Section author: Danielle J. Navarro and David R. Foxcroft
சுயாதீன மாதிரிகள் *t *-test (மாணவர் சோதனை)
ஒரு மாதிரி *t *-test அதன் பயன்பாடுகளைக் கொண்டிருந்தாலும், இது *t *-test இன் மிகச் சிறந்த எடுத்துக்காட்டு அல்ல. [#] _ உங்களுக்கு இரண்டு வெவ்வேறு குழுக்கள் அவதானிப்புகள் கிடைக்கும்போது மிகவும் பொதுவான நிலைமை எழுகிறது. உளவியலில், இது பங்கேற்பாளர்களின் இரண்டு வெவ்வேறு குழுக்களுடன் ஒத்துப்போகிறது, அங்கு ஒவ்வொரு குழுவும் உங்கள் ஆய்வில் வேறுபட்ட நிலைக்கு ஒத்திருக்கிறது. ஆய்வில் உள்ள ஒவ்வொரு நபருக்கும் நீங்கள் சில விளைவு ஆர்வத்தை அளவிடுகிறீர்கள், மேலும் நீங்கள் கேட்கும் ஆராய்ச்சி கேள்வி இரு குழுக்களுக்கும் ஒரே மக்கள் தொகை இருக்கிறதா இல்லையா என்பதுதான். சுயாதீன மாதிரிகள் *t *-test வடிவமைக்கப்பட்ட நிலைமை இதுதான்.
தரவு
டாக்டர் ஆர்போவின் புள்ளிவிவர விரிவுரைகளை எடுத்த 33 மாணவர்கள் எங்களிடம் உள்ளனர் என்று வைத்துக்கொள்வோம், டாக்டர் ஆர்போ ஒரு வளைவுக்கு தகுதி இல்லை. உண்மையில், டாக்டர் ஆர்போவின் தரப்படுத்தல் ஒரு மர்மம், எனவே ஒட்டுமொத்த வகுப்பிற்கு சராசரி தகுதி என்ன என்பது பற்றி எங்களுக்கு எதுவும் தெரியாது. வகுப்பிற்கு இரண்டு ஆசிரியர்கள் உள்ளனர், அனச்தேசியா மற்றும் பெர்னாடெட். *N *: துணை: 1 = 15 மாணவர்கள் அனச்தேசியாவின் பயிற்சிகளில், மற்றும் *n *: துணை:` 2` = 18 பெர்னாடெட்டின் பயிற்சிகளில். அனச்தேசியா அல்லது பெர்னாடெட் ஒரு சிறந்த ஆசிரியரா, அல்லது அது அதிக வித்தியாசத்தை ஏற்படுத்தவில்லையா என்பதுதான் நான் ஆர்வமாக உள்ள ஆராய்ச்சி கேள்வி. டாக்டர் ஆர்போ எனக்கு | ஆர்போ | _ பாடத்திட்ட தரங்களுடன் அமைக்கப்பட்டுள்ளது. கோப்பு. வழக்கம் போல், நான் கோப்பை சாமோவியில் ஏற்றுவேன், அதில் என்ன மாறிகள் உள்ளன என்பதைப் பார்ப்பேன் - மூன்று மாறிகள் உள்ளன, `` ஐடி``, `` கிரேடு`` மற்றும் `` ஆசிரியர்`. `` கிரேடு`` மாறுபாடு ஒவ்வொரு மாணவரின் தரத்தையும் கொண்டுள்ளது, ஆனால் அது சரியான அளவீட்டு நிலை பண்புடன் சாமோவியில் இறக்குமதி செய்யப்படவில்லை, எனவே இதை மாற்ற வேண்டும், எனவே இது தொடர்ச்சியான மாறி | தொடர்ச்சியான | . `` ஆசிரியர்`` மாறி ஒரு காரணி | பெயரளவு | ஒவ்வொரு மாணவரின் ஆசிரியரும் யார் என்பதை இது குறிக்கிறது - அனச்தேசியா அல்லது பெர்னாடெட்.
`` ஆய்வு` → `` டிச்கிரிப்டிவ்`` பகுப்பாய்வைப் பயன்படுத்தி, வழிமுறைகளையும் நிலையான விலகலையும் நாம் கணக்கிட முடியும், மேலும் இங்கே ஒரு சிறிய சிறிய சுருக்க அட்டவணை:
இடை, சராசரி |
std. தேவ். |
N |
|
|---|---|---|---|
** அனச்தேசியாவின் மாணவர்கள் ** |
74.53 |
9.00 |
15 |
** பெர்னாடெட்டின் மாணவர்கள் ** |
69.06 |
5.77 |
18 |
இங்கே என்ன நடக்கிறது என்பதற்கான விரிவான உணர்வை உங்களுக்கு வழங்க, நான் இச்டோகிராம்களை (சாமோவியில் அல்ல, ஆனால் ஆர் பயன்படுத்துகிறேன்) இரு ஆசிரியர்களுக்கும் தரங்களின் விநியோகத்தைக் காட்டும் (: எண்: ஃபிக்-ஆர்போஇச்ட்), அத்துடன் ஒரு மாணவர்களின் இரு குழுக்களுக்கான வழிமுறைகள் மற்றும் தொடர்புடைய நம்பிக்கை இடைவெளிகளைக் காட்டும் எளிமையான சூழ்ச்சி (: NumRef: Fig-ttestci).

Fig. 88 அனச்தேசியாவின் (இடது குழு) மற்றும் பெர்னாடெட்டின் (வலது குழு) வகுப்புகளில் மாணவர்களுக்கான தரங்களின் விநியோகத்தைக் காட்டும் இச்டோகிராம்கள். பார்வைக்கு, அனச்தேசியாவின் வகுப்பில் உள்ள மாணவர்கள் சராசரியாக சற்று சிறந்த தரங்களைப் பெறலாம் என்று இவை கூறுகின்றன, இருப்பினும் அவை இன்னும் கொஞ்சம் மாறுபடும்.

