரங்களின் தொகை ss : sub: `r.
இந்த சூழலில் மீதமுள்ள எச்எச் மதிப்புகளைப் பற்றி சிந்திக்க எளிதான வழி, நான் நினைக்கிறேன், விளிம்பு வழிமுறைகளில் உள்ள வேறுபாடுகளை நீங்கள் கணக்கில் எடுத்துக் கொண்ட பிறகு (அதாவது, நீங்கள் ss : துணை: அ மற்றும் எச்எச் : துணை:` பி`). இதன் மூலம் நான் சொல்வது என்னவென்றால், சதுரங்களின் மொத்த தொகையை கணக்கிடுவதன் மூலம் நாம் தொடங்கலாம், இதை நான் SS : துணை: T என்று லேபிளிடுவேன். இதற்கான தேற்றம் ஒரு வழி ANOVA க்கு இருந்ததைப் போலவே உள்ளது. ஒவ்வொரு அவதானிப்புக்கும் இடையிலான வித்தியாசத்தை நாம் எடுத்துக்கொள்கிறோம் *y *: sub: rci மற்றும் கிராண்ட் சராசரி ȳ : sub:` ..`, வேறுபாடுகளை சதுரப்படுத்தி, அனைத்தையும் சேர்க்கவும்
இங்கே “டிரிபிள் சம்மேசன்” அதை விட மிகவும் சிக்கலானது. முதல் இரண்டு சுருக்கங்களில், காரணி A இன் அனைத்து மட்டங்களிலும் (அதாவது, எங்கள் அட்டவணையில் சாத்தியமான அனைத்து வரிசைகளிலும் *r *) மற்றும் காரணி B இன் அனைத்து மட்டங்களிலும் (அதாவது, சாத்தியமான அனைத்து நெடுவரிசைகளும் *c *) சுருக்கமாகக் கூறுகிறோம். ஒவ்வொரு ஆர்.சி. வேறு வார்த்தைகளில் கூறுவதானால், தரவுத் தொகுப்பில் உள்ள அனைத்து அவதானிப்புகளிலும் (அதாவது, சாத்தியமான அனைத்து ஆர்.சி.ஐ-போட்டிகளும்) நாங்கள் இங்கு செய்கிறோம்.
இந்த கட்டத்தில், விளைவு மாறி SS : t இன் மொத்த மாறுபாட்டை நாங்கள் அறிவோம், மேலும் அந்த மாறுபாட்டின் காரணி A (ss : sub:` a`) க்கு எவ்வளவு காரணம் என்று எங்களுக்குத் தெரியும் இது காரணி B (SS : SUB: B) காரணமாக இருக்கலாம். சதுரங்களின் எஞ்சிய தொகை * ஒய் * இல் உள்ள மாறுபாடாக வரையறுக்கப்படுகிறது, இது எங்கள் இரண்டு காரணிகளில் ஒன்றுக்கு * * கூற முடியாது. வேறு வார்த்தைகளில் கூறுவதானால்
Of course, there is a formula that you can use to calculate the residual SS (SSR) directly, but I think that it makes more conceptual sense to think of it like this. The whole point of calling it a residual is that it’s the leftover variation, and the formula above makes that clear. I should also note that, in keeping with the terminology used in the regression chapter, it is commonplace to refer to SSA + SSB as the variance attributable to the “ANOVA model”, denoted SSM, and so we often say that the total sum of squares is equal to the model sum of squares plus the residual sum of squares. Later on in this chapter we’ll see that this isn’t just a surface similarity: ANOVA and regression are actually the same thing under the hood.