Fig. 89 அனச்தேசியா மற்றும் பெர்னாடெட்டின் பயிற்சிகளில் மாணவர்களுக்கான சராசரி தரத்தை அடுக்கு காட்டுகிறது. பிழை பார்கள் சராசரியைச் சுற்றியுள்ள 95 % நம்பிக்கை இடைவெளிகளை சித்தரிக்கின்றன. பார்வைக்கு, குழுக்களிடையே உண்மையான வேறுபாடு இருப்பதாகத் தெரிகிறது, இருப்பினும் நிச்சயமாக சொல்வது கடினம்.
சோதனையை அறிமுகப்படுத்துகிறது
** சுயாதீன மாதிரிகள் டி-டெச்ட் ** மாணவர் மற்றும் வெல்ச் ஆகிய இரண்டு வெவ்வேறு வடிவங்களில் வருகிறது. அசல் மாணவர் *t *-test, இந்த பிரிவில் நான் விவரிக்கும் ஒன்றாகும், இது இரண்டின் எளிமையானது, ஆனால் வெல்ச் *t *-test ஐ விட மிகவும் கட்டுப்படுத்தப்பட்ட அனுமானங்களை நம்பியுள்ளது. நீங்கள் இரு பக்க சோதனையை இயக்க விரும்புகிறீர்கள் என்று கருதி, தரவுகளின் இரண்டு “சுயாதீன மாதிரிகள்” மக்களிடமிருந்து ஒரே சராசரி (பூச்ய கருதுகோள்) அல்லது வெவ்வேறு வழிமுறைகள் (மாற்று கருதுகோள்) கொண்டு வரையப்பட்டுள்ளனவா என்பதை தீர்மானிப்பதே குறிக்கோள். “சுயாதீன” மாதிரிகள் என்று நாங்கள் கூறும்போது, இரண்டு மாதிரிகளில் உள்ள அவதானிப்புகளுக்கு இடையே சிறப்பு உறவு இல்லை என்பதே இங்கே நாம் உண்மையில் அர்த்தப்படுத்துகிறோம். இது இப்போது நிறைய அர்த்தமுள்ளதாக இருக்காது, ஆனால் பின்னர் இணை செய்யப்பட்ட மாதிரிகள் *t *-test பற்றி பேச வரும்போது அது தெளிவாக இருக்கும். இப்போதைக்கு, பங்கேற்பாளர்கள் இரண்டு குழுக்களில் ஒன்றுக்கு தோராயமாக ஒதுக்கப்பட்ட ஒரு சோதனை வடிவமைப்பு எங்களிடம் இருந்தால், இரு குழுக்களின் சராசரி செயல்திறனை சில விளைவு அளவீடுகளில் ஒப்பிட விரும்புகிறோம், பின்னர் ஒரு சுயாதீனமான மாதிரிகள் *t *-சோதனை (ஒரு இணை மாதிரிகள் *t *-test ஐ விட) நாம் பின்னால் இருப்பதுதான்.
சரி, எனவே µ : துணை: 1 குழு 1 (எ.கா., அனச்தேசியாவின் மாணவர்கள்), மற்றும் µ : துணை:` 2` குழு 2 க்கு உண்மையான மக்கள்தொகை சராசரியாக இருக்கும் (எ.கா., பெர்னாடெட்ச் மாணவர்கள்), [#] _ மற்றும் வழக்கம் போல் *x̄ *: துணை: 1 மற்றும் *x̄ *: துணை:` 2` இந்த இரு குழுக்களுக்கும் கவனிக்கப்பட்ட மாதிரி வழிமுறைகளைக் குறிக்கின்றன. எங்கள் சுழிய கருதுகோள் இரண்டு மக்கள்தொகை வழிமுறைகள் ஒரே மாதிரியானவை என்று கூறுகிறது (µ : துணை: 1 = µ : துணை:` 1`) மற்றும் இதற்கு மாற்றாக அவை இல்லை (µ : துணை: 1. µ : துணை: 1). கணித-எசில் எழுதப்பட்ட, இது:

Fig. 90 சுயாதீன மாதிரிகளுக்கான மாணவர் *t *-test எனக் கருதப்படும் சுழிய மற்றும் மாற்று கருதுகோள்களின் வரைகலை விளக்கம். சுழிய கருதுகோள் இரு குழுக்களுக்கும் ஒரே சராசரி இருப்பதாகக் கருதுகிறது, அதேசமயம் மாற்று அவர்களுக்கு வெவ்வேறு வழிமுறைகள் இருப்பதாகக் கருதுகிறது µ : துணை: 1 மற்றும் µ : துணை:` 2`. மக்கள்தொகை வழங்கல் இயல்பானது என்று கருதப்படுவதைக் கவனியுங்கள், மேலும் மாற்று கருதுகோள் குழுவிற்கு வெவ்வேறு வழிகளைக் கொண்டிருக்க அனுமதித்தாலும், அவர்களுக்கு ஒரே நிலையான விலகல் இருப்பதாக கருதுகிறது.
இந்த சூழ்நிலையை கையாளும் ஒரு கருதுகோள் சோதனையை உருவாக்க, சுழிய கருதுகோள் உண்மையாக இருந்தால், மக்கள்தொகைக்கு இடையிலான வேறுபாடு * சரியாக * பூச்சியம், µ : துணை: 1 - µ : துணை:` 1 = 0. இதன் விளைவாக, ஒரு கண்டறியும் சோதனை புள்ளிவிவரம் இரண்டு மாதிரி வழிமுறைகளுக்கு இடையிலான வேறுபாட்டின் அடிப்படையில் இருக்கும். ஏனெனில் சுழிய கருதுகோள் உண்மையாக இருந்தால், *x̄ *: துணை: `1 - x̄ *: துணை:` 2` பூச்சியத்திற்கு *மிகவும் நெருக்கமாக *இருக்க வேண்டும் என்று எதிர்பார்க்கிறோம். எவ்வாறாயினும், எங்கள் ஒரு மாதிரி சோதனைகளுடன் (அதாவது, ஒரு மாதிரி *z *-test மற்றும் ஒரு மாதிரி *t *-test) பார்த்தது போலவே, இந்த வேறுபாட்டை பூச்சியத்திற்கு எவ்வளவு நெருக்கமாக *பற்றி நாம் துல்லியமாக இருக்க வேண்டும் இருக்க வேண்டும். மேலும் பிரச்சினைக்கு தீர்வு அதிகமாகவோ அல்லது குறைவாகவோ ஒரே மாதிரியாக இருக்கும். கடைசி நேரத்தைப் போலவே ஒரு நிலையான பிழை மதிப்பீட்டை (SE) கணக்கிடுகிறோம், பின்னர் இந்த மதிப்பீட்டின் மூலம் வழிமுறைகளுக்கு இடையிலான வேறுபாட்டைப் பிரிக்கிறோம். எனவே எங்கள் * டி-புள்ளிவிவர ** வடிவமாக இருக்கும்:
இந்த நிலையான பிழை மதிப்பீடு உண்மையில் என்ன என்பதை நாம் கண்டுபிடிக்க வேண்டும். இதுவரை நாம் பார்த்த இரண்டு சோதனைகளில் ஒன்றைக் காட்டிலும் இது சற்று தந்திரமானது, எனவே இது எவ்வாறு செயல்படுகிறது என்பதைப் புரிந்துகொள்ள நாம் இன்னும் கவனமாக செல்ல வேண்டும்.
நிலையான விலகலின் "பூல் மதிப்பீடு"
அசல் “மாணவர் t *-test” இல், இரு குழுக்களும் ஒரே மக்கள்தொகை நிலையான விலகலைக் கொண்டுள்ளன என்ற அனுமானத்தை நாங்கள் செய்கிறோம். அதாவது, மக்கள்தொகை என்பது ஒரே மாதிரியானதா என்பதைப் பொருட்படுத்தாமல், மக்கள்தொகை தரமான விலகல்கள் ஒரே மாதிரியானவை என்று நாங்கள் கருதுகிறோம், σ : துணை: `1` = σ : துணை:` 2`. இரண்டு நிலையான விலகல்களும் ஒரே மாதிரியானவை என்று நாங்கள் கருதுவதால், நாங்கள் சந்தாக்களை கைவிட்டு, இரண்டையும் σ எனக் குறிப்பிடுகிறோம். இதை நாம் எவ்வாறு மதிப்பிட வேண்டும்? நம்மிடம் இரண்டு மாதிரிகள் இருக்கும்போது நிலையான விலகலின் ஒற்றை மதிப்பீட்டை எவ்வாறு உருவாக்க வேண்டும்? பதில், அடிப்படையில், நாங்கள் அவற்றை சராசரியாக வைத்திருக்கிறோம். சரி, வகை. உண்மையில், நாம் செய்வது*மாறுபாடு*மதிப்பீடுகளின்*எடையுள்ள*சராசரியை எடுத்துக்கொள்வது, இது மாறுபாட்டின் எங்கள் * பூல் மதிப்பீடாக நாம் பயன்படுத்துகிறோம் **. ஒவ்வொரு மாதிரிக்கும் ஒதுக்கப்பட்ட எடை அந்த மாதிரியில் உள்ள அவதானிப்புகளின் எண்ணிக்கைக்கு சமம், கழித்தல் 1.
கணித ரீதியாக, இதை நாம் எழுதலாம்
இப்போது ஒவ்வொரு மாதிரிக்கும் எடையை ஒதுக்கியுள்ளோம், இரண்டு மாறுபாடு மதிப்பீடுகளின் எடையுள்ள சராசரியை எடுத்துக்கொள்வதன் மூலம் மாறுபாட்டின் பூல் மதிப்பீட்டைக் கணக்கிடுகிறோம், கணிதம்: {தொப்பி சிக்மா_1}^2 மற்றும்: கணிதம்:` {தொப்பி சிக்மா_2}^2`
இறுதியாக, பூல் செய்யப்பட்ட மாறுபாடு மதிப்பீட்டை சதுர வேரை எடுத்துக்கொள்வதன் மூலம் பூல் செய்யப்பட்ட நிலையான விலகல் மதிப்பீட்டாக மாற்றுகிறோம்.
நீங்கள் மனதளவில் w : துணை: 1 = *n *: துணை:` 1` - 1 மற்றும் w : துணை: 2 = *n *: துணை:` 2` - 1 சமன்பாடு நீங்கள் மிகவும் அசிங்கமான தோற்றமுடைய சூத்திரத்தைப் பெறுவீர்கள். பூல் செய்யப்பட்ட நிலையான விலகல் மதிப்பீட்டை விவரிக்கும் "நிலையான" வழியாக உண்மையில் தோன்றும் மிகவும் அசிங்கமான தேற்றம். எவ்வாறாயினும், பூல் செய்யப்பட்ட நிலையான விலகல்களைப் பற்றி சிந்திக்க இது எனக்கு மிகவும் பிடித்த வழி அல்ல. இதைப் பற்றி சிந்திக்க விரும்புகிறேன். எங்கள் தரவு தொகுப்பு உண்மையில் இரண்டு குழுக்களாக வரிசைப்படுத்தப்பட்ட * n * அவதானிப்புகளின் தொகுப்பிற்கு ஒத்திருக்கிறது. ஆகவே, கே-வது டுடோரியல் குழுவில் ஐ-வது மாணவர் பெறப்பட்ட