எவ்வாறாயினும், SS : Sub: r இந்த சூத்திரத்தைப் பயன்படுத்தி கணக்கிட முடியுமா என்பதைச் சரிபார்க்க சிறிது நேரம் எடுத்துக்கொள்ளலாம், மேலும் சாமோவி அதன் ANOVA அட்டவணையில் உருவாக்கும் அதே பதிலைப் பெறுகிறோமா என்பதை சரிபார்க்கவும். சமோவியில் கணக்கிடப்பட்ட மாறிகளைப் பயன்படுத்தி செய்யும்போது கணக்கீடுகள் மிகவும் நேரடியானவை. மூன்று கணக்கிடப்பட்ட மாறிகள் | `` (vmean (meod.gain) - vmean (mood.gain, group_by = மருந்து)) ^ 2`` சூத்திரமாக, மற்றும் (3) `` sq_res_b`` .gain) - vmean (mood.gain, group_by = சிகிச்சை)) ^ 2`` சூத்திரமாக. அந்த மூன்று மாறிகளை உருவாக்கியதும், `` விளக்கங்கள்` `` `` விளக்க புள்ளிவிவரங்கள்`` ஐப் பயன்படுத்தி சதுரங்களின் தொகையை நாங்கள் கணக்கிடுகிறோம், பின்னர் `` sq_res_t``, `` sq_res_a`` மற்றும் `` sq_res_b` க்கு `` sq_res_b மாறிகள்`` பெட்டியில், இறுதியாக `` புள்ளிவிவரங்கள்` கீழ்தோன்றும் மெனுவிலிருந்து `` தொகை` என்பதைத் தேர்ந்தெடுங்கள். Ss : sub: t (` sq_res_t`) ** 4.845 **, ss : துணை:` a` (`` sq_res_a``) மதிப்பின் மதிப்பு ** 3.453 **, மற்றும் SS : துணை: B (` sq_res_b`) ** 0.467 ** இன் மதிப்பு. இந்த மூன்று மதிப்புகளைப் பயன்படுத்தி, மேலே உள்ள சூத்திரத்தைப் பயன்படுத்தி SS : துணை: r கணக்கிடலாம்.
மாற்றாக, `` SS_R`` என்ற பெயருடன் மற்றொரு கணக்கிடப்பட்ட மாறியை உருவாக்கலாம் மற்றும் `` vsum (Sq_res_t) - (vsum (sq_res_a) + vsum (sq_res_b)) ``.
எங்கள் விடுதலை என்ன?
சுதந்திரத்தின் அளவுகள் ஒரு வழி ANOVA ஐப் போலவே கணக்கிடப்படுகின்றன. எந்தவொரு காரணிக்கும், சுதந்திரத்தின் அளவுகள் மைனச் 1 நிலைகளின் எண்ணிக்கைக்கு சமம் (அதாவது, வரிசை மாறி காரணி A க்கு r - 1, மற்றும் நெடுவரிசை மாறி காரணி B க்கு C - 1). எனவே, `` மருந்து` காரணத்திற்காக நாம் * df * = 2 ஐப் பெறுகிறோம், மேலும் `` சிகிச்சை` காரணத்திற்காக நாம் * df * = 1 ஐப் பெறுகிறோம். பின்னர், ANOVA இன் பின்னடைவு மாதிரியாக நாம் விவாதிக்கும்போது ( பிரிவு: DOC: ANOVA ஒரு நேரியல் மாதிரியாக <CH14_ANOVA2_07>), இந்த எண்ணை நாங்கள் எவ்வாறு வருகிறோம் என்பதற்கான தெளிவான அறிக்கையை தருகிறேன். ஆனால் இப்போதைக்கு நாம் சுதந்திரத்தின் அளவுகளின் எளிய வரையறையைப் பயன்படுத்தலாம், அதாவது சுதந்திரத்தின் அளவுகள் கவனிக்கப்படும் அளவுகளின் எண்ணிக்கைக்கு சமம், தடைகளின் எண்ணிக்கையை குறைக்கின்றன. எனவே, `` மருந்து` காரணத்திற்காக, நாங்கள் 3 தனித்தனி குழு வழிகளைக் கவனிக்கிறோம், ஆனால் இவை 1 பெரிய சராசரியால் கட்டுப்படுத்தப்படுகின்றன, எனவே சுதந்திரத்தின் அளவுகள் 2. எஞ்சியவர்களுக்கு, வழக்கு ஒத்ததாக இருக்கிறது, ஆனால் மிகவும் ஒன்றல்ல . எங்கள் பரிசோதனையில் மொத்த அவதானிப்புகள் 18 ஆகும். தடைகள் 1 பெரிய சராசரிக்கு ஒத்திருக்கும், 2 கூடுதல் குழு என்பது `` மருந்து`` காரணி அறிமுகப்படுத்துகிறது, மற்றும் 1 கூடுதல் குழு `` சிகிச்சை`` காரணி அறிமுகப்படுத்துகிறது என்பதாகும் , எனவே எங்கள் சுதந்திரத்தின் அளவுகள் 14 ஆகும். ஒரு சூத்திரமாக, இது* n* - 1 - (* r* - 1) - (* c* - 1), இது* n* -* r* -* க்கு எளிதாக்குகிறது சி* + 1.