தரத்தைக் குறிக்க *x *: துணை: ik என்ற குறியீட்டைப் பயன்படுத்துவோம். அதாவது, *x *: துணை: 11 என்பது அனச்தேசியாவின் வகுப்பில் முதல் மாணவரால் பெறப்பட்ட தகுதி, *x *: துணை:` 21` அவளுடைய இரண்டாவது மாணவர், மற்றும் பல. எங்களிடம் இரண்டு தனித்தனி குழு உள்ளது *x̄ *: துணை: 1 மற்றும் *x̄ *: துணை:` 2`, இது *x̄ *: sub: k என்ற குறியீட்டைப் பயன்படுத்துவதை“ பொதுவாக ”குறிக்கலாம் , அதாவது, கே-வது டுடோரியல் குழுவின் சராசரி தகுதி. இதுவரை, மிகவும் நல்லது. இப்போது, ஒவ்வொரு மாணவரும் இரண்டு பயிற்சிகளில் ஒன்றில் விழுவதால், குழுவிலிருந்து அவர்களின் விலகலை வித்தியாசமாக விவரிக்கலாம்
எனவே இந்த விலகல்களை மட்டும் ஏன் பயன்படுத்தக்கூடாது (அதாவது, ஒவ்வொரு மாணவரின் தரமும் அவர்களின் டுடோரியலில் சராசரி தரத்திலிருந்து எந்த அளவிற்கு வேறுபடுகிறது)? நினைவில் கொள்ளுங்கள், ஒரு மாறுபாடு என்பது ஒரு சில சதுர விலகல்களின் சராசரியாகும், எனவே அதைச் செய்வோம். கணித ரீதியாக, இதை நாங்கள் இப்படி எழுதலாம்:
“σ : sub:` ik` ”என்ற குறியீடு ஒரு சோம்பேறி வழியாகும்“ எல்லா மாணவர்களையும் அனைத்து பயிற்சிகளிலும் பார்த்து ஒரு தொகையைக் கணக்கிடுங்கள் ”, ஏனெனில் ஒவ்வொரு“ இக் ”ஒரு மாணவருக்கு ஒத்திருக்கிறது. [#] _ ஆனால்,, அத்தியாயத்தில் நாம் பார்த்தது போல: DOC: ../ ch08/ch08_estimation, * n * மூலம் பிரிப்பதன் மூலம் மாறுபாட்டைக் கணக்கிடுவது மக்கள் தொகை மாறுபாட்டின் ஒரு பக்கச்சார்பான மதிப்பீட்டை உருவாக்குகிறது. இதை சரிசெய்ய முன்பு * n * - 1 ஆல் வகுக்க வேண்டியிருந்தது. எவ்வாறாயினும், நான் அந்த நேரத்தில் குறிப்பிட்டுள்ளபடி, இந்த சார்பு இருப்பதற்கான காரணம், மாறுபாடு மதிப்பீடு மாதிரி சராசரியை நம்பியிருப்பதால், மற்றும் மாதிரி சராசரி மக்கள்தொகைக்கு சமம் அல்ல, அதாவது நமது மதிப்பீட்டை முறையாக சார்புடையதாக இருக்கும் மாறுபாடு. ஆனால் இந்த நேரத்தில் நாங்கள் * இரண்டு * மாதிரி வழிமுறைகளை நம்பியிருக்கிறோம்! எங்களுக்கு அதிக சார்பு கிடைத்துள்ளது என்று அர்த்தமா? ஆம், ஆம் அது செய்கிறது. எங்கள் பூல் மாறுபாடு மதிப்பீட்டைக் கணக்கிட, * n * - 1 க்கு பதிலாக * n * - 2 ஆல் இப்போது நாம் வகுக்க வேண்டுமா? ஏன், ஆம்
ஓ, நீங்கள் இதன் சதுர மூலத்தை எடுத்துக் கொண்டால், நீங்கள் பெறுவீர்கள்: கணிதம்: தொப்பி {சிக்மா} _p, பூல் செய்யப்பட்ட நிலையான விலகல் மதிப்பீடு. வேறு வார்த்தைகளில் கூறுவதானால், பூல் செய்யப்பட்ட நிலையான விலகல் கணக்கீடு எதுவும் சிறப்பு இல்லை. இது வழக்கமான நிலையான விலகல் கணக்கீட்டிற்கு மிகவும் வேறுபட்டதல்ல.
சோதனையை நிறைவு செய்தல்
நீங்கள் எந்த வழியைப் பற்றி சிந்திக்க விரும்புகிறீர்கள் என்பதைப் பொருட்படுத்தாமல், இப்போது நிலையான விலகல் குறித்த எங்கள் பூல் மதிப்பீடு உள்ளது. இனிமேல், நான் வேடிக்கையான * பி * சந்தா கைவிடுவேன், இந்த மதிப்பீட்டை இவ்வாறு குறிப்பிடுகிறேன்: கணிதம்: தொப்பி சிக்மா. பெரிய. இரத்தக்களரி கருதுகோள் சோதனையைப் பற்றி சிந்திக்க இப்போது செல்லலாம், இல்லையா? இந்த பூல் மதிப்பீட்டைக் கணக்கிடுவதற்கான எங்கள் முழு காரணமும் என்னவென்றால், எங்கள் * நிலையான பிழை * மதிப்பீட்டைக் கணக்கிடும்போது அது உதவியாக இருக்கும் என்று எங்களுக்குத் தெரியும். ஆனால் என்ன *இன் நிலையான பிழை? ஒரு மாதிரி *t *-test இல் இது மாதிரி சராசரி, சே (x̄), மற்றும் அதற்குப் பிறகு: கணிதம்: `Se (x̄) = sigma / sqrt {N}` எங்கள் *டி *-ச்டாடிச்டிக் போல் இருந்தது. எவ்வாறாயினும், இந்த நேரத்தில், எங்களிடம் * இரண்டு * மாதிரி வழிமுறைகள் உள்ளன. நாங்கள் ஆர்வமாக இருப்பது, குறிப்பாக, இரண்டு *x̄ *: துணை: `1` - *x̄ *: துணை:` 2` ஆகியவற்றுக்கு இடையேயான வேறுபாடு. இதன் விளைவாக, நாம் பிரிக்க வேண்டிய நிலையான பிழை உண்மையில் வேறுபாட்டின் * நிலையான பிழை ** வழிமுறைகளுக்கு இடையிலான **.