சுதந்திரத்தின் அளவுகள் மற்றும் நாம் மேலே கணக்கிட்ட சதுர தொகைகளைப் பயன்படுத்தி, A மற்றும் B என்ற காரணிகளுக்கான பின்வரும் *f *-மதிப்புகளைக் கணக்கிடலாம்.
மீண்டும், நாம் இரண்டு புதிய கணக்கிடப்பட்ட மாறிகளையும் உருவாக்கலாம், முதலாவது `` f_a`` மற்றும் தேற்றம் `` (vsum (sq_res_a) / 2) / (ss_r / 14) , மற்றும் இரண்டாவது `பெயரைக் கொண்ட சூத்திரம்` ` `F_b மற்றும் சூத்திரம்` (vsum (sq_res_b) / 1) / (ss_r / 14) `.
தங்களைத் தாங்களே செல்ல விரும்பாதவர்கள் அல்லது முந்தைய பத்திகளில் விவரிக்கப்பட்டுள்ள கணக்கீடுகளை இனப்பெருக்கம் செய்ய முடியாதவர்கள் | கிளினிக்கல் ட்ரையல்_பீக்டோரியனோவா | _ தரவு தொகுப்பு மற்றும் அங்குள்ள கணக்கீடுகளைப் பார்க்கலாம்.
காரணி ANOVA Vs ஒரு வழி ANOVA
இப்போது நாம் பார்த்திருக்கிறோம் * ஒரு காரணியாக ANOVA எவ்வாறு செயல்படுகிறது, ஒரு வழி பகுப்பாய்வுகளின் முடிவுகளுடன் அதை ஒப்பிட்டுப் பார்க்க ஒரு கணம் எடுத்துக்கொள்வது மதிப்பு, ஏனென்றால் இது எங்களுக்கு ஒரு நல்ல உணர்வைத் தரும் * ஏன் * இது ஒரு நல்ல சிந்தனை காரணி ANOVA ஐ இயக்கவும். அத்தியாயத்தில்: DOC: ../ ch13/ch13_anova, நான் ஒரு வழி ANOVA ஐ ஓடினேன், அது` மருந்து` என்ற மூன்று நிலைகளுக்கு இடையில் ஏதேனும் வேறுபாடுகள் இருக்கிறதா என்று பார்த்தேன், பார்க்க இரண்டாவது ஒரு வழி ANOVA `` சிகிச்சை`` இன் இரண்டு நிலைகளுக்கு இடையில் ஏதேனும் வேறுபாடுகள் இருந்தால். பிரிவில் நாம் பார்த்தது போல: குறிப்பு: நாம் என்ன கருதுகோள்களைச் சோதிக்கிறோம்? <வாட்_இபோதெச்> `, ஒரு வழி ANOVA களால் சோதிக்கப்பட்ட சுழிய மற்றும் மாற்று கருதுகோள்கள் உண்மையில் காரணியாலான ANOVA ஆல் சோதிக்கப்பட்ட கருதுகோள்களுக்கு ஒத்தவை. ANOVA அட்டவணைகளை இன்னும் கவனமாகப் பார்க்கும்போது, காரணிகளுடன் தொடர்புடைய சதுரங்களின் தொகை இரண்டு வெவ்வேறு பகுப்பாய்வுகளில் (` மருந்து`` 3.453 மற்றும் சிகிச்சைக்கு 0.467), டிகிரி போன்றவை என்பதைக் காணலாம். விடுதலை (2 ` மருந்து``, 1 `` சிகிச்சை`` க்கு). ஆனால் அவர்கள் அதே பதில்களைக் கொடுக்க மாட்டார்கள்! மிக முக்கியமாக, பிரிவில் `` சிகிச்சை` க்கான ஒரு வழி ANOVA ஐ நாங்கள் இயக்கியபோது: DOC: ../ ch13/ch13_anova_09 நாங்கள் ஒரு குறிப்பிடத்தக்க விளைவைக் காணவில்லை ( *p *-மதிப்பு 0.210). எவ்வாறாயினும், இரு வழி ANOVA இன் சூழலில் `` சிகிச்சை`` இன் முக்கிய விளைவைப் பார்க்கும்போது, நாம் ஒரு குறிப்பிடத்தக்க விளைவைப் பெறுகிறோம் (ப = 0.019). இரண்டு பகுப்பாய்வுகளும் தெளிவாக ஒன்றல்ல.