இரண்டு மாறிகள் உண்மையில் ஒரே நிலையான விலகலைக் கொண்டிருக்கும் வரை, நிலையான பிழைக்கான எங்கள் மதிப்பீடு
எனவே எங்கள் *டி *-ச்டாடிச்டிக் எனவே
எங்கள் ஒரு மாதிரி சோதனையுடன் நாம் பார்த்தது போலவே, இந்த t *-statistict இன் மாதிரி வழங்கல் ஒரு *t *-distribution (அதிர்ச்சியூட்டும், இல்லையா?) சுழிய கருதுகோள் உண்மையாக இருக்கும் வரை மற்றும் அனைத்து அனுமானங்களும் சோதனை நிறைவு செய்யப்படுகிறது. இருப்பினும், சுதந்திரத்தின் அளவுகள் சற்று வித்தியாசமானது. வழக்கம் போல், தரவு புள்ளிகளின் எண்ணிக்கைக்கு சமமாக இருக்க சுதந்திரத்தின் அளவைப் பற்றி நாம் சிந்திக்கலாம். இந்த வழக்கில், எங்களிடம்*n*அவதானிப்புகள் (*n: துணை: 1 மாதிரி 1 இல், மற்றும்*n*: மாதிரி 2 இல்` 2`), மற்றும் 2 தடைகள் (மாதிரி பொருள்) உள்ளன. எனவே இந்த சோதனைக்கான மொத்த சுதந்திரங்கள் * n * - 2 ஆகும்.
Doing the test in jamovi
ஆச்சரியப்படுவதற்கில்லை, நீங்கள் சாமோவியில் ஒரு சுயாதீனமான மாதிரிகளை *t *-டெச்டை எளிதாக இயக்க முடியும். எங்கள் சோதனைக்கான விளைவு மாறி மாணவர் `` கிரேடு`` ஆகும், மேலும் ஒவ்வொரு வகுப்பிற்கும் `` ஆசிரியர்`` அடிப்படையில் குழுக்கள் வரையறுக்கப்படுகின்றன. ஆகவே, சாமோவியில் நீங்கள் செய்ய வேண்டியதெல்லாம் தொடர்புடைய பகுப்பாய்விற்குச் செல்வது (`` அனலீச்`` → டி-சோதனைகள்`` `` சுயாதீன மாதிரிகள் டி-டெச்ட்``) `` கிரேடு`` மாறுபடும் `` சார்பு மாறிகள்` பெட்டியில், மற்றும் `` ஆசிரியர்`` மாறுபடும் `` குழுமம் மாறி`` பெட்டியில், இதில் காட்டப்பட்டுள்ளபடி: NumRef: Fig-ttest_ind.
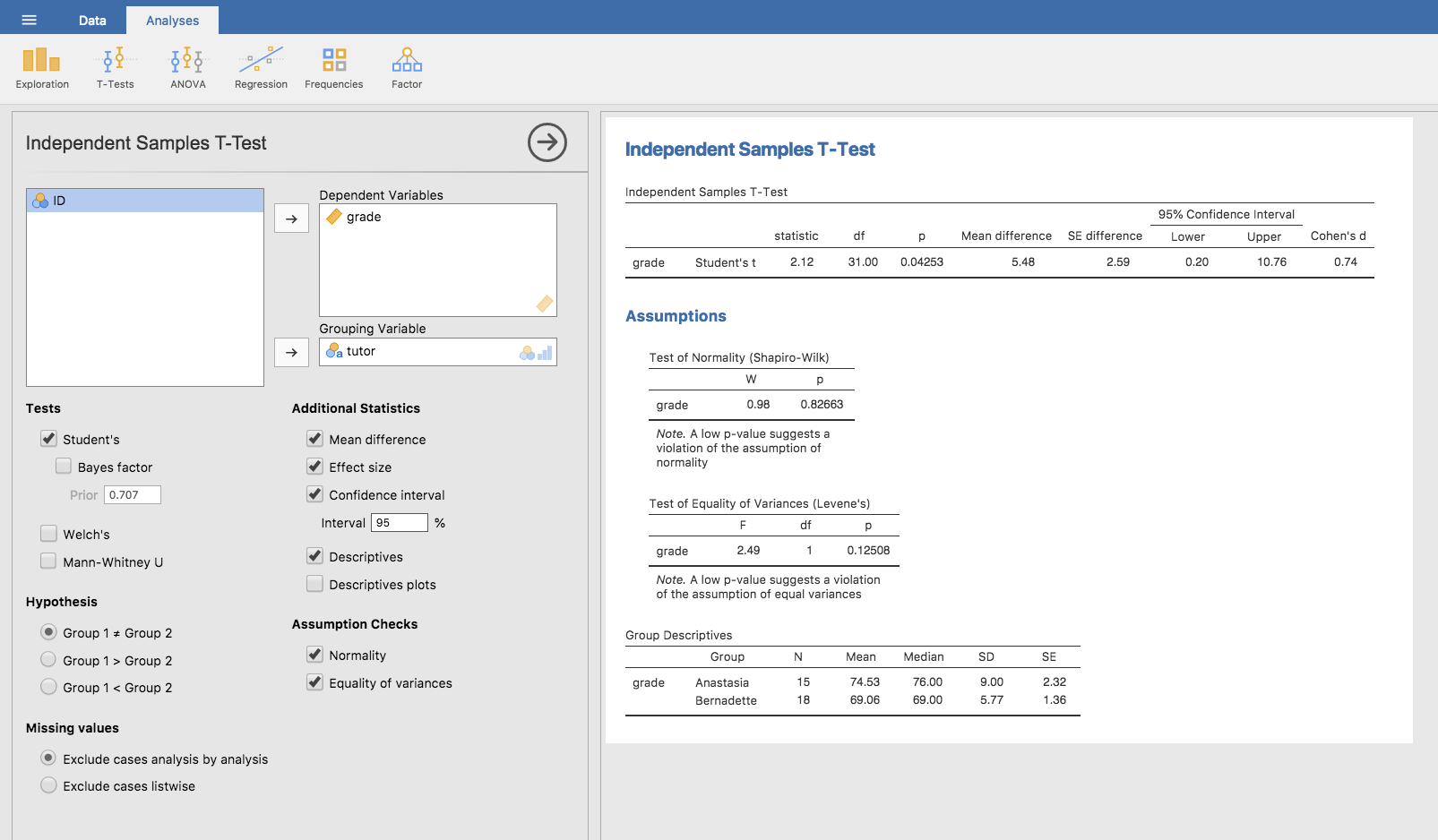
Fig. 91 பரிந்துரைக்கப்பட்ட வெளியீடுகளுக்கான விருப்பங்களுடன், சாமோவியில் ஒரு சுயாதீனமான மாதிரிகள் *t *-test ஐ நடத்துதல்.
வெளியீடு மிகவும் பழக்கமான வடிவத்தைக் கொண்டுள்ளது. முதலில், என்ன சோதனை இயக்கப்பட்டது என்பதை இது உங்களுக்குக் கூறுகிறது, மேலும் நீங்கள் பயன்படுத்திய சார்பு மாறியின் பெயரை இது சொல்கிறது. அது சோதனை முடிவுகளைப் புகாரளிக்கிறது. கடைசியாக சோதனை முடிவுகள் ஒரு *t *-ச்டாட்டிச்டிக், சுதந்திரத்தின் அளவுகள் மற்றும் *p *-மதிப்பு ஆகியவற்றைக் கொண்டிருக்கின்றன. இறுதிப் பிரிவு இரண்டு விசயங்களைப் புகாரளிக்கிறது: இது உங்களுக்கு நம்பிக்கை இடைவெளியையும் விளைவு அளவையும் தருகிறது. விளைவு அளவுகளைப் பற்றி பின்னர் பேசுவேன். நம்பிக்கை இடைவெளி, இருப்பினும், நான் இப்போது பேச வேண்டும்.
இந்த நம்பிக்கை இடைவெளி உண்மையில் எதைக் குறிக்கிறது என்பதில் தெளிவாக இருப்பது மிகவும் முதன்மை. குழு வழிமுறைகளுக்கு இடையிலான * வேறுபாட்டிற்கான நம்பிக்கை இடைவெளி இது. எங்கள் எடுத்துக்காட்டில், அனச்தேசியாவின் மாணவர்கள் சராசரியாக 74.53 தரத்தைக் கொண்டிருந்தனர், மேலும் பெர்னாடெட்டின் மாணவர்கள் சராசரியாக 69.06 தரத்தைக் கொண்டிருந்தனர், எனவே இரண்டு மாதிரி வழிமுறைகளுக்கு இடையிலான வேறுபாடு 5.48 ஆகும். ஆனால் நிச்சயமாக மக்கள்தொகைக்கு இடையிலான வேறுபாடு இதை விட பெரியதாகவோ அல்லது சிறியதாகவோ இருக்கலாம். நம்பிக்கை இடைவெளி இதில் தெரிவிக்கப்பட்டுள்ளது: NumRef: Fig-ttest_ind இந்த ஆய்வை நாங்கள் மீண்டும் மீண்டும் பிரதிபலித்தால், 95 % நேரத்தின் உண்மையான வேறுபாடு 0.20 முதல் 10.76 வரை இருக்கும் என்று உங்களுக்குச் சொல்கிறது. திரும்பிப் பாருங்கள்: DOC: ../ ch08/ch08_estimation_5 நம்பிக்கை இடைவெளிகள் என்ன என்பது பற்றிய நினைவூட்டலுக்கு.
எவ்வாறாயினும், இரு குழுக்களுக்கும் இடையிலான வேறுபாடு குறிப்பிடத்தக்கது (வெறும் வெறும்), எனவே இது போன்ற உரையைப் பயன்படுத்தி முடிவை எழுதலாம்:
அனச்தேசியாவின் வகுப்பில் சராசரி தகுதி 74.5 % (எச்.டி.டி தேவ் = 9.0), அதேசமயம் பெர்னாடெட்டின் வகுப்பில் சராசரி 69.1 % (எச்.டி.டி தேவ் = 5.8). ஒரு மாணவரின் சுயாதீனமான மாதிரிகள்*t*-test இந்த 5.4 % வேறுபாடு குறிப்பிடத்தக்கதாக இருப்பதைக் காட்டியது (t(31) = 2.1,*p*<0.05, தொஒ : துணை: 95 = [0.2, 10.8]` , * டி * = 0.74), கற்றல் விளைவுகளில் உண்மையான வேறுபாடு ஏற்பட்டுள்ளது என்று பரிந்துரைக்கிறது.
ச்டேட் பிளாக்கில் நம்பிக்கை இடைவெளி மற்றும் விளைவு அளவு ஆகியவற்றை நான் சேர்த்துள்ளேன் என்பதைக் கவனியுங்கள். மக்கள் எப்போதும் இதைச் செய்ய மாட்டார்கள். குறைந்தபட்சம், *t *-statistic, சுதந்திரத்தின் அளவுகள் மற்றும் *p *-value ஐப் பார்க்க எதிர்பார்க்கிறீர்கள். எனவே இதுபோன்ற ஒன்றை நீங்கள் குறைந்தபட்சம் சேர்க்க வேண்டும்: *t *(31) = 2.1, *ப *<0.05. புள்ளிவிவர வல்லுநர்கள் தங்கள் வழியைக் கொண்டிருந்தால், எல்லோரும் நம்பிக்கை இடைவெளியையும், விளைவு அளவு அளவையும் தெரிவிப்பார்கள், ஏனென்றால் அவை தெரிந்து கொள்ள பயனுள்ள விசயங்கள். ஆனால் நிச வாழ்க்கை எப்போதுமே புள்ளிவிவர வல்லுநர்கள் விரும்பும் விதத்தில் செயல்படாது, எனவே இது உங்கள் வாசகர்களுக்கு உதவும் என்று நீங்கள் நினைக்கிறீர்களா என்பதையும், நீங்கள் ஒரு விஞ்ஞான தாளை எழுதுகிறீர்கள் என்றால், கேள்விக்குரிய பத்திரிகைக்கான தலையங்கத் தரத்தையும் நீங்கள் தீர்ப்பளிக்க வேண்டும். சில பத்திரிகைகள் நீங்கள் விளைவு அளவுகளைப் புகாரளிக்க வேண்டும் என்று எதிர்பார்க்கிறார்கள், மற்றவர்கள் இல்லை. சில அறிவியல் சமூகங்களுக்குள் நம்பிக்கை இடைவெளிகளைப் புகாரளிப்பது நிலையான நடைமுறையாகும், மற்றவற்றில் அது இல்லை. உங்கள் பார்வையாளர்கள் என்ன எதிர்பார்க்கிறார்கள் என்பதை நீங்கள் கண்டுபிடிக்க வேண்டும். ஆனால், தெளிவுக்காக, நீங்கள் எனது வகுப்பை எடுத்துக் கொண்டால், எனது இயல்புநிலை நிலை என்னவென்றால், இது வழக்கமாக விளைவு அளவு மற்றும் நம்பிக்கை இடைவெளி இரண்டையும் உள்ளடக்கியது.