அது ஏன் நடக்கும்? * எச்சங்கள் * எவ்வாறு கணக்கிடப்படுகின்றன என்பதைப் புரிந்துகொள்வதில் பதில் உள்ளது. ஒரு *f *-test க்கு பின்னால் உள்ள முழு யோசனையும் ஒரு குறிப்பிட்ட காரணிக்கு காரணமாகக் கூறக்கூடிய மாறுபாட்டை (எச்சங்கள்) கணக்கிட முடியாத மாறுபாட்டுடன் ஒப்பிடுவதாகும் என்பதை நினைவில் கொள்க. `` சிகிச்சை`` க்காக நீங்கள் ஒரு வழி ANOVA ஐ இயக்கினால், எனவே `` மருந்து`` இன் விளைவை புறக்கணித்தால், ANOVA மருந்து தூண்டப்பட்ட அனைத்து மாறுபாடுகளையும் எச்சங்களில் கொட்டுகிறது! இது தரவை உண்மையில் இருப்பதை விட சத்தமாக தோற்றமளிக்கும் விளைவைக் கொண்டுள்ளது, மேலும் `` சிகிச்சை`` இன் விளைவு இரு வழி ANOVA இல் குறிப்பிடத்தக்கதாகக் காணப்படுகிறது, இது இப்போது குறிப்பிடத்தக்கதாக இல்லை. வேறொன்றின் பங்களிப்பை (எ.கா., சிகிச்சை`) மதிப்பிட முயற்சிக்கும்போது உண்மையில் முக்கியமான ஒன்றை (எ.கா.,` மருந்து`) புறக்கணித்தால், எங்கள் பகுப்பாய்வு சிதைக்கப்படும். நிச்சயமாக, ஆர்வத்தின் நிகழ்வுக்கு மிகவும் பொருத்தமற்ற மாறிகளை புறக்கணிப்பது மிகவும் சரி. சுவர்களின் நிறத்தை நாங்கள் பதிவுசெய்திருந்தால், அது மூன்று வழி ANOVA இல் குறிப்பிடத்தக்க காரணியாக மாறியிருந்தால், அதைப் புறக்கணித்து, எளிமையான இரு வழி ANOVA ஐப் புகாரளிப்பது சரியாக இருக்கும் இந்த பொருத்தமற்ற காரணி. நீங்கள் செய்யக் கூடாது என்பது உண்மையில் ஒரு வித்தியாசத்தை ஏற்படுத்தும் மாறிகள்!

Fig. 147 எந்த இடைவினைகளும் இல்லாதபோது 2 × 2 ANOVA க்கான நான்கு வெவ்வேறு முடிவுகள். மேல்-இடது பேனலில், காரணி A இன் முக்கிய விளைவைக் காண்கிறோம் மற்றும் காரணி B இன் எந்த விளைவும் இல்லை. மேல்-வலதுசாரி குழு காரணி B இன் முக்கிய விளைவைக் காட்டுகிறது, ஆனால் காரணி A இன் விளைவு இல்லை. கீழ்-இடது குழு முக்கிய விளைவுகளைக் காட்டுகிறது காரணி ஏ மற்றும் காரணி பி இரண்டும் இறுதியாக, எந்தவொரு காரணியும் ஒரு விளைவைக் கொண்டிருக்கவில்லை என்றால் கீழ்-வலது குழு காட்டுகிறது.
இந்த பகுப்பாய்வு என்ன வகையான விளைவுகளைப் பிடிக்கிறது?
இதுவரை நாங்கள் பேசிக் கொண்டிருக்கும் ANOVA மாதிரி எங்கள் தரவுகளில் நாம் கவனிக்கக்கூடிய பல்வேறு வடிவங்களின் வரம்பை உள்ளடக்கியது. உதாரணமாக, இரு வழி ANOVA வடிவமைப்பில் நான்கு சாத்தியங்கள் உள்ளன. இந்த நான்கு சாத்தியக்கூறுகளில் ஒவ்வொன்றிற்கும் ஒரு எடுத்துக்காட்டு: NumRef: Fig-Maineffects: (1) காரணி ஒரு விசயங்கள் (மேல்-இடது), (2) ஒரே காரணி B விசயங்கள் (மேல்-வலது), (3) இரண்டும் A மற்றும் b மேட்டர் (கீழ்-இடது), மற்றும் (4) a அல்லது b விசயங்கள் (கீழ்-வலது).