நேர்மறை மற்றும் எதிர்மறை *t *-மதிப்புகள்
*T *-test இன் அனுமானங்களைப் பற்றி பேசுவதற்கு முன், நடைமுறையில் *t *-tests ஐப் பயன்படுத்துவது குறித்து நான் செய்ய விரும்பும் ஒரு கூடுதல் புள்ளி உள்ளது. முதலாவது *t *-statistic இன் அடையாளத்துடன் தொடர்புடையது (அதாவது, இது நேர்மறை எண் அல்லது எதிர்மறையானதாக இருந்தாலும்). மாணவர்கள் தங்கள் முதல் *டி *டெச்டை இயக்கத் தொடங்கும் போது அவர்கள் கொண்டிருக்கும் ஒரு பொதுவான கவலை என்னவென்றால், அவர்கள் பெரும்பாலும் *டி *-ச்டாடிச்டிக் எதிர்மறையான மதிப்புகளுடன் முடிவடையும், அதை எவ்வாறு விளக்குவது என்று தெரியவில்லை. உண்மையில், ஒரு நபருக்கு எதிர்மறையான *t *-மதிப்புகள் உள்ளன, மற்றொன்று நேர்மறையான *t *-மதிப்பு ஆகியவற்றைக் கொண்டிருப்பதைத் தவிர, இரண்டு நபர்கள் சுயாதீனமாக வேலை செய்வது கிட்டத்தட்ட ஒரே மாதிரியான முடிவுகளுடன் முடிவடைவது அசாதாரணமானது அல்ல. நீங்கள் இரு பக்க சோதனையை இயக்குகிறீர்கள் என்று கருதி, *பி *-மதிப்புகள் ஒரே மாதிரியாக இருக்கும். நெருக்கமான பரிசோதனையில், நம்பிக்கை இடைவெளிகளிலும் எதிர் அறிகுறிகள் இருப்பதை மாணவர்கள் கவனிப்பார்கள். இது சரியாக இருக்கிறது. இது நிகழும் போதெல்லாம், நீங்கள் கண்டுபிடிப்பது என்னவென்றால், முடிவுகளின் இரண்டு பதிப்புகள் *t *-test ஐ இயக்குவதற்கான சற்று மாறுபட்ட வழிகளிலிருந்து எழுகின்றன. இங்கே என்ன நடக்கிறது என்பது மிகவும் எளிது. இங்கே நாம் கணக்கிடும் *t *-பயன்பாடு எப்போதும் வடிவத்தில் இருக்கும்
“சராசரி 1” “சராசரி 2” ஐ விட பெரியதாக இருந்தால், *t *-ச்டாட்டிச்டிக் நேர்மறையாக இருக்கும், அதேசமயம் “சராசரி 2” பெரியதாக இருந்தால் *t *-statistict எதிர்மறையாக இருக்கும். இதேபோல், சாமோவி புகாரளிக்கும் நம்பிக்கை இடைவெளி என்பது வித்தியாசத்திற்கான நம்பிக்கை இடைவெளி “(சராசரி 1) கழித்தல் (சராசரி 2)”, இது வித்தியாசத்திற்கான நம்பிக்கை இடைவெளியைக் கணக்கிட்டால் நீங்கள் பெறும் விசயத்தின் தலைகீழ் ஆகும் “( சராசரி 2) கழித்தல் (சராசரி 1) ”.
சரி, நீங்கள் அதைப் பற்றி நினைக்கும் போது இது மிகவும் நேரடியானது, ஆனால் இப்போது அனச்தேசியாவின் வகுப்பை பெர்னாடெட்டின் வகுப்போடு ஒப்பிடுகையில் எங்கள் *டி *-டெச்டைக் கவனியுங்கள். எது நாம் “சராசரி 1” என்று அழைக்க வேண்டும், எதை “சராசரி 2” என்று அழைக்க வேண்டும். இது தன்னிச்சையானது. இருப்பினும், அவற்றில் ஒன்றை நீங்கள் “சராசரி 1” என்றும் மற்றொன்று “சராசரி 2” என்றும் நியமிக்க வேண்டும். சமோவி இதைக் கையாளும் முறையும் மிகவும் தன்னிச்சையானது என்பதில் ஆச்சரியமில்லை. புத்தகத்தின் முந்தைய பதிப்புகளில் நான் அதை விளக்க முயற்சித்தேன், ஆனால் சிறிது நேரம் கழித்து நான் கைவிட்டேன், ஏனென்றால் இது உண்மையில் அவ்வளவு முக்கியமானதல்ல, நேர்மையாக இருக்க வேண்டும், நான் என்னை ஒருபோதும் நினைவில் கொள்ள முடியாது. நான் ஒரு குறிப்பிடத்தக்க *டி *-டெச்ட் முடிவைப் பெறும்போதெல்லாம், இதன் பொருள் பெரியது என்பதைக் கண்டுபிடிக்க விரும்புகிறேன், *t *-statistic ஐப் பார்ப்பதன் மூலம் நான் அதைக் கண்டுபிடிக்க முயற்சிக்கவில்லை. அதைச் செய்வதை நான் ஏன் கவலைப்படுவேன்? இது முட்டாள்தனம். சாமோவி வெளியீடு உண்மையில் அவற்றைக் காண்பிப்பதால் உண்மையான குழுவைப் பார்ப்பது எளிதானது!
இங்கே முக்கியமான சேதி. சமோவி உங்களுக்குக் காண்பிப்பதில் உண்மையில் பரவாயில்லை என்பதால், நான் வழக்கமாக *t *-statistist ஐ *புகாரளிக்க முயற்சிக்கிறேன், இது எண்கள் உரையுடன் பொருந்தும். எனது அறிக்கையில் நான் எழுத விரும்புவது “அனச்தேசியாவின் வகுப்பு பெர்னாடெட்டின் வகுப்பை விட அதிக தரங்களைக் கொண்டிருந்தது” என்று வைத்துக்கொள்வோம். இங்கே சொற்றொடர் என்பது அனச்தேசியாவின் குழு முதலில் வருகிறது என்பதைக் குறிக்கிறது, எனவே *t *-statistice அனச்தேசியாவின் வகுப்பு குழு 1 உடன் ஒத்துப்போகும். அப்படியானால், நான் எழுதுவேன்
(நிச வாழ்க்கையில் “உயர்ந்தது” என்ற வார்த்தையை நான் உண்மையில் அடிக்கோடிட்டுக் காட்ட மாட்டேன், “உயர்ந்தது” நேர்மறையான *t *-values க்கு ஒத்திருக்கிறது என்ற புள்ளியை வலியுறுத்துவதற்காக நான் அதைச் செய்கிறேன்). மறுபுறம், நான் பயன்படுத்த விரும்பிய சொற்றொடருக்கு பெர்னாடெட்டின் வகுப்பு முதலில் பட்டியலிடப்பட்டுள்ளது என்று வைத்துக்கொள்வோம். அப்படியானால், அவளுடைய வகுப்பை குழு 1 என்று கருதுவது கூடுதல் அர்த்தமுள்ளதாக இருக்கிறது, அப்படியானால், எழுதுவது இப்படி தெரிகிறது:
இந்த நேரத்தில் “குறைந்த” மதிப்பெண்களைக் கொண்ட ஒரு குழுவைப் பற்றி நான் பேசுவதால், *t *-statistic இன் எதிர்மறை வடிவத்தைப் பயன்படுத்துவது மிகவும் விவேகமானதாகும். இது இன்னும் சுத்தமாக வாசிக்க வைக்கிறது.
கடைசி விசயம்: மற்ற வகை சோதனை புள்ளிவிவரங்களுக்காக இதை நீங்கள் செய்ய முடியாது என்பதை நினைவில் கொள்க. இது *t *-tests க்கு வேலை செய்கிறது, ஆனால் இது χ²-சோதனைகள், *f *-tests அல்லது உண்மையில் இந்த புத்தகத்தில் நான் பேசும் பெரும்பாலான சோதனைகளுக்கு அர்த்தமுள்ளதாக இருக்காது. எனவே இந்த ஆலோசனையை அதிகமாக உருவாக்க வேண்டாம்! நான் இங்கே *t *-tets பற்றி பேசுகிறேன், வேறு எதுவும் இல்லை!
மாணவரின் அனுமானங்கள் *t *-test
எப்போதும் போல, எங்கள் கருதுகோள் சோதனை சில அனுமானங்களை நம்பியுள்ளது. எனவே அவை என்ன? மாணவருக்கு *t *-test மூன்று அனுமானங்கள் உள்ளன, அவற்றில் சில முன்னர் ஒரு மாதிரியின் சூழலில் *t *-test (பிரிவு பார்க்கவும்: குறிப்பு: `ஒரு மாதிரியின் அனுமானங்கள் *t *-test <anumptions_one_sample_t_test > `):
இயல்புநிலை. ஒரு மாதிரி *t *-test ஐப் போலவே, தரவு பொதுவாக விநியோகிக்கப்படும் என்று கருதப்படுகிறது. குறிப்பாக, இரு குழுக்களும் பொதுவாக விநியோகிக்கப்படுகின்றன என்று நாங்கள் கருதுகிறோம். பிரிவில்: DOC: Ch11_ttest_08, இயல்பான தன்மையை எவ்வாறு சோதிப்பது என்பதை நாங்கள் விவாதிப்போம், மேலும் பிரிவில்: DOC:` CH11_TTEST_09` சாத்தியமான தீர்வுகளைப் பற்றி விவாதிப்போம்.
சுதந்திரம். மீண்டும், அவதானிப்புகள் சுயாதீனமாக மாதிரியாக இருப்பதாக கருதப்படுகிறது. மாணவர் சோதனையின் சூழலில் இதற்கு இரண்டு நற்பொருத்தங்கள் உள்ளன. முதலாவதாக, ஒவ்வொரு மாதிரியிலும் உள்ள அவதானிப்புகள் ஒருவருக்கொருவர் சுயாதீனமானவை என்று நாங்கள் கருதுகிறோம் (ஒரு மாதிரி சோதனைக்கு சமம்). இருப்பினும், குறுக்கு மாதிரி சார்புகள் இல்லை என்றும் நாங்கள் கருதுகிறோம். உதாரணமாக, உங்கள் ஆய்வின் இரண்டு சோதனை நிபந்தனைகளிலும் நீங்கள் சில பங்கேற்பாளர்களைச் சேர்த்தால் (எ.கா., தற்செயலாக ஒரே நபரை வெவ்வேறு நிபந்தனைகளுக்கு பதிவுபெற அனுமதிப்பதன் மூலம்), நீங்கள் தேவையான சில குறுக்கு மாதிரி சார்புகள் உள்ளன கணக்கில் எடுத்துக் கொள்ளுங்கள்.
Homogeneity of variance (also called “homoscedasticity”). The third assumption is that the population standard deviation is the same in both groups. You can test this assumption using the Levene test, which I’ll talk about later on in the book (section Checking the homogeneity of variance assumption). However, there’s a very simple remedy for this assumption if you are worried, which I’ll talk about in the next section.